This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our platform isn't just about workflow automation – we're creating the data layer that continuously monitors, evaluates, and improves AI systems across multimodal interactions.” Automate optimizations using built-in scoring mechanisms. Experiment with agentic workflows without writing code.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
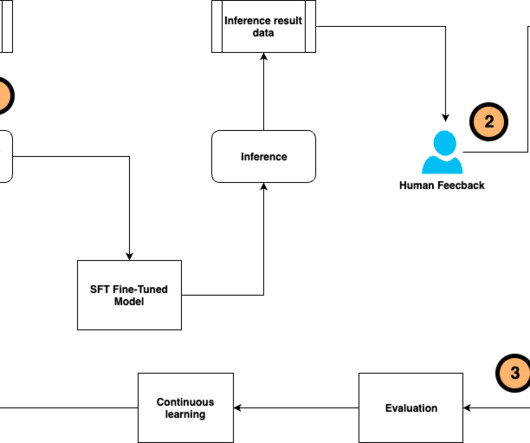
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
In 2025, artificial intelligence isnt just trendingits transforming how engineering teams build, ship, and scale software. Whether its automating code, enhancing decision-making, or building intelligent applications, AI is rewriting what it means to be a modern engineer. Analytical thinking and problem-solving remain essential.
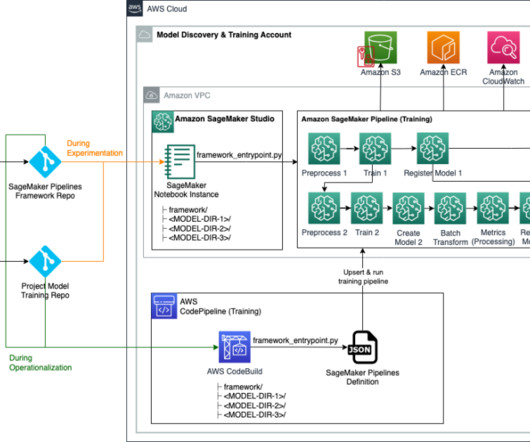
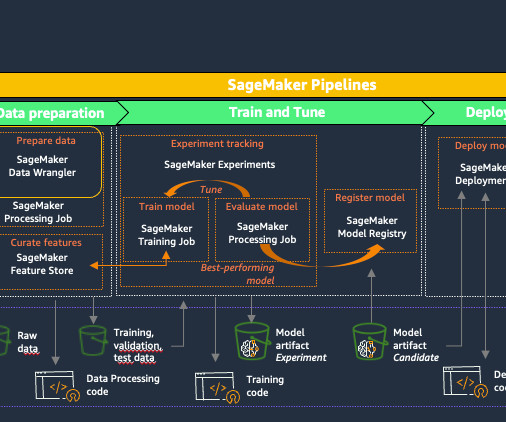
Creating scalable and efficient machine learning (ML) pipelines is crucial for streamlining the development, deployment, and management of ML models. In this post, we present a framework for automating the creation of a directed acyclic graph (DAG) for Amazon SageMaker Pipelines based on simple configuration files.
However, if we can capture SME domain knowledge in the form of well-defined acceptance criteria, and scale it via automated, specialized evaluators, we can accelerate evaluation exponentially from several weeks or more to a few hours or less. Lets consider an LLM-as-a-Judge (LLMAJ) which checks to see if an AI assistant has repeated itself.
Adaptive RAG Systems with Knowledge Graphs: Building Smarter LLM Pipelines David vonThenen, Senior AI/MLEngineer at DigitalOcean Unlock the full potential of Retrieval-Augmented Generation by embedding adaptive reasoning with knowledge graphs.
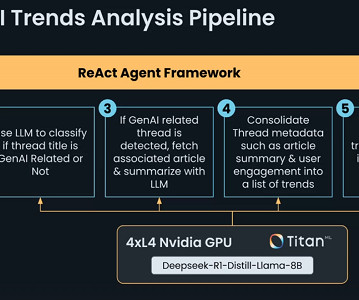
The AI agent classified and summarized GenAI-related content from Reddit, using a structured pipeline with utility functions for API interactions, web scraping, and LLM-based reasoning. He also demonstrated workflow automation using Koo.ai, highlighting how AI-driven knowledge extraction can enhance research dissemination.
Clean up To clean up the model and endpoint, use the following code: predictor.delete_model() predictor.delete_endpoint() Conclusion In this post, we explored how SageMaker JumpStart empowers data scientists and MLengineers to discover, access, and run a wide range of pre-trained FMs for inference, including the Falcon 3 family of models.
It accelerates your generative AI journey from prototype to production because you don’t need to learn about specialized workflow frameworks to automate model development or notebook execution at scale. Create a complete AI/ML pipeline for fine-tuning an LLM using drag-and-drop functionality.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. Along with protecting against toxicity and harmful content, it can also be used for Automated Reasoning checks , which helps you protect against hallucinations.
Attackers may attempt to fine-tune surrogate models using queries to the target LLM to reverse-engineer its knowledge. Adversaries can also attempt to breach cloud environments hosting LLMs to sabotage operations or exfiltrate data. Stolen models also create additional attack surface for adversaries to mount further attacks.
We formulated a text-to-SQL approach where by a user’s natural language query is converted to a SQL statement using an LLM. This data is again provided to an LLM, which is asked to answer the user’s query given the data. The relevant information is then provided to the LLM for final response generation.
Sergio Ferragut, Principal Developer Advocate at Tecton, will show how to enhance collaboration, automate feature materialization, and support diverse data types. He will also cover how these frameworks automate production-ready pipelines, speeding up AI projects and making AI-powered applications more intelligent.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. MLOps engineers are responsible for providing a secure environment for data scientists and MLengineers to productionize the ML use cases.
About Building LLMs for Production Generative AI and LLMs are transforming industries with their ability to understand and generate human-like text and images. However, building reliable and scalable LLM applications requires a lot of extra work and a deep understanding of various techniques and frameworks.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system.
This allows you to create rules that invoke specific actions when certain events occur, enhancing the automation and responsiveness of your observability setup (for more details, see Monitor Amazon Bedrock ). The job could be automated based on a ground truth, or you could use humans to bring in expertise on the matter.
However, if we can capture SME domain knowledge in the form of well-defined acceptance criteria, and scale it via automated, specialized evaluators, we can accelerate evaluation exponentially from several weeks or more to a few hours or less. Lets consider an LLM-as-a-Judge (LLMAJ) which checks to see if an AI assistant has repeated itself.
The solution in this post shows how you can take Python code that was written to preprocess, fine-tune, and test a large language model (LLM) using Amazon Bedrock APIs and convert it into a SageMaker pipeline to improve ML operational efficiency. Add @step decorated functions to convert the Python code to a SageMaker pipeline.
The practical implementation of a Large Language Model (LLM) for a bespoke application is currently difficult for the majority of individuals. It takes a lot of time and expertise to create an LLM that can generate content with high accuracy and speed for specialized domains or, perhaps, to imitate a writing style.
The efficiencies were double-edged: Automating one process might overwhelm downstream processes that were still done by hand. Bringing AI into a company means you have new roles to fill (data scientist, MLengineer) as well as new knowledge to backfill in existing roles (product, ops). So what is software dev-flavored AI?
🔎 ML Research RL for Open Ended LLM Conversations Google Research published a paper detailing dynamic planning, a reinforcement learning(RL) based technique to guide open ended conversations. Self-Aligned LLM IBM Research published a paper introducing Dromedary, a self-aligned LLM trained with minimum user supervision.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. They should also offer version control capabilities to manage the changes and revisions of ML artifacts, ensuring reproducibility and facilitating effective teamwork.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons.
Generative AI TrackBuild the Future with GenAI Generative AI has captured the worlds attention with tools like ChatGPT, DALL-E, and Stable Diffusion revolutionizing how we create content and automate tasks. AI Engineering TrackBuild Scalable AISystems Learn how to bridge the gap between AI development and software engineering.
Amazon SageMaker Clarify now provides AWS customers with foundation model (FM) evaluations, a set of capabilities designed to evaluate and compare model quality and responsibility metrics for any LLM, in minutes. FMEval helps in measuring evaluation dimensions such as accuracy, robustness, bias, toxicity, and factual knowledge for any LLM.
Customers increasingly want to use deep learning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machine learning (ML) may contain personally identifiable information (PII).
The introduction of generative AI provides another opportunity for Thomson Reuters to work with customers and once again advance how they do their work, helping professionals draw insights and automate workflows, enabling them to focus their time where it matters most.
📌 MLEngineering Event: Join Meta, PepsiCo, RiotGames, Uber & more at apply(ops) apply(ops) is in two days! SAVE MY SPOT 🔎 ML Research LLM Pruning Microsoft Research published a research paper proposing LoRAShear, a technique for pruning and recovering knowledge in LLMs. million in funding.
You probably don’t need MLengineers In the last two years, the technical sophistication needed to build with AI has dropped dramatically. MLengineers used to be crucial to AI projects because you needed to train custom models from scratch. At the same time, the capabilities of AI models have grown.
Services : AI Solution Development, MLEngineering, Data Science Consulting, NLP, AI Model Development, AI Strategic Consulting, Computer Vision. Generative AI integration service : proposes to train Generative AI on clients data and add new features to products.
TL;DR Finding an optimal set of hyperparameters is essential for efficient and effective training of Large Language Models (LLMs). The key LLM hyperparameters influence the model size, learning rate, learning behavior, and token generation process. Hyperparameters set and tuned during pre-training influence the total size of an LLM.
Automation is critical, with techniques like pre-trained models, active learning, or weak supervision methods. Feature Engineering and Model Experimentation MLOps: Involves improving ML performance through experiments and feature engineering.
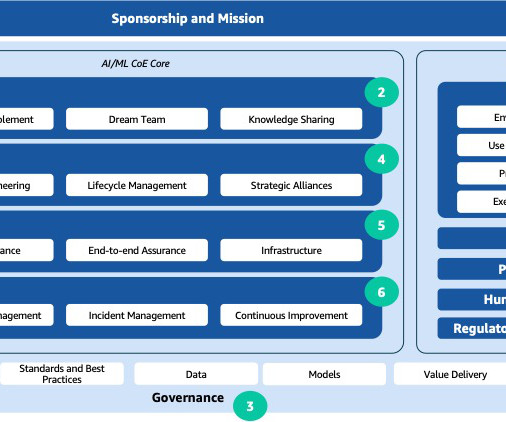
Lifecycle management Within the AI/ML CoE, the emphasis on scalability, availability, reliability, performance, and resilience is fundamental to the success and adaptability of AI/ML initiatives. This includes implementation of industry best practice measures and industry frameworks, such as NIST , OWASP-LLM , OWASP-ML , MITRE Atlas.
By the end of the session, attendees will know how to transform unstructured data into reliable, queryable formats, optimize LLM outputs for cost-effective analysis, and apply structured data to answer natural-language queries. Cloning NotebookLM with Open Weights Models Niels Bantilan, Chief MLEngineer atUnion.AI
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content. Register now.
Artificial intelligence (AI) and machine learning (ML) models have shown great promise in addressing these challenges. By automating the summarization process, doctors can quickly gain access to relevant information, allowing them to focus on patient care and make more informed decisions. No MLengineering experience required.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content. Register now.
Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain. These models will help automate manual processes and improve insurance companies’ abilities to find the right buyers for the right products.
Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain. These models will help automate manual processes and improve insurance companies’ abilities to find the right buyers for the right products.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content.
Currently, I am working on Large Language Model (LLM) based autonomous agents. Alexandre Bayen, Fangyu focuses on the application of optimization methods to multi-agent robotic systems, particularly in the planning and control of automated vehicles.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content