This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The invoked Lambda function creates new job entries in a DynamoDB table with the status as Pending.
OpenAI is joining the Coalition for Content Provenance and Authenticity (C2PA) steering committee and will integrate the open standard’s metadata into its generative AI models to increase transparency around generated content. Check out AI & Big Data Expo taking place in Amsterdam, California, and London.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. Generate metadata for the page.
Cisco’s 2024 Data Privacy Benchmark Study revealed that 48% of employees admit to entering non-public company information into GenAI tools (and an unknown number have done so and won’t admit it), leading 27% of organisations to ban the use of such tools. The best way to reduce the risks is to limit access to sensitive data.
The results are shown in a Streamlit app, with the invoices and extracted information displayed side-by-side for quick review. After uploading, you can set up a regular batch job to process these invoices, extract key information, and save the results in a JSON file. Importantly, your document and data are not stored after processing.
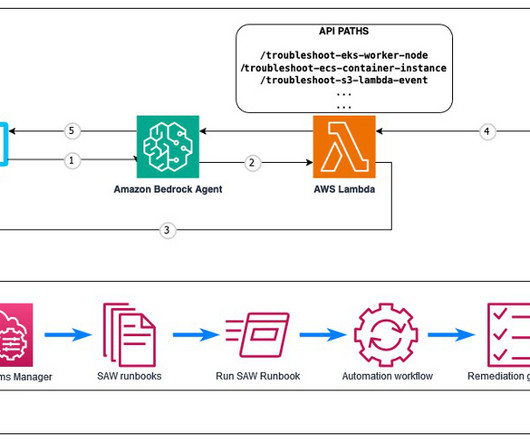
Fortunately, AWS provides a powerful tool called AWS Support Automation Workflows , which is a collection of curated AWS Systems Manager self-service automation runbooks. It processes natural language queries to understand the issue context and manages conversation flow to gather required information.
It simplifies the creation and management of AI automations using either AI flows, multi-agent systems, or a combination of both, enabling agents to work together seamlessly, tackling complex tasks through collaborative intelligence. At a high level, CrewAI creates two main ways to create agentic automations: flows and crews.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata. Even defining it back then was a tough task.
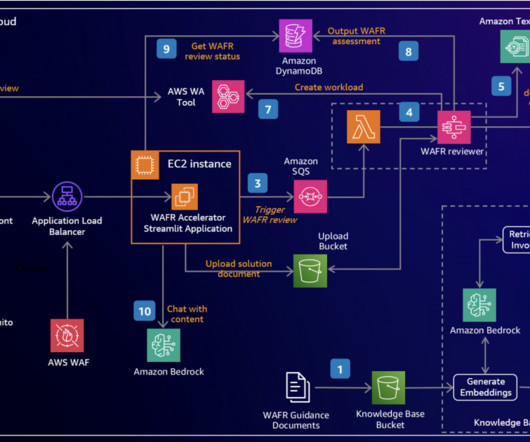
This solution automates portions of the WAFR report creation, helping solutions architects improve the efficiency and thoroughness of architectural assessments while supporting their decision-making process. Integration with the AWS Well-Architected Tool pre-populates workload information and initial assessment responses.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Furthermore, it might contain sensitive data or personally identifiable information (PII) requiring redaction.
Knowledge bases effectively bridge the gap between the broad knowledge encapsulated within foundation models and the specialized, domain-specific information that businesses possess, enabling a truly customized and valuable generative artificial intelligence (AI) experience.
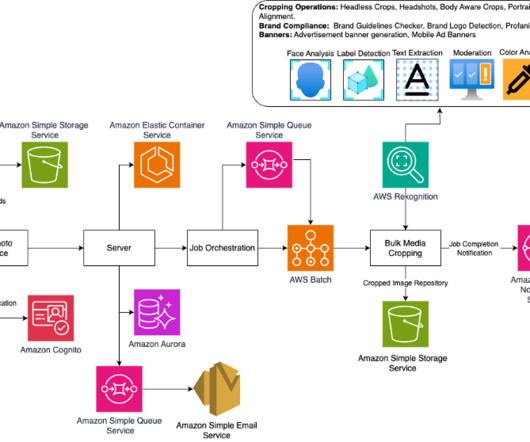
Crop.photo from Evolphin Software is a cloud-based service that offers powerful bulk processing tools for automating image cropping, content resizing, background removal, and listing image analysis. This is where Crop.photos smart automations come in with an innovative solution for high-volume image processing needs.
With so many converging factors, aggregating and assessing this information can be confusing and convoluted, which in some cases can lead to suboptimal decisions on trial sites. Smarter Trials Make Smarter Treatments Clinical trials are yet another sector which stands to be transformed by AI.
Download the Gartner® Market Guide for Active Metadata Management 1. Automated impact analysis In business, every decision contributes to the bottom line. Because lineage creates an environment where reports and data can be trusted, teams can make more informed decisions. How will one decision affect customers?
We provide additional information later in this post. For more information about the architecture in detail, refer to Part 1 of this series. Data engineers contribute to the data lineage process by providing the necessary information and metadata about the data transformations they perform.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
Here’s a handy checklist to help you find and implement the best possible observability platform to keep all your applications running merry and bright: Complete automation. Contextualizing telemetry data by visualizing the relevant information or metadata enables teams to better understand and interpret the data.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
With a decade of enterprise AI experience, Veritone supports the public sector, working with US federal government agencies, state and local government, law enforcement agencies, and legal organizations to automate and simplify evidence management, redaction, person-of-interest tracking, and eDiscovery.
Everything is data—digital messages, emails, customer information, contracts, presentations, sensor data—virtually anything humans interact with can be converted into data, analyzed for insights or transformed into a product. Automation can significantly improve efficiency and reduce errors.
With the launch of the Automated Reasoning checks in Amazon Bedrock Guardrails (preview), AWS becomes the first and only major cloud provider to integrate automated reasoning in our generative AI offerings. Click on the image below to see a demo of Automated Reasoning checks in Amazon Bedrock Guardrails.
A well-designed data architecture should support business intelligence and analysis, automation, and AI—all of which can help organizations to quickly seize market opportunities, build customer value, drive major efficiencies, and respond to risks such as supply chain disruptions.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications.
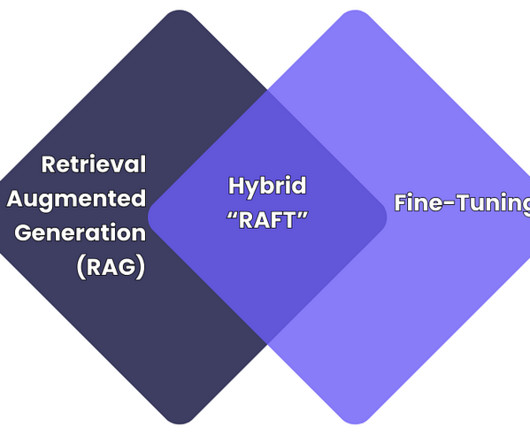
RAFT vs Fine-Tuning Image created by author As the use of large language models (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g., Solution: Build a validation pipeline with domain experts and automate checks for the dataset (e.g.,
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Banks and their employees place trust in their risk models to help ensure the bank maintains liquidity even in the worst of times.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. For more information, refer to Training Predictors.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the large language model (LLM) powering ChatGPT, have been trained on information culled from the internet. But how trustworthy is that training data?
It will help them operationalize and automate governance of their models to ensure responsible, transparent and explainable AI workflows, identify and mitigate bias and drift, capture and document model metadata and foster a collaborative environment.
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
Failing to adopt a more automated approach could have potentially led to decreased customer satisfaction scores and, consequently, a loss in future revenue. The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution. and Anthropics Claude Haiku 3.
In addition to these capabilities, generative AI can revolutionize drive tests, optimize network resource allocation, automate fault detection, optimize truck rolls and enhance customer experience through personalized services. Operators and suppliers are already identifying and capitalizing on these opportunities.
From specifying business units, domains, teams and other information about your developer landscape, Backstage can start associating those resources together. Automation and i ntegration for routine tasks through integration with various CI/CD and monitoring tools, including through a growing community of plug-ins.
In synchronous orchestration, just like in traditional process automation, a supervisor agent orchestrates the multi-agent collaboration, maintaining a high-level view of the entire process while actively directing the flow of information and tasks.
While it’s true that AI has enabled the automation of many RCM tasks, the promise of fully autonomous systems remains unfulfilled. Building a robust data foundation is critical, as the underlying data model with proper metadata, data quality, and governance is key to enabling AI to achieve peak efficiencies.
For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training. This provides an automated deployment experience on your AWS account. For more information, refer to Prompt engineering. We provide a prompt example for feedback categorization.
AI agents continue to gain momentum, as businesses use the power of generative AI to reinvent customer experiences and automate complex workflows. Employees and managers see different levels of company policy information, with managers getting additional access to confidential data like performance review and compensation details.
You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs. Some documents benefit from semantic chunking by preserving the contextual relationship in the chunks, helping make sure that the related information stays together in logical chunks.
There are two metrics used to evaluate retrieval: Context relevance Evaluates whether the retrieved information directly addresses the querys intent. It requires ground truth texts for comparison to assess recall and completeness of retrieved information. Implement metadata filtering , adding contextual layers to chunk retrieval.
Self-managed content refers to the use of AI and neural networks to simplify and strengthen the content creation process via smart tagging, metadata templates, and modular content. Role of AI and neural networks in self-management of digital assets Metadata is key in the success of self-managing content.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content