This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How Prescriptive AI Transforms Data into Actionable Strategies Prescriptive AI goes beyond simply analyzing data; it recommends actions based on that data. While descriptive AI looks at past information and predictive AI forecasts what might happen, prescriptive AI takes it further.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Designed to track and react to data changes as they happen, Drasi operates continuously. Unlike batch-processing systems, it does not wait for intervals to process information. Understanding Drasi Drasi is an advanced event-driven architecture powered by Artificial Intelligence (AI) and designed to handle real-time data changes.
It is no longer sufficient to control data by restricting access to it, and we should also track the use cases for which data is accessed and applied within analytical and operational solutions. Moreover, data is often an afterthought in the design and deployment of gen AI solutions, leading to inefficiencies and inconsistencies.
The list of challenges is long: cloud attack surface sprawl, complex application environments, information overload from disparate tools, noise from false positives and low-risk events, just to name a few. The average cost of a data breach set a new record in 2023 of USD 4.45
Amazon Bedrock Knowledge Bases gives foundation models (FMs) and agents contextual information from your company’s private data sources for Retrieval Augmented Generation (RAG) to deliver more relevant, accurate, and customized responses. The LangChain AI assistant retrieves the conversation history from DynamoDB.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
“If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. For more information, refer to Training Predictors.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Rockets legacy data science architecture is shown in the following diagram. Data Storage and Processing: All compute is done as Spark jobs inside of a Hadoop cluster using Apache Livy and Spark.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. It has been trained on a wide-ranging corpus of text data to understand various contexts and nuances of language. The format of the recordings must be either.mp4,mp3, or.wav.
This deployment guide covers the steps to set up an Amazon Q solution that connects to Amazon Simple Storage Service (Amazon S3) and a web crawler data source, and integrates with AWS IAM Identity Center for authentication. An AWS CloudFormation template automates the deployment of this solution.
Quantum provides end-to-end data solutions that help organizations manage, enrich, and protect unstructured data, such as video and audio files, at scale. Their technology focuses on transforming data into valuable insights, enabling businesses to extract value and make informed decisions.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project. Sign up here!
This multi-interface, RAG-powered approach not only strives to meet the flexibility demands of modern users, but also fosters a more informed and engaged user base, ultimately maximizing the assistants effectiveness and reach. Additionally, we use text files uploaded to an S3 bucket that is accessible through an Amazon CloudFront link.
Forrester’s 2022 Total Economic Impact Report for Data Management highlights the impact Db2 and the IBM data management portfolio is having for customers: Return on investment (ROI) of 241% and payback <6 months. Both services offer independent compute and storage scaling, high availability, and automated DBA tasks.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. After being configured, an agent builds the prompt and augments it with your company-specific information to provide responses back to the user in natural language. Double-check all entered information for accuracy.
RAG models first retrieve relevant information from a large corpus of text and then use a FM to synthesize an answer based on the retrieved information. Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models. Choose Sync to initiate the dataingestion job.
RAG models retrieve relevant information from a large corpus of text and then use a generative language model to synthesize an answer based on the retrieved information. Solution overview The solution provides an automated end-to-end deployment of a RAG workflow using Knowledge Bases for Amazon Bedrock.
They implement landing zones to automate secure account creation and streamline management across accounts, including logging, monitoring, and auditing. One way to mitigate LLMs from giving incorrect information is by using a technique known as Retrieval Augmented Generation (RAG).
This allows you to create rules that invoke specific actions when certain events occur, enhancing the automation and responsiveness of your observability setup (for more details, see Monitor Amazon Bedrock ). With this information, you can identify optimization opportunities, such as scaling down under-utilized resources.
Automation levels The SAE International (formerly called as Society of Automotive Engineers) J3016 standard defines six levels of driving automation, and is the most cited source for driving automation. This ranges from Level 0 (no automation) to Level 5 (full driving automation), as shown in the following table.
Rather than using paper records, data is now collected and stored using digital tools. However, even digital information has to be stored somewhere. While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data.
Parsing and transforming different types of documents—ranging from PDFs to Word files—for machine learning tasks can be tedious, often leading to information loss or requiring extensive manual intervention. Meet MegaParse : an open-source tool for parsing various types of documents for LLM ingestion. Unstructured with Check Table 0.77
In order analyze the calls properly, Principal had a few requirements: Contact details: Understanding the customer journey requires understanding whether a speaker is an automated interactive voice response (IVR) system or a human agent and when a call transfer occurs between the two.
Customers across all industries run IDP workloads on AWS to deliver business value by automating use cases such as KYC forms, tax documents, invoices, insurance claims, delivery reports, inventory reports, and more. Effectively manage your data and its lifecycle Data plays a key role throughout your IDP solution.
Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data. The AI assistant provides answers along with links that point directly to the data sources.
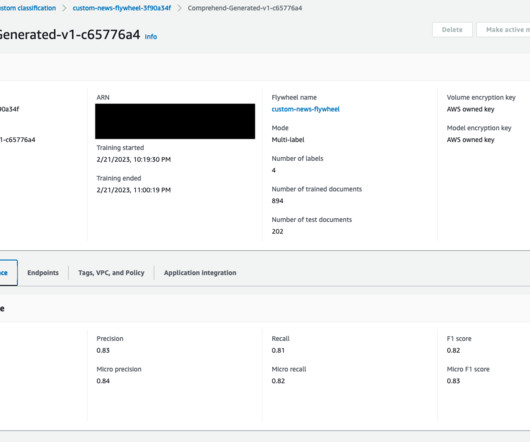
It helps you extract information by recognizing sentiments, key phrases, entities, and much more, allowing you to take advantage of state-of-the-art models and adapt them for your specific use case. An Amazon Comprehend flywheel automates this ML process, from dataingestion to deploying the model in production.
By exploring these challenges, organizations can recognize the importance of real-time forecasting and explore innovative solutions to overcome these hurdles, enabling them to stay competitive, make informed decisions, and thrive in today’s fast-paced business environment. For more information, refer to the following resources.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. Choose the car-data-ingestion-pipeline.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automatedata flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
The ML components for dataingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Manager Data Science at Marubeni Power International.
Rather than requiring your data science and IT teams to build and maintain AI models, you can use pre-trained AI services that can automate tasks for you. How to manage the document and its extracted information in the solution is the key to data consistency, security, and privacy.
Combining healthcare-specific LLMs along with a terminology service and scalable dataingestion pipelines, it excels in complex queries and is ideal for organizations seeking OMOP data enrichment.
Codify Operations for Efficiency and Reproducibility By performing operations as code and incorporating automated deployment methodologies, organizations can achieve scalable, repeatable, and consistent processes. By centralizing datasets within the flywheel’s dedicated Amazon S3 data lake, you ensure efficient data management.
To easily provide users with a large repository of relevant results, the solution should provide an automated way of searching through trusted sources. Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user.
The banking dataset contains information about bank clients such as age, job, marital status, education, credit default status, and details about the marketing campaign contacts like communication type, duration, number of contacts, and outcome of the previous campaign. A new data flow is created on the Data Wrangler console.
As the lifeline of the airports, a BHS is a linear asset that can exceed 34,000 meters in length (for a single airport) handling over 70 million bags annually, making it one of the most complex automated systems and a vital component of airport operations.
According to IDC , 83% of CEOs want their organizations to be more data-driven. Data scientists could be your key to unlocking the potential of the Information Revolution—but what do data scientists do? What Do Data Scientists Do? Data scientists drive business outcomes. Awareness and Activation.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project. Sign up here!
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









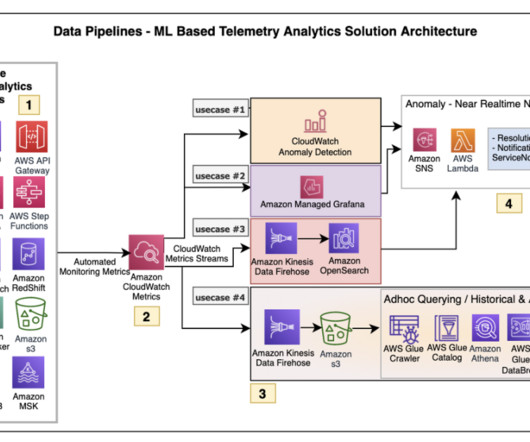









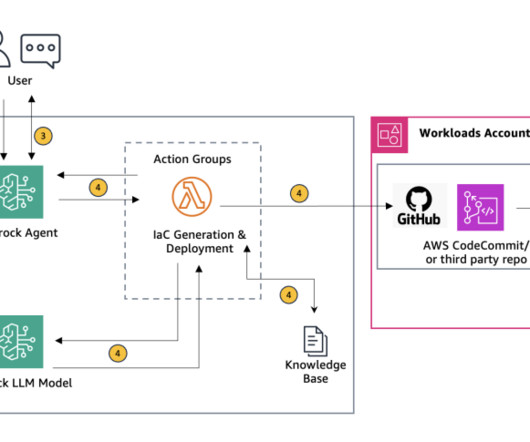


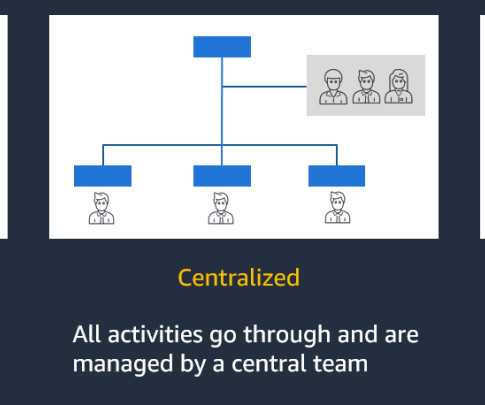






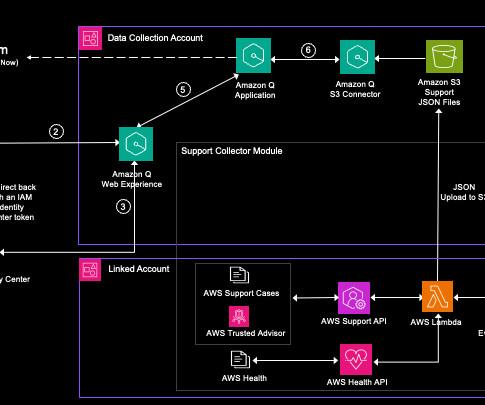

















Let's personalize your content