This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table Search and Filtering: Integrated search and filtering functionalities allow users to find specific columns or values and filter data to spot trends and identify essential values. Enhanced Python Features: New Python coding capabilities include an interactive debugger, error highlighting, and enhanced code navigation features.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Prerequisites To follow along with this post, you should have the following prerequisites: Python version greater than 3.9 AWS CDK version 2.0
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
You can implement this workflow in Forecast either from the AWS Management Console , the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks , or via automation solutions. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
Objective of Data Engineering: The main goal is to transform raw data into structured data suitable for downstream tasks such as machine learning. This involves a series of semi-automated or automated operations implemented through data engineering pipeline frameworks.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training.
Automation levels The SAE International (formerly called as Society of Automotive Engineers) J3016 standard defines six levels of driving automation, and is the most cited source for driving automation. This ranges from Level 0 (no automation) to Level 5 (full driving automation), as shown in the following table.
The ML components for dataingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. All steps are run in an automated manner after the pipeline has been run.
Dataingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The dataingestion and extraction component ingests and extracts content from these unstructured documents.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for data labeling, data versioning, data augmentation, and integration with popular data storage systems.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from data preparation and training to model deployment as automated workflows. Ingest the prepared data into the feature group by using the Boto3 SDK.
This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). Initializes the OpenSearch Service client using the Boto3 Python library. We use the streamlit Python package to create a front-end illustration for this application.
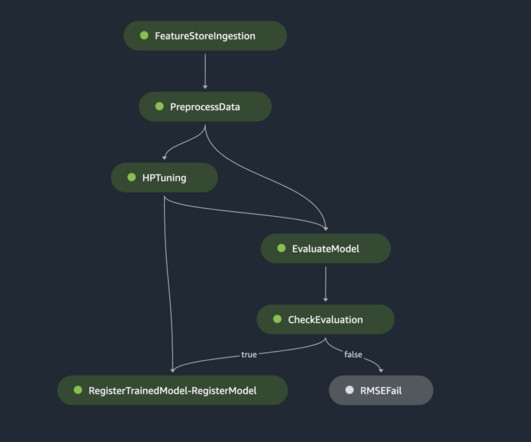
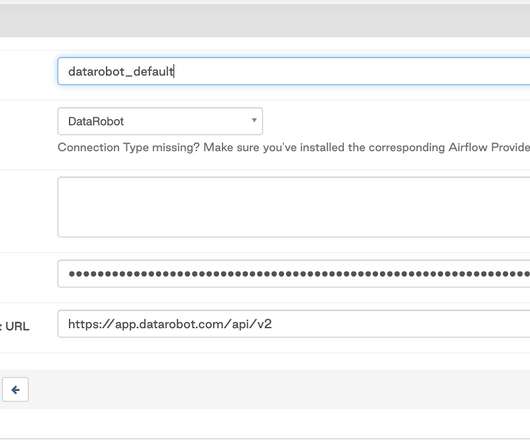
There are multiple DataRobot operators and sensors that automate the DataRobot ML pipeline steps. The DataRobot provider for Apache Airflow is a Python package built from source code available in a public GitHub repository and published in PyPi (The Python Package Index). DataRobot Python API Client >= 2.27.1.
To easily provide users with a large repository of relevant results, the solution should provide an automated way of searching through trusted sources. With an understanding of the problem and solution, the subsequent sections dive into how to automatedata sourcing through the crawling of architecture diagrams from credible sources.
Recommended How to Solve the DataIngestion and Feature Store Component of the MLOps Stack Read more A unified architecture for ML systems One of the challenges in building machine-learning systems is architecting the system. One of the core principles of MLOps is automation. All of them are written in Python.
ETL also enhances data quality and consistency by performing necessary data cleansing and validation during the transformation stage. This ensures that the data loaded into the data warehouse is reliable and ready for analysis. Its cloud-based services allow for scalability and flexibility in managing data.
These skills enable professionals to leverage Azure’s cloud technologies effectively and address complex data challenges. Below are the essential skills required for thriving in this role: Programming Proficiency: Expertise in languages such as Python or R for coding and data manipulation.
As stated above, data pipelines represent the backbone of modern data architecture. These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Web Scraping: Automated extraction from websites using scripts or specialised tools.
.” – Redhat Basic I/O flow in streaming data processing | Source The streaming processing engine does not just get the data from one place to another, but it transforms the data as it passes through. A streaming data pipeline is an enhanced version which is able to handle millions of events in real-time at scale.
As the volume of data keeps increasing at an accelerated rate, these data tasks become arduous in no time leading to an extensive need for automation. This is what data processing pipelines do for you. Data Transformation : Putting data in a standard format post cleaning and validation steps.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines.
Second, the platform gives data science teams the autonomy to create accounts, provision ML resources and access ML resources as needed, reducing resource constraints that often hinder their work. You can choose which option to use depending on your setup.
The pipelines let you orchestrate the steps of your ML workflow that can be automated. The orchestration here implies that the dependencies and data flow between the workflow steps must be completed in the proper order. Reduce the time it takes for data and models to move from the experimentation phase to the production phase.
Efficiency: Pipelines automate repetitive tasks, reducing manual intervention and saving time. A typical pipeline may include: DataIngestion: The process begins with ingesting raw data from different sources, such as databases, files, or APIs. We will use Python and the popular Scikit-learn.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA platform is used through complier directives and extensions to standard languages, such as the Python cuNumeric library.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment. Architecture overview Our MLOps architecture is designed to automate and monitor all stages of the ML lifecycle. Saurabh Gupta is a Principal Engineer at Zeta Global.
It should be able to version the project assets of your data scientists, such as the data, the model parameters, and the metadata that comes out of your workflow. Automation You want the ML models to keep running in a healthy state without the data scientists incurring much overhead in moving them across the different lifecycle phases.
Prioritize Data Quality Implement robust data pipelines for dataingestion, cleaning, and transformation. Use tools like Apache Airflow to orchestrate these pipelines and ensure consistent data quality for model training and production use.
The Widespread Adoption of Open DataScience The use of open source data science tools has absolutely explodedwere talking a whopping 650% growth over the past five years. Additionally, a clear majority of current projects ( 85% to be exact) leverage open-source programming languages like Python and R rather than proprietary options.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
This content builds on posts such as Deploy a Slack gateway for Amazon Bedrock by adding integrations to Amazon Bedrock Knowledge Bases and Amazon Bedrock Guardrails, and the Bolt for Python library to simplify Slack message acknowledgement and authentication requirements.
Regardless of the models used, they all include data preprocessing, training, and inference over several billions of records containing weekly data spanning multiple years and markets to produce forecasts. A fully automated production workflow The MLOps lifecycle starts with ingesting the training data in the S3 buckets.
Generative AI is used in various use cases, such as content creation, personalization, intelligent assistants, questions and answers, summarization, automation, cost-efficiencies, productivity improvement assistants, customization, innovation, and more. The agent returns the LLM response to the chatbot UI or the automated process.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content