This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The IDP Well-Architected Custom Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build a secure, efficient, and reliable IDP solution on AWS. This post focuses on the Reliability pillar of the IDP solution.
Intelligent document processing (IDP) with AWS helps automate information extraction from documents of different types and formats, quickly and with high accuracy, without the need for machine learning (ML) skills. This is where IDP on AWS comes in. These challenges are only magnified as teams deal with large document volumes.
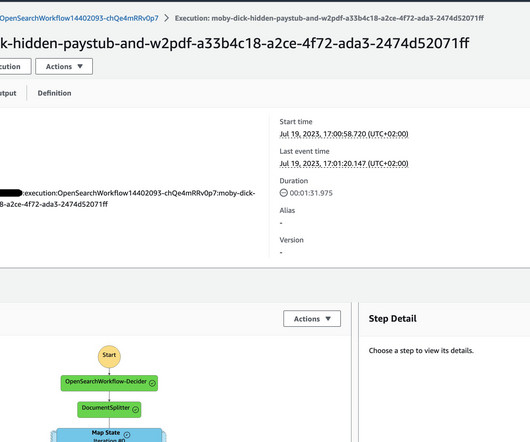
The implementation used in this post utilizes the Amazon Textract IDP CDK constructs – AWS Cloud Development Kit (CDK) components to define infrastructure for Intelligent Document Processing (IDP) workflows – which allow you to build use case specific customizable IDP workflows. Testing First test using a sample file.
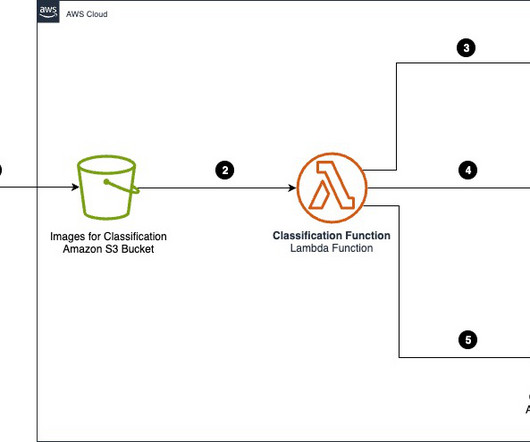
Advances in generative artificial intelligence (AI) have given rise to intelligent document processing (IDP) solutions that can automate the document classification, and create a cost-effective classification layer capable of handling diverse, unstructured enterprise documents.
Document processing has witnessed significant advancements with the advent of Intelligent Document Processing (IDP). With IDP, businesses can transform unstructured data from various document types into structured, actionable insights, dramatically enhancing efficiency and reducing manual efforts.
While the industry has been able to achieve some amount of automation through traditional OCR tools, these methods have proven to be brittle, expensive to maintain, and add to technical debt. The following diagram is how we visualize these IDP phases. It often involves manual labor taking time away from critical activities.
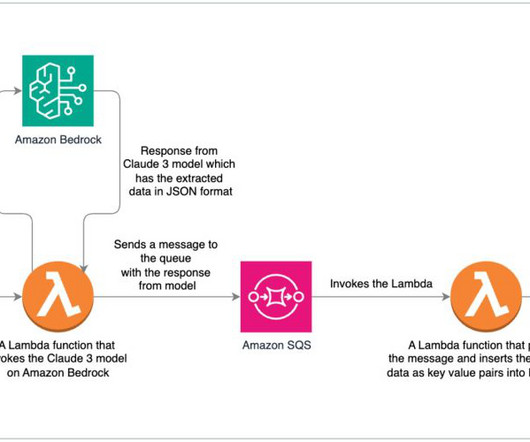
The global intelligent document processing (IDP) market size was valued at $1,285 million in 2022 and is projected to reach $7,874 million by 2028 ( source ). We specifically used the Rhubarb Python framework to extract JSON schema -based data from the documents.
The Apache Tika open-source Python library is used for data extraction from word documents. Please refer to TextractAsync , an IDP CDK construct that abstracts the invocation of the Amazon Textract Async API, handling Amazon Simple Notification Service (Amazon SNS) messages and workflow processing to accelerate your development.
Enterprise customers can unlock significant value by harnessing the power of intelligent document processing (IDP) augmented with generative AI. By infusing IDP solutions with generative AI capabilities, organizations can revolutionize their document processing workflows, achieving exceptional levels of automation and reliability.
Amazon Bedrock Data Automation in public preview helps address these and other challenges. With Amazon Bedrock Data Automation, customers can fully utilize their data by extracting insights from their unstructured multimodal content in a format compatible with their applications.
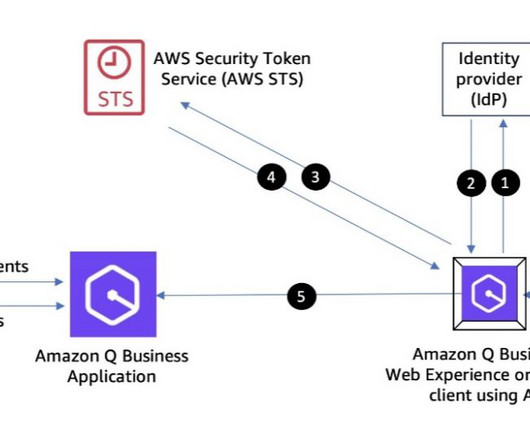
This allows you to directly manage user access to Amazon Q Business applications from your enterprise identity provider (IdP), such as Okta or PingFederate. This involves a setup described in the following steps: Create a SAML or OIDC application integration in your IdP account. The sample scripts create-iam-saml-qbiz-app.py
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content