This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Proprietary LLMs are owned by a company and can only be used by customers that purchase a license. The license may restrict how the LLM can be used. On the other hand, open source LLMs are free and available for anyone to access, use for any purpose, modify and distribute. What are the benefits of open source LLMs?
When framed in the context of the Intelligent Economy RAG flows are enabling access to information in ways that facilitate the human experience, saving time by automating and filtering data and information output that would otherwise require significant manual effort and time to be created.
With the launch of the Automated Reasoning checks in Amazon Bedrock Guardrails (preview), AWS becomes the first and only major cloud provider to integrate automated reasoning in our generative AI offerings. Click on the image below to see a demo of Automated Reasoning checks in Amazon Bedrock Guardrails.
Since its preview launch at re:Invent 2024, organizations across industriesincluding financial services, healthcare, supply chain and logistics, manufacturing, and customer supporthave used multi-agent collaboration to orchestrate specialized agents, driving efficiency, accuracy, and automation. What is multi-agent collaboration?
In the year since we unveiled IBM’s enterprise generative AI (gen AI) and dataplatform, we’ve collaborated with numerous software companies to embed IBM watsonx™ into their apps, offerings and solutions. “These technologies offer significant potential to streamline and automate daily sales activities at scale.
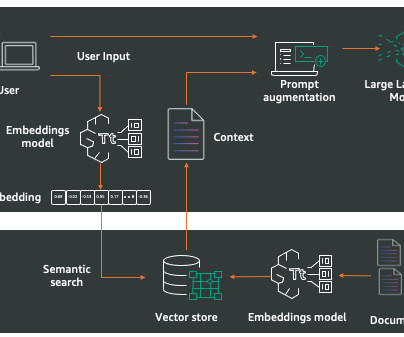
Thankfully, retrieval-augmented generation (RAG) has emerged as a promising solution to ground large language models (LLMs) on the most accurate, up-to-date information. IBM unveiled its new AI and dataplatform, watsonx™, which offers RAG, back in May 2023.
IBM watsonx Assistant connects to watsonx, IBM’s enterprise-ready AI and dataplatform for training, deploying and managing foundation models, to enable business users to automate accurate, conversational question-answering with customized watsonx large language models.
This approach makes sure that the LLM operates within specified ethical and legal parameters, much like how a constitution governs a nations laws and actions. client(service_name="bedrock-runtime", region_name="us-east-1") llm = ChatBedrock(client=bedrock_runtime, model_id="anthropic.claude-3-haiku-20240307-v1:0") .
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.”
Together, Ulrik and I saw a huge opportunity to build a platform to automate and streamline the AI data development process, making it easier for teams to get the best data into models and build trustworthy AI systems. Index is not limited to a single form of data like many LLM tools today.
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
Just last month, Salesforce made a major acquisition to power its Agentforce platform—just one in a number of recent investments in unstructured data management providers. “Most data being generated every day is unstructured and presents the biggest new opportunity.”
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
Currently chat bots are relying on rule-based systems or traditional machine learning algorithms (or models) to automate tasks and provide predefined responses to customer inquiries. The LLM solution has resulted in an 80% reduction in manual effort and in 90% accuracy of automated tasks. Watsonx.ai
Airflow provides the workflow management capabilities that are integral to modern cloud-native dataplatforms. It automates the execution of jobs, coordinates dependencies between tasks, and gives organizations a central point of control for monitoring and managing workflows.
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles.
The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for data ingestion. The objective is to automatedata integration from various sensor manufacturers for Accra, Ghana, paving the way for scalability across West Africa.
A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. The platform comprises three powerful products: The watsonx.ai
John Snow Labs’ Medical Language Models library is an excellent choice for leveraging the power of large language models (LLM) and natural language processing (NLP) in Azure Fabric due to its seamless integration, scalability, and state-of-the-art accuracy on medical tasks.
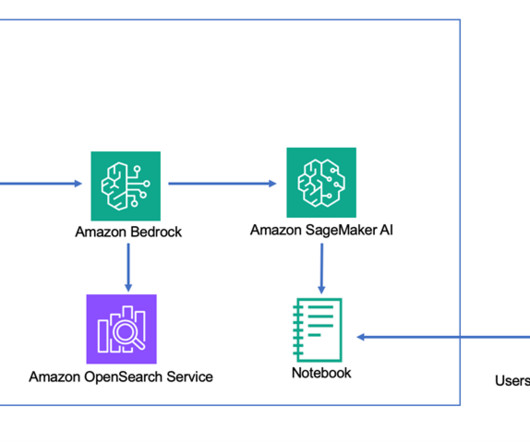
Enterprises want to automate frequently asked transactional questions, provide a friendly conversational interface, and improve operational efficiency. The text generation LLM can optionally be used to create the search query and synthesize a response from the returned document excerpts.
We demonstrate BYO LLM integration by using Anthropic’s Claude model on Amazon Bedrock to summarize a list of open service cases and opportunities on an account record page, as shown in the following figure. Solution overview With the Salesforce Einstein Model Builder BYO LLM feature, you can invoke Amazon Bedrock models in your AWS account.
Search-R1 In the paper "Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning" researchers from the University of Illinois at Urbana-Champaign introduce SEARCH-R1, a novel reinforcement learning framework that enables large language models to interleave self-reasoning with real-time search engine interactions.
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
RAG is a methodology to improve the accuracy of LLM responses answering a user query by retrieving and inserting relevant domain knowledge into the language model prompt. Tuning chunking and indexing in the retriever makes sure the correct content is available in the LLM prompt for generation.
Created Using Midjourney In case you missed yesterday’s newsletter due to July the 4th holiday, we discussed the universe of in-context retrieval augmented LLMs or techniques that allow to expand the LLM knowledge without altering its core architecutre. It’s a good one. Go check it out.
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. However, transforming raw LLMs into production-ready applications presents complex challenges.
This open-source startup that specializes in neural networks has made a name for itself building a platform that allows organizations to train large language models. MosaicML is one of the pioneers of the private LLM market, making it possible for companies to harness the power of specialized AI to suit specific needs.
This is the result of a concentrated effort to deeply integrate its technology across a range of cloud and dataplatforms, making it easier for customers to adopt and leverage its technology in a private, safe, and scalable way.
From Data Collection to ML Model Deployment in Less Than 30 Minutes Hudson Buzby | Qwak Solution Architect | Qwak Explore Qwak MLOps Platform, a comprehensive platform tailored to empower data scientists, engineers, and organizations.
Variational Autoencoders (VAEs): VAEs encode and decode data, enabling the generation of novel content while preserving key features. Read More: Guide to Understand “AI, GAI, ML, LLM, GANs, and GPTs” Let us now delve deeper into a few of these use cases.
By automating repetitive tasks and generating boilerplate code, these tools free up time for engineers to focus on more complex, creative aspects of software development. Well, it is offering a way to automate the time-consuming process of writing and running tests. Just keep in mind, that this shouldn’t replace the human element.
Use the newly launched SageMaker provided project template for Salesforce Data Cloud integration to streamline implementing the preceding steps by providing the following templates: An example notebook showcasing data preparation, building, training, and registering the model. Choose clone repo for both notebooks.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions.
Saket Saurabh , CEO and Co-Founder of Nexla, is an entrepreneur with a deep passion for data and infrastructure. He is leading the development of a next-generation, automateddata engineering platform designed to bring scale and velocity to those working with data.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
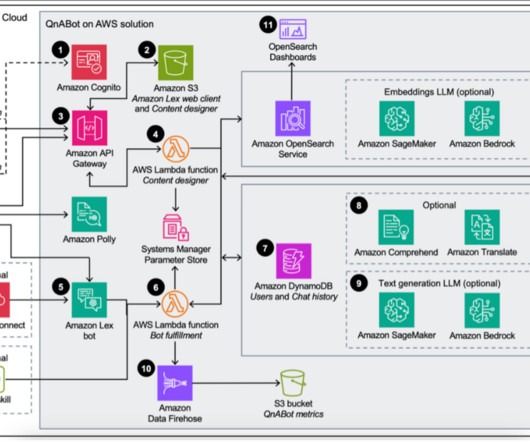
Solution overview The code in the accompanying GitHub repo provided in this solution enables an automated deployment of Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and the required resources to integrate the Amazon Bedrock Knowledge Bases API with a Slack slash command assistant using the Bolt for Python library.
In this post, we illustrate the importance of generative AI in the collaboration between Tealium and the AWS Generative AI Innovation Center (GenAIIC) team by automating the following: Evaluating the retriever and the generated answer of a RAG system based on the Ragas Repository powered by Amazon Bedrock.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content