This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Illumex enables organizations to deploy genAI analytics agents by translating scattered, cryptic data into meaningful, context-rich business language with built-in governance. By creating business terms, suggesting metrics, and identifying potential conflicts, Illumex ensures data governance at the highest standards.
AI algorithms learn from data; they identify patterns, make decisions, and generate predictions based on the information they're fed. Consequently, the quality of this training data is paramount. AI's Role in Improving DataQuality While the problem of dataquality may seem daunting, there is hope.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Data warehousing has evolved quite a bit in the past 20-25 years. There are a lot of repetitive tasks and automation's goal is to help users in front of repetition.
Event triggers are used to automate workflows or decisions, allowing businesses to generate notifications so appropriate actions can be taken as swiftly as situations are detected. Flexible and customizable Kafka configurations can be automated by using a simple user interface. Ready to take the next step?
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “AutomatingDataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “AutomatingDataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “AutomatingDataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
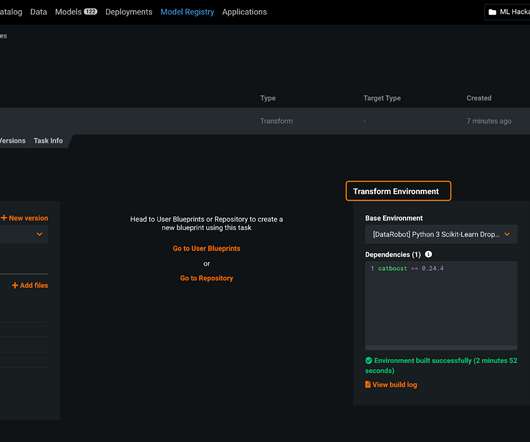
In this post, we will dive deeper into the first component of managing model risk, and look at opportunities at how automation provided by DataRobot brings about efficiencies in the development and implementation of models. . With this definition of model risk, how do we ensure the models we build are technically correct?
Go to Definition: This feature lets users right-click on any Python variable or function to access its definition. This facilitates seamless navigation through the codebase, allowing users to locate and understand variable or function definitions quickly. This visual aid helps developers quickly identify and correct mistakes.
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. Workflow B corresponds to model quality drift checks.
The software provides an integrated and unified platform for disparate business processes such as supply chain management and human resources , providing a holistic view of an organization’s operations and breaking down data silos. Using automation , Oracle can simplify routine tasks to increase operational efficiency.
This article offers a measured exploration of AI agents, examining their definition, evolution, types, real-world applications, and technical architecture. Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processing data, and taking action to achieve specified goals.
You define a denied topic by providing a natural language definition of the topic along with a few optional example phrases of the topic. If you are planning on using automated model evaluation for toxicity, start by defining what constitutes toxic content for your specific application. Therefore, consider risk management here.
From basic driver assistance to fully autonomous vehicles(AVs) capable of navigating without human intervention, the progression is evident through the SAE Levels of vehicle automation. Different definitions of safety exist, from risk reduction to minimizing harm from unwanted outcomes.
Prolific was created by researchers for researchers, aiming to offer a superior method for obtaining high-quality human data and input for cutting-edge research. Today, over 35,000 researchers from academia and industry rely on Prolific AI to collect definitive human data and feedback.
Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Summary: This article provides a comprehensive overview of data migration, including its definition, importance, processes, common challenges, and popular tools. By understanding these aspects, organisations can effectively manage data transfers and enhance their data management strategies for improved operational efficiency.
Supports data governance and data lineage tracking. Provides scheduling and automation features. Informatica DataQuality Pros: Robust data profiling and standardization capabilities. Comprehensive data cleansing and enrichment options. Scalable for handling enterprise-level data.
Tamr makes it easy to load new sources of data because its AI automatically maps new fields into a defined entity schema. This means that regardless of what a new data source calls a particular field (example: cust_name) it gets mapped to the right central definition of that entity (example: “customer name”).
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. API Integration: Accessing data through Application Programming Interfaces (APIs) provided by external services. The Difference Between Data Observability And DataQuality.
Automating the process of building complex prompts has become common, with patterns like retrieval-augmented generation (RAG) and tools like LangChain. Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% Developers are learning how to find qualitydata and build models that work.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few. We have made this process simple by automating the whole training pipeline.
These approaches differ fundamentally in how they handle data acquisition, model training, and human interaction. In this blog, we will delve into the world of passive and active learning, exploring their definitions, key differences, advantages, and practical applications in Machine Learning.
With the exponential growth of data and increasing complexities of the ecosystem, organizations face the challenge of ensuring data security and compliance with regulations. Relying on a credible Data Governance platform is paramount to seamlessly implementing Data Governance policies. The same applies to data.
Data Collection Methods There are several methods for collecting data. Surveys and questionnaires can capture primary data directly from users. Automated systems can extract data from websites or applications. APIs provide structured data from other systems. Why is DataQuality Crucial in Both Cycles?
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital.
Summary: This blog provides a comprehensive overview of data collection, covering its definition, importance, methods, and types of data. It also discusses tools and techniques for effective data collection, emphasising quality assurance and control.
In this blog, we have covered Data Management and its examples along with its benefits. What is Data Management? Before delving deeper into the process of Data Management and its significance, let’s scratch the surface of the Data Management definition.
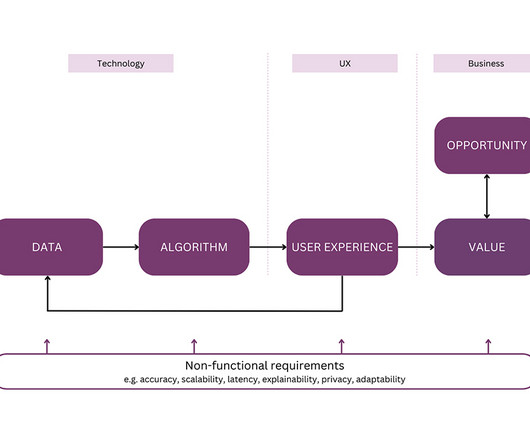
The model serves as a tool for the discussion, planning, and definition of AI products by cross-disciplinary AI and product teams, as well as for alignment with the business department. It aims to bring together the perspectives of product managers, UX designers, data scientists, engineers, and other team members.
Complexity in Goal Definition: Requires domain knowledge for accurate goal setting. Data-Driven Insights: Utilises historical data for informed predictions, improving accuracy over time. Disadvantages DataQuality Dependency : Predictions are only as good as the dataquality; poor data can lead to inaccurate forecasts.
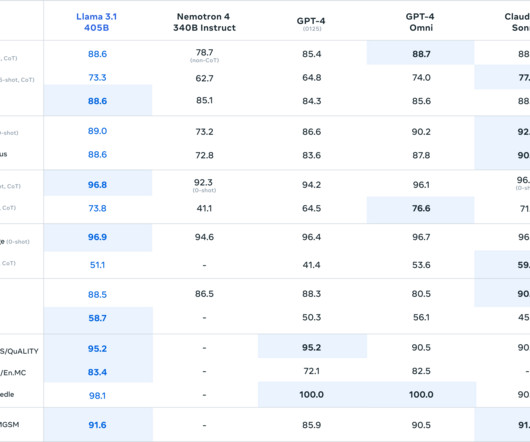
DataQuality and Processing: Meta significantly enhanced their data pipeline for Llama 3.1: DataQuality and Processing: Meta significantly enhanced their data pipeline for Llama 3.1: ceLLama is a streamlined automation pipeline for cell type annotations using large-language models (LLMs).
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, data preparation, and algorithm selection. Dataquality significantly impacts model performance.
Automation : Automating as many tasks to reduce human error and increase efficiency. Collaboration : Ensuring that all teams involved in the project, including data scientists, engineers, and operations teams, are working together effectively. This includes dataquality, privacy, and compliance.
When we integrate computer vision algorithms with geospatial intelligence, it helps automate large volumes of spatial data analysis. Computer Vision for Urban Analysis Computer vision (CV) techniques can be very helpful in analyzing visual data, such as satellite imagery, drone footage, or street-level photographs.
Using Power Query, you can automate cleaning and organising large datasets, making it easier to maintain data integrity. VBA allows you to write macros that automate tasks, including handling duplicates. VBA allows you to write macros that automate tasks, including handling duplicates. MIS Report in Excel?
It’s an automated chief of staff that automates conversational tasks. We are aiming to automate that functionality so that every worker in an organization can have access to that help, just like a CEO or someone else in the company would. Jason: Hi Sabine, how’s it going? Jason, you are the co-founder and CTO of Xembly.
Applying Weak Supervision and Foundation Models for Computer Vision In this session, Snorkel’s own ML Research Scientist Ravi Teja Mullapudi explores the latest advancements in computer vision that enable data-centric image classification model development. Wayfair does this by automating image tagging using a data-centric approach.
It’s a really historically exciting time—definitely in AI, but I venture across many different technology areas. But those elements used to be the blocker, and are often really not the blocker anymore because of all the amazing work that’s been done by the community—often now out in the open source.
It’s a really historically exciting time—definitely in AI, but I venture across many different technology areas. But those elements used to be the blocker, and are often really not the blocker anymore because of all the amazing work that’s been done by the community—often now out in the open source.
Applying Weak Supervision and Foundation Models for Computer Vision In this session, Snorkel’s own ML Research Scientist Ravi Teja Mullapudi explores the latest advancements in computer vision that enable data-centric image classification model development. Wayfair does this by automating image tagging using a data-centric approach.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content