This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. First, we explore the option of in-context learning, where the LLM generates the requested metadata without documentation.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
In this post, we propose an end-to-end solution using Amazon Q Business to address similar enterprise data challenges, showcasing how it can streamline operations and enhance customer service across various industries. For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services.
Access to high-quality data can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality.
In addition to these capabilities, generative AI can revolutionize drive tests, optimize network resource allocation, automate fault detection, optimize truck rolls and enhance customer experience through personalized services. This aids in better dataintegration and utilization in the upper layers.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
In the face of these challenges, MLOps offers an important path to shorten your time to production while increasing confidence in the quality of deployed workloads by automating governance processes. This post illustrates how to use common architecture principles to transition from a manual monitoring process to one that is automated.
IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. The data governance capability of a data fabric focuses on the collection, management and automation of an organization’s data. Dataintegration.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.)
Moreover, Crawl4AI offers features such as user-agent customization, JavaScript execution for dynamic data extraction, and proxy support to bypass web restrictions, enhancing its versatility compared to traditional crawlers. Crawl4AI employs a multi-step process to optimize web crawling for LLM training.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Extraction of relevant data points for electronic health records (EHRs) and clinical trial databases. Dataintegration and reporting The extracted insights and recommendations are integrated into the relevant clinical trial management systems, EHRs, and reporting mechanisms.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables. The 18 best data profiling tools are listed below.
Transparency throughout the data lifecycle and the ability to demonstrate dataintegrity and consistency are critical factors for improvement. The ledger delivers tamper evidence, enabling the detection of any modifications made to the data, even if carried out by privileged users.
For me, computer science is like solving a series of intricate puzzles with the added thrill of automation. How is data.world investing in research and development to stay at the forefront of AI and dataintegration technologies? We’re committed to staying at the bleeding edge of what’s possible in AI and dataintegration.
Both approaches were typically monolithic and centralized architectures organized around mechanical functions of data ingestion, processing, cleansing, aggregation, and serving. Monitor and identify data quality issues closer to the source to mitigate the potential impact on downstream processes or workloads.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of data pipelines.
They excel at managing structured data and supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions. Scalability: Relational databases can scale vertically by upgrading hardware, but horizontal scaling can be more challenging due to the need to maintain dataintegrity and relationships.
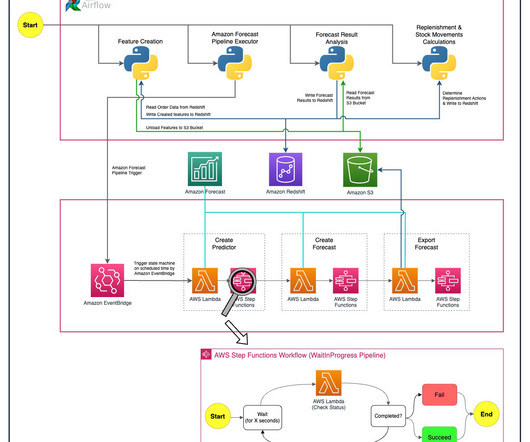
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. Forecast automates much of the time-series forecasting process, enabling you to focus on preparing your datasets and interpreting your predictions.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
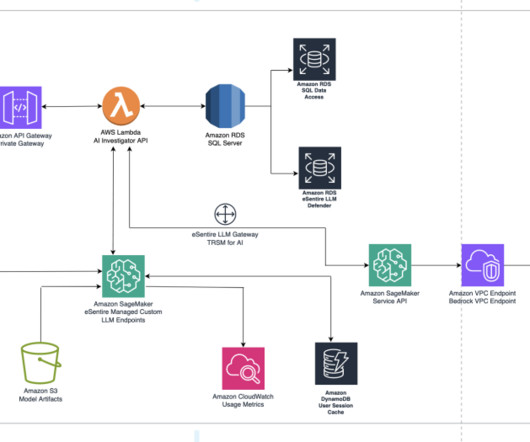
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. eSentire used gigabytes of additional human investigation metadata to perform supervised fine-tuning on Llama 2. They needed no additional infrastructure for dataintegration.
Packaging models with PMML Using the PMML library in Python, you can export your machine learning models to PMML format and then deploy that as a web service, a batch processing system, or a dataintegration platform. Finally, you can store the model and other metadata information using the INSERT INTO command.
Summary: Apache NiFi is a powerful open-source data ingestion platform design to automatedata flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. What is Apache NiFi?
Its in-memory processing helps to ensure that data is ready for quick analysis and reporting, enabling real-time what-if scenarios and reports without lag. Our solution handles massive multidimensional cubes seamlessly, enabling you to maintain a complete view of your data without sacrificing performance or dataintegrity.
Relying on a credible Data Governance platform is paramount to seamlessly implementing Data Governance policies. These platforms are centralized and designed to manage data practices, facilitate collaboration among different stakeholders, and automate the Data Governance workflow. The same applies to data.
Data lakes are able to handle a diverse range of data types. From images, videos, text, and even sensor data. Then, there’s dataintegration. A data lake can also act as a central hub for integratingdata from various sources and systems within an organization.
Types of Data Profiling: Data profiling can be broadly categorized into three main types, each focusing on different aspects of the data: Structural Profiling: Structural profiling involves analyzing the structure and metadata of the data. It supports metadata analysis, data lineage, and data quality assessment.
With the use of these tools, one can streamline the data modelling process. Moreover, these tools are designed to automate tasks like generating SQL scripts, documenting metadata and others. This automation boosts productivity and also saves time. Data Dictionary A data dictionary is a repository of metadata.
This process involves real-time monitoring and documentation to provide visibility on the data quality, thereby helping the organization detect and address data-related issues. Bigeye Its analytical prowess and data visualization capabilities will help Data Scientists make effective data-driven decision-making.
This comprehensive guide covers practical frameworks to enable effective holistic scoping, planning, governance, and deployment of project management for data science. Proper management and strategic stakeholder alignment allow data science leaders to avoid common missteps and accelerate ROI.
The primary purpose of a DBMS is to provide a systematic way to manage large amounts of data, ensuring that it is organised, accessible, and secure. By employing a DBMS, organisations can maintain dataintegrity, reduce redundancy, and streamline data operations, enabling more informed decision-making.
Data Processing is the process of transforming and manipulating raw data to meaningful insights for effective use in business purposes. Data Processing is done in both manual and automated manner, depending on the type of complexity in the data and the required outcomes. The Data Science courses provided by Pickl.AI
This includes removing duplicates, correcting typos, and standardizing data formats. It forms the bedrock of data quality improvement. Implement Data Validation Rules To maintain dataintegrity, establish strict validation rules. This ensures that the data entered meets predefined criteria.
Data Transparency Data Transparency is the pillar that ensures data is accessible and understandable to all stakeholders within an organization. This involves creating data dictionaries, documentation, and metadata. It provides clear insights into the data’s structure, meaning, and usage.
It requires sophisticated tools and algorithms to derive meaningful patterns and trends from the sheer magnitude of data. Meta DataMetadata, often dubbed “data about data,” provides essential context and descriptions for other datasets.
These services automate infrastructure management tasks, allowing data engineers and scientists to focus on data processing and analysis. The combination of Hadoop, Spark, and cloud computing revolutionized the field of data engineering in the 2010s. This avoids data lock-in from proprietary formats.
There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata. We’re assuming that data scientists, for the most part, don’t want to write transformations elsewhere. Mikiko Bazeley: 100%.
This feature uses ML and generative AI technologies to provide automated root cause analysis for failed Spark applications, along with actionable recommendations and remediation steps. He is passionate about distributed computing and using ML/AI for designing and building end-to-end solutions to address customers’ dataintegration needs.
It facilitates real-time data synchronization and updates by using GraphQL APIs, providing seamless and responsive user experiences. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more. He currently is working on Generative AI for dataintegration.
In this session, learn how your data users can get to near-real-time insights on streaming data with Amazon Redshift and AWS streaming data services. In this session, learn about Amazon Redshift’s technical innovations including serverless, AI/ML-powered autonomics, and zero-ETL dataintegrations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content