This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Krista Software helps Zimperium automate operations with IBM Watson Vamsi Kurukuri, VP of Site Reliability at Zimperium, developed a strategy to remove roadblocks and pain points in Zimperium’s deployment process. Once all parties approve the release, Krista then deploys it.
Additionally, the integration of SageMaker features in iFoods infrastructure automates critical processes, such as generating training datasets, training models, deploying models to production, and continuously monitoring their performance. This integration not only simplifies complex processes but also automates critical tasks.
These include data ingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps. IBM watsonx consists of the following: IBM watsonx.ai
IBM iX , the experience design arm of IBM Consulting, and IBM’s AI consultants work with the United States Tennis Association (USTA) to integrate technology from dozens of partners, automate key business processes and develop new features. Most importantly though, the teams focus on delivering world-class digital experiences to fans.
From there, the chatbot uses automation to scan the database of responses and provide the most relevant response. There, a member of an IT or DevOps team can walk through the problem with an individual and provide real-time instructions for them to fix the problem themselves.
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. This created a challenge for data scientists to become productive.
Axfood has a structure with multiple decentralized data science teams with different areas of responsibility. Together with a central dataplatform team, the data science teams bring innovation and digital transformation through AI and ML solutions to the organization.
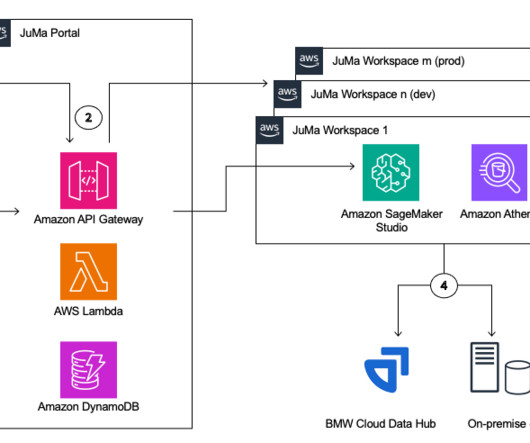
This offering enables BMW ML engineers to perform code-centric data analytics and ML, increases developer productivity by providing self-service capability and infrastructure automation, and tightly integrates with BMW’s centralized IT tooling landscape. A data scientist team orders a new JuMa workspace in BMW’s Catalog.
This approach led to data scientists spending more than 50% of their time on operational tasks, leaving little room for innovation, and posed challenges in monitoring model performance in production. To meet this demand amidst rising claim volumes, Aviva recognizes the need for increased automation through AI technology.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. The reference architecture for the ML platform with various AWS services is shown in the following diagram.
This means they need the tools that can help with testing and documenting the model, automation across the entire pipeline and they need to be able to seamlessly integrate the model into business critical applications or workflows. They need the right expertise at the right stage as they work up the AI maturity curve.
Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. The serverless batch pipeline architecture we presented offers a scalable solution for automating this process across large enterprise knowledge bases. 201% $12.2B
Data gathering, pre-processing, modeling, and deployment are all steps in the iterative process of predictive analytics that results in output. We can automate the procedure to deliver forecasts based on new data continuously fed throughout time. This tool’s user-friendly UI consistently receives acclaim from users.
It should be able to version the project assets of your data scientists, such as the data, the model parameters, and the metadata that comes out of your workflow. Automation You want the ML models to keep running in a healthy state without the data scientists incurring much overhead in moving them across the different lifecycle phases.
By automating repetitive tasks and generating boilerplate code, these tools free up time for engineers to focus on more complex, creative aspects of software development. Well, it is offering a way to automate the time-consuming process of writing and running tests. Just keep in mind, that this shouldn’t replace the human element.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production.
The advantages of using synthetic data include easing restrictions when using private or controlled data, adjusting the data requirements to specific circumstances that cannot be met with accurate data, and producing datasets for DevOps teams to use for software testing and quality assurance.
I switched from analytics to data science, then to machine learning, then to data engineering, then to MLOps. For me, it was a little bit of a longer journey because I kind of had data engineering and cloud engineering and DevOps engineering in between. You shifted straight from data science, if I understand correctly.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content