This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
This article was published as a part of the DataScience Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and dataintegration service which allows you to create a data-driven workflow. In this article, I’ll show […].
Fermata , a trailblazer in datascience and computer vision for agriculture, has raised $10 million in a Series A funding round led by Raw Ventures. Key Features of Croptimus Automated Pest and Disease Detection: Identifies issues like aphids, spider mites, powdery mildew, and mosaic virus before they become critical.
Artificial Intelligence (AI) stands at the forefront of transforming data governance strategies, offering innovative solutions that enhance dataintegrity and security. In this post, let’s understand the growing role of AI in data governance, making it more dynamic, efficient, and secure.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with DataIntegrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. The data governance capability of a data fabric focuses on the collection, management and automation of an organization’s data. Dataintegration.
Serve: Data products are discoverable and consumed as services, typically via a platform. Serve : Build cloud services for data products through automation and platform service technology so they can be operated securely at global scale. Doing so can increase the quality of dataintegrated into data products.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. What initially attracted you to computer science? Data warehousing has evolved quite a bit in the past 20-25 years. We have brought all of those within our product.
AI platforms offer a wide range of capabilities that can help organizations streamline operations, make data-driven decisions, deploy AI applications effectively and achieve competitive advantages. AutoML tools: Automated machine learning, or autoML, supports faster model creation with low-code and no-code functionality.
This post demonstrates how to build a chatbot using Amazon Bedrock including Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock , within an automated solution. Solution overview In this post, we use publicly available data, encompassing both unstructured and structured formats, to showcase our entirely automated chatbot system.
Here comes the role of Data Mining. Read this blog to know more about DataIntegration in Data Mining, The process encompasses various techniques that help filter useful data from the resource. Moreover, dataintegration plays a crucial role in data mining.
Data scientists often spend up to 80% of their time on data engineering in datascience projects. Objective of Data Engineering: The main goal is to transform raw data into structured data suitable for downstream tasks such as machine learning.
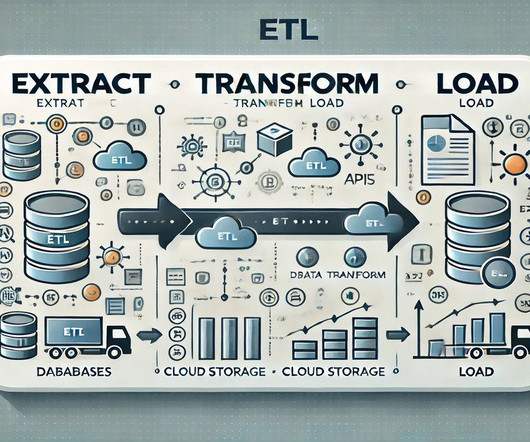
Summary: Selecting the right ETL platform is vital for efficient dataintegration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline dataintegration processes.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
Summary: The DataScience and Data Analysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Understanding their life cycles is critical to unlocking their potential.
Dataintegration in different spectrums of life highlights its growing significance. It has become a driving force of transformation, and so a career in DataScience is flourishing. The role of DataScience is not just limited to the IT domain. Why Should You Prepare for DataScience in High School?
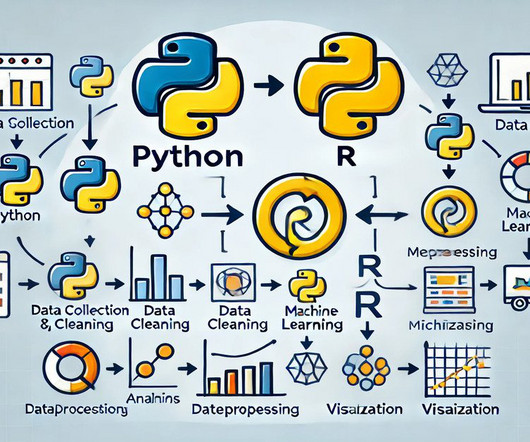
Summary : Combining Python and R enriches DataScience workflows by leveraging Python’s Machine Learning and data handling capabilities alongside R’s statistical analysis and visualisation strengths. Python excels in Machine Learning, automation, and data processing, while R shines in statistical analysis and visualisation.
There seems to be broad agreement that hyperautomation is the combination of Robotic Process Automation with AI. Using AI to discover tasks that can be automated also comes up frequently. It’s also hard to argue against the idea that we’ll see more automation in the future than we see now. Automating Office Processes.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Let’s unlock the power of ETL Tools for seamless data handling.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
The technology provides automated, improved machine-learning techniques for fraud identification and proactive enforcement to reduce fraud and block rates. Fynt AI Fynt AI is an AI automation solution developed primarily for corporate finance departments. It is based on adjustable and explainable AI technology.
In June 2024, Databricks made three significant announcements that have garnered considerable attention in the datascience and engineering communities. These announcements focus on enhancing user experience, optimizing data management, and streamlining data engineering workflows.
They excel at managing structured data and supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions. Scalability: Relational databases can scale vertically by upgrading hardware, but horizontal scaling can be more challenging due to the need to maintain dataintegrity and relationships.
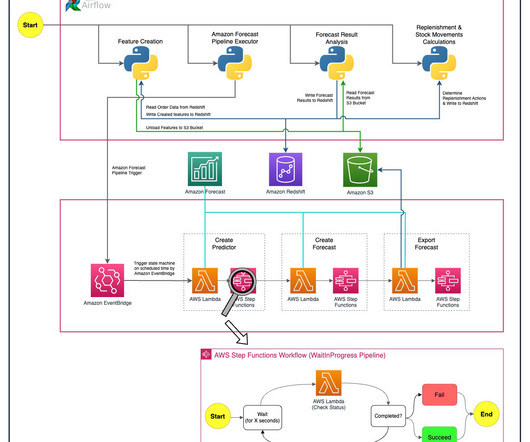
Additionally, for insights on constructing automated workflows and crafting machine learning pipelines, you can explore AWS Step Functions for comprehensive guidance. He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager. She has 12 years of software development and architecture experience.
Handling Large Data Volumes: Companies need scalable storage systems and cloud-based platforms to store and process massive amounts of data. Cloud services like AWS and Google Cloud help businesses manage their data efficiently. Businesses need strong data management strategies to merge and organise this data correctly.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. As previously mentioned, a data fabric is one such architecture.
These technologies include the following: Data governance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security. It is also important to establish data quality standards and strict access controls.
Overview of solution Five people from Getir’s datascience team and infrastructure team worked together on this project. He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager. We used GPU jobs that help us run jobs that use an instance’s GPUs.
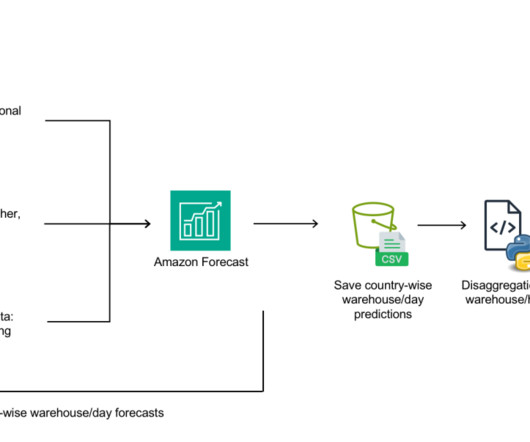
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. Forecast automates much of the time-series forecasting process, enabling you to focus on preparing your datasets and interpreting your predictions.
Data gathering, pre-processing, modeling, and deployment are all steps in the iterative process of predictive analytics that results in output. We can automate the procedure to deliver forecasts based on new data continuously fed throughout time. The business offers hundreds of tools for different industries.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
This is due to a deep disconnect between data engineering and datascience practices. Historically, our space has perceived streaming as a complex technology reserved for experienced data engineers with a deep understanding of incremental event processing.
DataScience is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A Data Scientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
Where DataScience, STEM, Business, & Sales Professionals Find Work If you’re looking to find work in STEM, datascience, or business, use this guide to see where others have found work in related roles. Top DataScience and AI News: May 2023 From StableVicuna to Midjourney 5.1,
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like Machine Learning. These tools automate the process, making it faster and more accurate.
Moreover, ETL ensures that the data is transformed into a consistent format during the transformation phase. This step is vital for maintaining dataintegrity and quality. Organisations can derive meaningful insights that drive business strategies by cleaning and enriching the data.
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in DataScience using Microsoft Azure. Integration: Seamlessly integrates with popular DataScience tools and frameworks, such as TensorFlow and PyTorch.
The Snorkel advantage for claims processing Snorkel offers a data-centric AI framework that insurance providers can use to generate high-quality training data for ML models and create custom models to streamline claims processing. See what Snorkel can do to accelerate your datascience and machine learning teams.
Research and new offerings in AI fuel the field of datascience. Despite this, over 85% of DataScience Pilots remain pilots and do not make it to the production stage. That’s why we take a holistic approach to dataintegration that optimizes for agility, not fragmentation.
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. So get your pass today, and keep yourself ahead of the curve.
Organisations often undertake data migration during system upgrades, consolidations, or when adopting new technologies. The primary goal is to ensure that data is accurately transferred and remains usable in the new environment. It can be complex, involving various challenges such as dataintegrity, compatibility, and downtime.
The Snorkel advantage for claims processing Snorkel offers a data-centric AI framework that insurance providers can use to generate high-quality training data for ML models and create custom models to streamline claims processing. See what Snorkel can do to accelerate your datascience and machine learning teams.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content