This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
At the same time, implementing a data governance framework poses some challenges, such as dataquality issues, data silos security and privacy concerns. Dataquality issues Positive business decisions and outcomes rely on trustworthy, high-qualitydata. ” Michael L.,
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
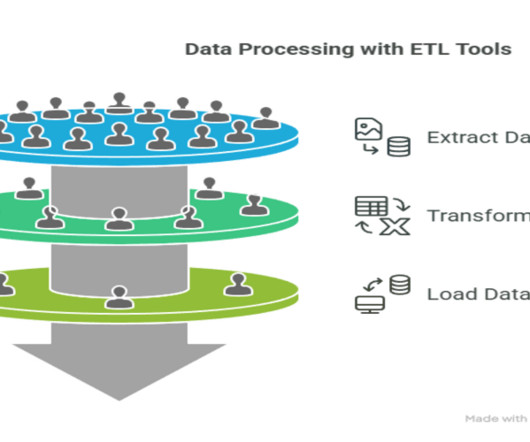
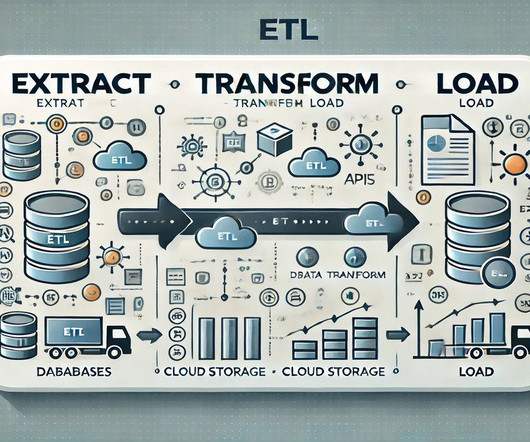
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model. With an accurate view of the entire system, banks can more easily track down issues like missing or inconsistent data.
Data often comes in different formats depending on the source. These tools help standardize this data, ensuring consistency. Moreover, data integration tools can help companies save $520,000 annually by automating manual data pipeline creation. Fivetran also provides robust data security and governance.
Data often comes in different formats depending on the source. These tools help standardize this data, ensuring consistency. Moreover, data integration tools can help companies save $520,000 annually by automating manual data pipeline creation. Fivetran also provides robust data security and governance.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Data warehousing has evolved quite a bit in the past 20-25 years. There are a lot of repetitive tasks and automation's goal is to help users in front of repetition.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems. To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. Amazon Bedrock Agents streamlines workflows and automates repetitive tasks.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Learning data engineering ensures proficiency in designing robust data pipelines, optimizing data storage, and ensuring dataquality. This skill is essential for efficiently managing and extracting value from large volumes of data, enabling businesses to stay competitive and innovative in their industries.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. How is Data Engineering Different from Data Science?
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Then, it applies these insights to automate and orchestrate the data lifecycle. Instead of handling extract, transform and load (ETL) operations within a data lake, a data mesh defines the data as a product in multiple repositories, each given its own domain for managing its data pipeline.
In addition, organizations that rely on data must prioritize dataquality review. Data profiling is a crucial tool. For evaluating dataquality. Data profiling gives your company the tools to spot patterns, anticipate consumer actions, and create a solid data governance plan.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
Align your data strategy to a go-forward architecture, with considerations for existing technology investments, governance and autonomous management built in. Look to AI to help automate tasks such as data onboarding, data classification, organization and tagging.
An additional 79% claim new business analysis requirements take too long to be implemented by their data teams. Other factors hindering widespread AI adoption include the lack of an implementation strategy, poor dataquality, insufficient data volumes and integration with existing systems.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. What is Data Profiling in ETL?
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. These tools automate the process, making it faster and more accurate.
Limited Scalability : The process is not workable for handling large volumes of data. ETL (Extract, Transform, Load) ETL is a widely used data integration technique. Pros Automation: ETL tools automate the extraction, transformation, and loading processes. Wrapping It Up !!!
Architecture overview Our MLOps architecture is designed to automate and monitor all stages of the ML lifecycle. An example direct acyclic graph (DAG) might automatedata ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Data Warehouses and Relational Databases It is essential to distinguish data lakes from data warehouses and relational databases, as each serves different purposes and has distinct characteristics. Schema Enforcement: Data warehouses use a “schema-on-write” approach.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
It enables reporting and Data Analysis and provides a historical data record that can be used for decision-making. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring dataquality and integrity.
As the volume of data keeps increasing at an accelerated rate, these data tasks become arduous in no time leading to an extensive need for automation. This is what data processing pipelines do for you. Let’s understand how the other aspects of a data pipeline help the organization achieve its various objectives.
These technologies include the following: Data governance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security. It is also important to establish dataquality standards and strict access controls.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Run the notebooks The sample code for this solution is available on GitHub.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. It supports both batch and real-time processing.
Automation : Automating as many tasks to reduce human error and increase efficiency. Collaboration : Ensuring that all teams involved in the project, including data scientists, engineers, and operations teams, are working together effectively. This includes dataquality, privacy, and compliance.
As stated above, data pipelines represent the backbone of modern data architecture. These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Web Scraping: Automated extraction from websites using scripts or specialised tools.
Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format. DataQuality Management : Ensures that the integrated data is accurate, consistent, and reliable for analysis. What Are Some Common Tools Used in Business Intelligence Architecture?
Business Requirements Analysis and Translation Working with business users to understand their data needs and translate them into technical specifications. DataQuality Assurance Implementing dataquality checks and processes to ensure data accuracy and reliability. What Are Key Skills for A BI Analyst?
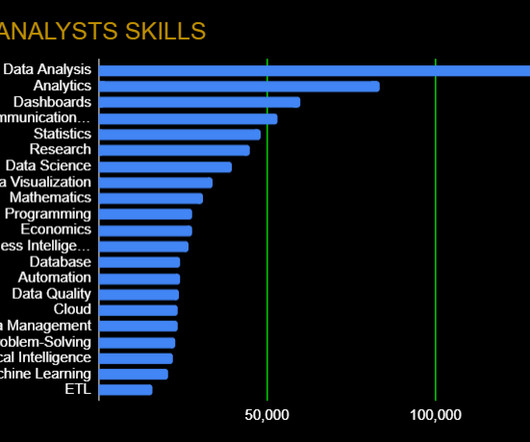
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Example: Uber Implementation: To match riders with drivers almost instantaneously, Uber processes real-time data about ride requests, driver locations in real-time, and rider locations as well. Tooling Used: Apache Kafka is used for real-time streaming and processing of real-time data.
You can use stored procedures to handle complex ETL processes, make API calls, and perform data validation. Data Validation With stored procedures, you can validate data fields, data types, and constraints on data input to maintain dataquality.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
Led by agricultural technology innovators, generative AI is the latest AI technology that helps agronomists and researchers have open-ended human-like interactions with computing applications to assist with a variety of tasks and automate historically manual processes. AWS Lambda is then used to further enrich the data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content