This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This work involved creating a single set of definitions and procedures for collecting and reporting financial data. The water company also needed to develop reporting for a data warehouse, financial dataintegration and operations.
Access to high-quality data can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Data warehousing has evolved quite a bit in the past 20-25 years. There are a lot of repetitive tasks and automation's goal is to help users in front of repetition.
Generative AI is revolutionizing enterprise automation, enabling AI systems to understand context, make decisions, and act independently. At AWS, were using the power of models in Amazon Bedrock to drive automation of complex processes that have traditionally been challenging to streamline.
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of data pipelines.
There seems to be broad agreement that hyperautomation is the combination of Robotic Process Automation with AI. Using AI to discover tasks that can be automated also comes up frequently. It’s also hard to argue against the idea that we’ll see more automation in the future than we see now. Automating Office Processes.
For me, computer science is like solving a series of intricate puzzles with the added thrill of automation. KGs use semantics to represent data as real-world entities and relationships, making them more accurate than SQL databases, which focus on tables and columns. I started with BASIC and quickly moved on to assembly language.
Go to Definition: This feature lets users right-click on any Python variable or function to access its definition. This facilitates seamless navigation through the codebase, allowing users to locate and understand variable or function definitions quickly. This visual aid helps developers quickly identify and correct mistakes.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
This article offers a measured exploration of AI agents, examining their definition, evolution, types, real-world applications, and technical architecture. Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processing data, and taking action to achieve specified goals.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. First, we explore the option of in-context learning, where the LLM generates the requested metadata without documentation.
Processing terabytes or even petabytes of increasing complex omics data generated by NGS platforms has necessitated development of omics informatics. The next step in the data journey is performing analytics on the ingested data and streamlining the output in interoperability-ready formats with reproducible and scalable pipelines.
From basic driver assistance to fully autonomous vehicles(AVs) capable of navigating without human intervention, the progression is evident through the SAE Levels of vehicle automation. Different definitions of safety exist, from risk reduction to minimizing harm from unwanted outcomes.
In this blog post, we will delve into the concept of zero-based budgeting, exploring its definition, advantages, disadvantages, implementation steps, and tools needed. These tools provide a centralized platform for top-down and bottom-up budgeting creation, collaboration, scenario modeling, dataintegration, and reporting.
Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Basic Definitions Generative AI and predictive AI are two powerful types of artificial intelligence with a wide range of applications in business and beyond. Both types of AI use machine learning to learn from data, but they do so in different ways and have different goals. Let’s take a closer look.
The ecosystem has definitely matured, but the opportunity for us was to create a business focused only on Google Cloud engineering from the beginning. Lastly, the integration of generative AI is set to revolutionize business operations across various industries.
Summary: This article provides a comprehensive overview of data migration, including its definition, importance, processes, common challenges, and popular tools. By understanding these aspects, organisations can effectively manage data transfers and enhance their data management strategies for improved operational efficiency.
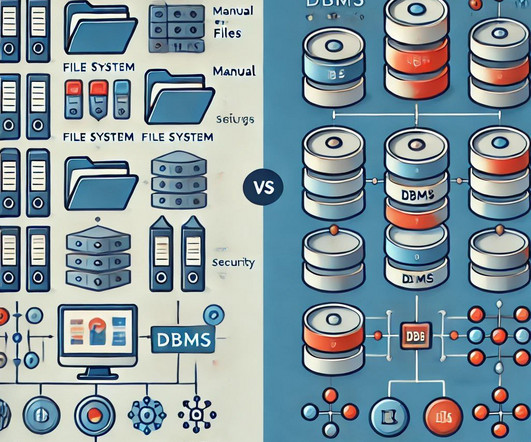
Summary: File systems store unstructured data in a hierarchical format, making them suitable for simple applications. In contrast, Database Management Systems (DBMS) manage structured data, providing advanced features like query processing, dataintegrity, and security. What is a File System? What is DBMS?
Relying on a credible Data Governance platform is paramount to seamlessly implementing Data Governance policies. These platforms are centralized and designed to manage data practices, facilitate collaboration among different stakeholders, and automate the Data Governance workflow. The same applies to data.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
In this blog, we have covered Data Management and its examples along with its benefits. What is Data Management? Before delving deeper into the process of Data Management and its significance, let’s scratch the surface of the Data Management definition. It can take place at the enterprise level or beyond.
The objective is to guide businesses, Data Analysts, and decision-makers in choosing the right tool for their needs. Whether you aim for comprehensive dataintegration or impactful visual insights, this comparison will clarify the best fit for your goals. Power BI : Provides dynamic dashboards and reporting tools.
Summary: This blog provides a comprehensive overview of data collection, covering its definition, importance, methods, and types of data. It also discusses tools and techniques for effective data collection, emphasising quality assurance and control.
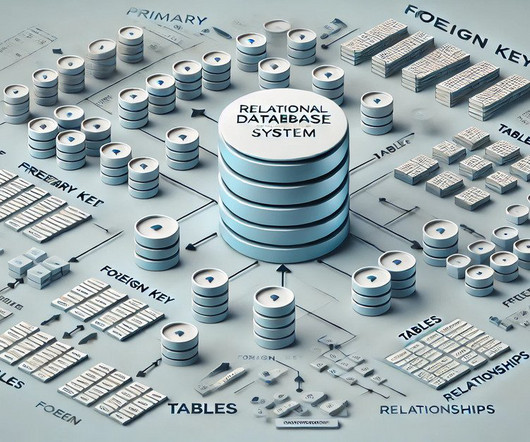
Summary: Relational Database Management Systems (RDBMS) are the backbone of structured data management, organising information in tables and ensuring dataintegrity. Introduction RDBMS is the foundation for structured data management. Introduction RDBMS is the foundation for structured data management.
Intuitive interface for data cleansing and enrichment. Integrates well with other components of the Talend ecosystem. Supports data governance and data lineage tracking. Provides scheduling and automation features. Informatica Data Quality Pros: Robust data profiling and standardization capabilities.
With the use of these tools, one can streamline the data modelling process. Moreover, these tools are designed to automate tasks like generating SQL scripts, documenting metadata and others. This automation boosts productivity and also saves time. And so, a robust data modelling tool should include a data dictionary feature.
Building Next-gen Recommendation Systems with Galileo.XAI Alberto De Lazzari | Chief Scientist | LARUS Business Automation Graph AI can achieve the state of the art on many machine learning tasks regarding relational data. That’s why we take a holistic approach to dataintegration that optimizes for agility, not fragmentation.
Data Collection Methods There are several methods for collecting data. Surveys and questionnaires can capture primary data directly from users. Automated systems can extract data from websites or applications. APIs provide structured data from other systems.
The primary purpose of a DBMS is to provide a systematic way to manage large amounts of data, ensuring that it is organised, accessible, and secure. By employing a DBMS, organisations can maintain dataintegrity, reduce redundancy, and streamline data operations, enabling more informed decision-making.
It allows you to combine data from multiple sources seamlessly, enhancing the flexibility of data manipulation tasks. Definition and Functionality The `append()` method is designed to append rows to the end of a DataFrame. Read Blogs: Decoding Python Automation and Scripting.
Recognising and addressing these duplicates is crucial for maintaining dataintegrity. Duplicates often occur in various scenarios: Data Entry Errors: Repeatedly entering the same data by mistake. Import Processes: When importing data from multiple sources, overlaps may occur. Definition, Types & How to Create.
Feature Store Modeling : the library easily provides everything you need to process and load data to your Feature Store. Continuous Machine Learning (CML) is an open-source CLI tool for implementing continuous integration & delivery (CI/CD) with a focus on MLOps. Do you have legacy notebooks? the prompt.
Mikiko Bazeley: You definitely got the details correct. I definitely don’t think I’m an influencer. It will store the features (including definitions and values) and then serve them. It’s almost like a very specialized data storage solution. And so what we do is version the definitions.
Purpose of Count in Excel The primary purpose of the COUNT function is to provide a quick and efficient way to quantify numerical data. By automating the counting process, the COUNT function enables users to focus on more complex aspects of Data Analysis, enhancing productivity and accuracy in their work.
Routine tasks Automation AI CRMs are designed to automate routine tasks, such as customer behavior analysis, data entry, customer follow-up emails, delivery status, sales entries, etc. Automation saves time while allowing teams to focus on strategic planning and innovation.
Saket Saurabh , CEO and Co-Founder of Nexla, is an entrepreneur with a deep passion for data and infrastructure. He is leading the development of a next-generation, automateddata engineering platform designed to bring scale and velocity to those working with data.
They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself. Metadata details the source of the data, its definition, and how it relates to other data points within the warehouse.
Their primary role in telemedicine and remote care is to enhance healthcare delivery by providing clinicians with accurate, data-driven insights and improving patient engagement through automated digital assistants. Another major challenge is managing the vast amount of data generated in healthcare.
Choose based on your need for granularity or speed to enhance performance and maintain dataintegrity. Introduction SQL, or Structured Query Language , is the backbone of modern database management , enabling efficient data manipulation and retrieval. Use TRUNCATE only when you’re sure the data is no longer needed.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content