This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
In this post, we explain how to automate this process. By adopting this automation, you can deploy consistent and standardized analytics environments across your organization, leading to increased team productivity and mitigating security risks associated with using one-time images.
And also Python is a flexible language that can be applied in various domains, including scientific programming, DevOps, automation, and web development. Introduction Setting up an environment is the first step in Python development, and it’s crucial because package management can be challenging with Python.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
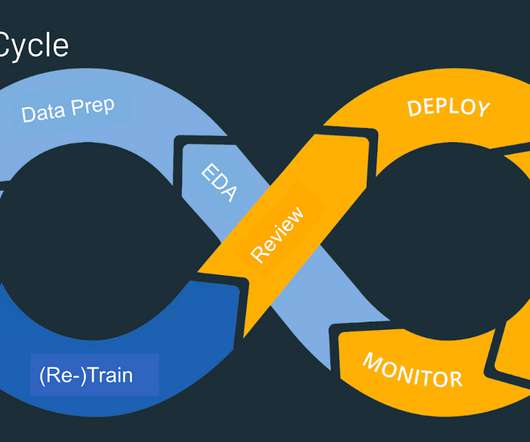
Because ML is becoming more integrated into daily business operations, datascience teams are looking for faster, more efficient ways to manage ML initiatives, increase model accuracy and gain deeper insights. MLOps is the next evolution of data analysis and deep learning. What is MLOps?
Developed internally at Google and released to the public in 2014, Kubernetes has enabled organizations to move away from traditional IT infrastructure and toward the automation of operational tasks tied to the deployment, scaling and managing of containerized applications (or microservices ).
AI-powered tools have become indispensable for automating tasks, boosting productivity, and improving decision-making. It automates code documentation and integrates seamlessly with AWS services, simplifying deployment processes. It automates model development and scales predictive analytics for businesses across industries.
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. DataScience Layers.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
MLOps, or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. ML Operations : Deploy and maintain ML models using established DevOps practices.
In the weeks since we announced our first group of partners for ODSC East 2023 , we’ve added even more industry-leading organizations and startups helping to shape the future of AI and datascience for enterprise. Through automating part of the process JetBrain frees developers to focus on growing, developing and creating.
Krista Software helps Zimperium automate operations with IBM Watson Vamsi Kurukuri, VP of Site Reliability at Zimperium, developed a strategy to remove roadblocks and pain points in Zimperium’s deployment process. Once all parties approve the release, Krista then deploys it.
IBM watsonx.data is a fit-for-purpose data store built on an open lakehouse architecture to scale AI workloads for all of your data, anywhere. IBM watsonx.governance is an end-to-end automated AI lifecycle governance toolkit that is built to enable responsible, transparent and explainable AI workflows.
This post demonstrates how to build a chatbot using Amazon Bedrock including Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock , within an automated solution. Solution overview In this post, we use publicly available data, encompassing both unstructured and structured formats, to showcase our entirely automated chatbot system.
How can a DevOps team take advantage of Artificial Intelligence (AI)? DevOps is mainly the practice of combining different teams including development and operations teams to make improvements in the software delivery processes. So now, how can a DevOps team take advantage of Artificial Intelligence (AI)?
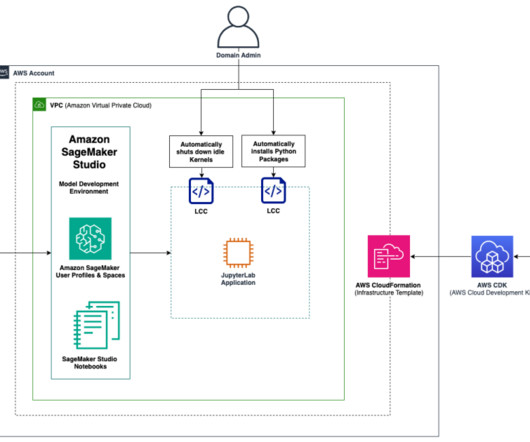
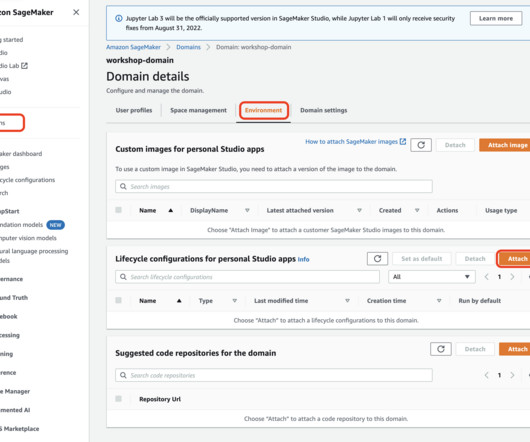
With lifecycle configurations, system administrators can apply automated controls to their SageMaker Studio domains and their users. These automations can greatly decrease overhead related to ML project setup, facilitate technical consistency, and save costs related to running idle instances.
Axfood has a structure with multiple decentralized datascience teams with different areas of responsibility. Together with a central data platform team, the datascience teams bring innovation and digital transformation through AI and ML solutions to the organization.
Programming for DataScience with Python This course series teaches essential programming skills for data analysis, including SQL fundamentals for querying databases and Unix shell basics. Students also learn Python programming, from fundamentals to data manipulation with NumPy and Pandas, along with version control using Git.
This evolution has spurred a significant demand for specialized skills in areas such as AI, data engineering, machine learning, datascience, cybersecurity, and cloud computing. Key Drivers of This Hiring Boom Evolution Beyond Support Functions GCCs are shedding their old image as mere cost-arbitrage centers.
Getting insight into your system allows you to detect and resolve issues quickly — and it’s an essential part of DevOps best practices. Proactively monitoring systems and gathering data allows AI to provide insights that enable organizations to predict risks and prevent problems from occurring.
Over the course of 3+ hours, you’ll learn How to take your machine learning model from experimentation to production How to automate your machine learning workflows by using GitHub Actions. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
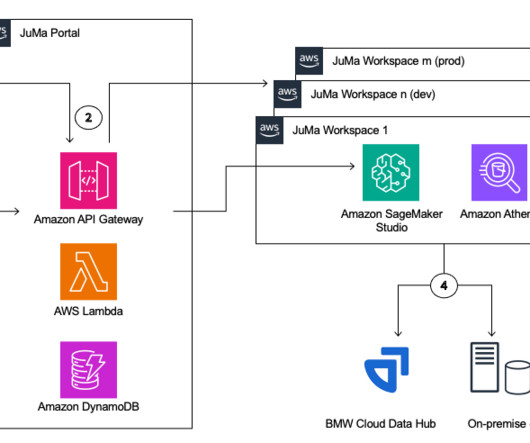
This offering enables BMW ML engineers to perform code-centric data analytics and ML, increases developer productivity by providing self-service capability and infrastructure automation, and tightly integrates with BMW’s centralized IT tooling landscape. A data scientist team orders a new JuMa workspace in BMW’s Catalog.
Since the rise of DataScience, it has found several applications across different industrial domains. However, the programming languages that work at the core of DataScience play a significant role in it. Hence for an individual who wants to excel as a data scientist, learning Python is a must.
Lived through the DevOps revolution. If you’d like a TLDR, here it is: MLOps is an extension of DevOps. Not a fork: – The MLOps team should consist of a DevOps engineer, a backend software engineer, a data scientist, + regular software folks. We need both automated continuous monitoring AND periodic manual inspection.
You need full visibility and automation to rapidly correct your business course and to reflect on daily changes. Imagine yourself as a pilot operating aircraft through a thunderstorm; you have all the dashboards and automated systems that inform you about any risks. How long will it take to replace the model? Request a Demo.
MLOps is a highly collaborative effort that aims to manipulate, automate, and generate knowledge through machine learning. They may also be involved in the deployment process’s automation. It can assist you in simplifying and automating the creation and operation of machine-learning models.
AI can also provide actionable recommendations to address issues and augment incomplete or inconsistent data, leading to more accurate insights and informed decision-making. Developments in machine learning , automation and predictive analytics are helping operations managers improve planning and streamline workflows.
MLOps practitioners have many options to establish an MLOps platform; one among them is cloud-based integrated platforms that scale with datascience teams. TWCo data scientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively.
For automated alerts for model monitoring, creating an Amazon Simple Notification Service (Amazon SNS) topic is recommended, which email user groups will subscribe to for alerts on a given CloudWatch metric alarm. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps.
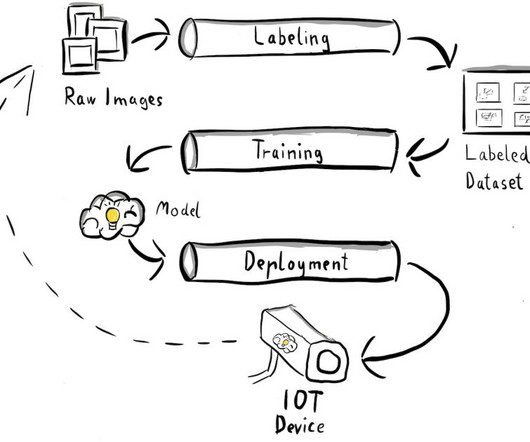
An MLOps pipeline allows to automate the full ML lifecycle from data labeling to model training and deployment. Implementing an MLOps pipeline at the edge introduces additional complexities that make the automation, integration, and maintenance processes more challenging due to the increased operational overhead involved.
This approach led to data scientists spending more than 50% of their time on operational tasks, leaving little room for innovation, and posed challenges in monitoring model performance in production. To meet this demand amidst rising claim volumes, Aviva recognizes the need for increased automation through AI technology.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. Model Training Frameworks This stage involves the process of creating and optimizing predictive models with labeled and unlabeled data.
Roy Gunter , DevOps Engineer at Curriculum Advantage, manages cloud infrastructure and automation for Classworks. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in datascience and independent consulting in AI/ML.
AI can also provide actionable recommendations to address issues and augment incomplete or inconsistent data, leading to more accurate insights and informed decision-making. Developments in machine learning , automation and predictive analytics are helping operations managers improve planning and streamline workflows.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
You can implement comprehensive tests, governance, security guardrails, and CI/CD automation to produce custom app images. Implement an automated image authoring process As already mentioned, you can use the Studio Image Build CLI to implement an automated CI/CD process of app image creation and deployment with CodeBuild and sm-docker CLI.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. A framework for vending new accounts is also covered, which uses automation for baselining new accounts when they are provisioned.
They provide advanced technology that combines AI-powered automation with human feedback, deep insights, and expertise. Although the solution did alleviate GPU costs, it also came with the constraint that data scientists needed to indicate beforehand how much GPU memory their model would require.
In addition to data engineers and data scientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
This includes AWS Identity and Access Management (IAM) or single sign-on (SSO) access, security guardrails, Amazon SageMaker Studio provisioning, automated stop/start to save costs, and Amazon Simple Storage Service (Amazon S3) set up. MLOps engineering – Focuses on automating the DevOps pipelines for operationalizing the ML use case.
As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads. Data scientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance.
MLOps focuses on the intersection of datascience and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. MLOps requires the integration of software development, operations, data engineering, and datascience.
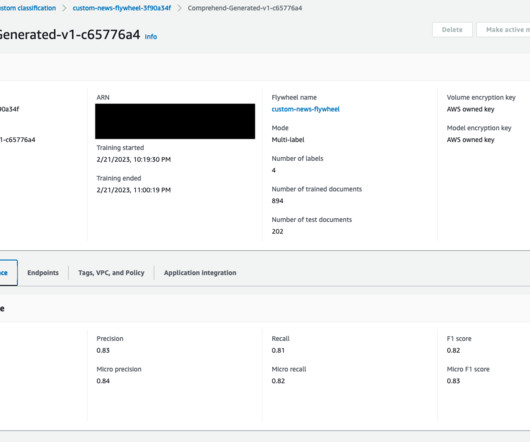
Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. The serverless batch pipeline architecture we presented offers a scalable solution for automating this process across large enterprise knowledge bases. 201% $12.2B
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content