This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A lakehouse should make it easy to combine new data from a variety of different sources, with mission critical data about customers and transactions that reside in existing repositories. Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data.
A well-designed data architecture should support business intelligence and analysis, automation, and AI—all of which can help organizations to quickly seize market opportunities, build customer value, drive major efficiencies, and respond to risks such as supply chain disruptions.
Year after year, IBM Consulting works with the United States Tennis Association (USTA) to transform massive amounts of data into meaningful insight for tennis fans. This year, the USTA is using watsonx , IBM’s new AI and dataplatform for business.
With the launch of the Automated Reasoning checks in Amazon Bedrock Guardrails (preview), AWS becomes the first and only major cloud provider to integrate automated reasoning in our generative AI offerings. Click on the image below to see a demo of Automated Reasoning checks in Amazon Bedrock Guardrails.
IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. Automated development: Automatesdata preparation, model development, feature engineering and hyperparameter optimization using AutoAI.
Unstructured enables companies to transform their unstructured data into a standardized format, regardless of file type, and enrich it with additional metadata. Text-to-SQL models are getting very good, which will dramatically reduce the barrier to working with data for a broad range of use cases beyond business intelligence.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a DataPlatform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Dataplatforms & Data Governance.
Align your data strategy to a go-forward architecture, with considerations for existing technology investments, governance and autonomous management built in. Look to AI to help automate tasks such as data onboarding, data classification, organization and tagging.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables. It has a quick and clear grasp of data quality issues.
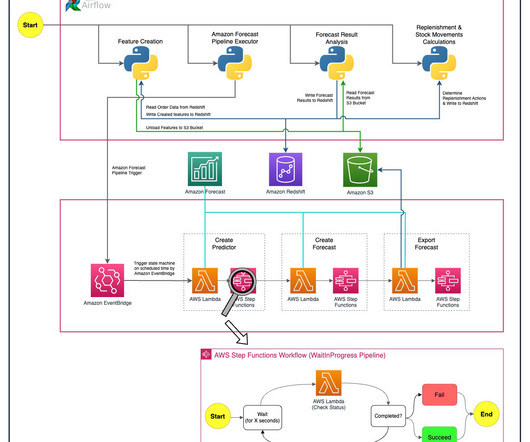
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. Forecast automates much of the time-series forecasting process, enabling you to focus on preparing your datasets and interpreting your predictions.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. 201% $12.2B
A framework for vending new accounts is also covered, which uses automation for baselining new accounts when they are provisioned. You can start small with one account for your dataplatform foundations for a proof of concept or a few small workloads.
In order analyze the calls properly, Principal had a few requirements: Contact details: Understanding the customer journey requires understanding whether a speaker is an automated interactive voice response (IVR) system or a human agent and when a call transfer occurs between the two.
This means they need the tools that can help with testing and documenting the model, automation across the entire pipeline and they need to be able to seamlessly integrate the model into business critical applications or workflows. They need the right expertise at the right stage as they work up the AI maturity curve.
A recent study of data drift issues at Uber reveled a highly diverse perspective. Image Credit: Uber Uber recognizes the need for a robust automated system that can effectively measure and monitor column-level data quality. Automated Anomaly Detection: D3 eliminates the manual process of setting thresholds for anomaly detection.
A feature store is a dataplatform that supports the creation and use of feature data throughout the lifecycle of an ML model, from creating features that can be reused across many models to model training to model inference (making predictions). It can also transform incoming data on the fly. What is a feature store?
How to set up an ML Platform in eCommerce? The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from data preparation to model deployment and monitoring. An ML Platform helps in the faster iteration of an ML project lifecycle. via Data Connectors.
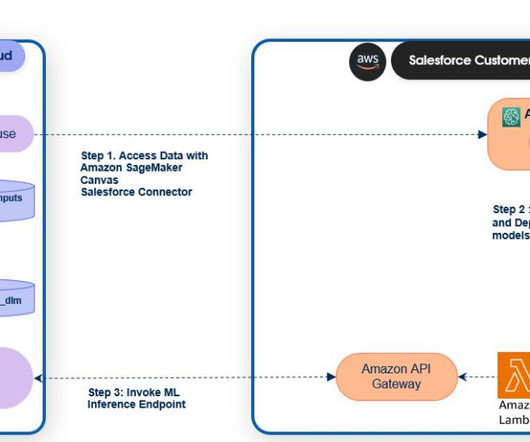
Use the newly launched SageMaker provided project template for Salesforce Data Cloud integration to streamline implementing the preceding steps by providing the following templates: An example notebook showcasing data preparation, building, training, and registering the model. Choose clone repo for both notebooks.
Bulk Data Load Data migration to Snowflake can be a challenge. The solution provides Snowpipe for extended data loading; however, sometimes, it’s not the best option. There can be alternatives that expedite and automatedata flows. Furthermore, a shared-data approach stems from this efficient combination.
Tools range from dataplatforms to vector databases, embedding providers, fine-tuning platforms, prompt engineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. Model management Teams typically manage their models, including versioning and metadata.
Cloud-based data storage solutions, such as Amazon S3 (Simple Storage Service) and Google Cloud Storage, provide highly durable and scalable repositories for storing large volumes of data. These services automate infrastructure management tasks, allowing data engineers and scientists to focus on data processing and analysis.
There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata. We’re assuming that data scientists, for the most part, don’t want to write transformations elsewhere. Mikiko Bazeley: 100%.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. You need to build your ML platform with experimentation and general workflow reproducibility in mind.
These are subject-specific subsets of the data warehouse, catering to the specific needs of departments like marketing or sales. They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself.
It’s often described as a way to simply increase data access, but the transition is about far more than that. When effectively implemented, a data democracy simplifies the data stack, eliminates data gatekeepers, and makes the company’s comprehensive dataplatform easily accessible by different teams via a user-friendly dashboard.
Salesforce Data Cloud and Einstein Studio Salesforce Data Cloud is a dataplatform that provides businesses with real-time updates of their customer data from any touch point. Einstein Studio is a gateway to AI tools on Salesforce Data Cloud. Salesforce adds a “__c “ to all the Data Cloud object fields.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content