This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The operationalisation of data projects has been a key factor in helping organisations turn a data deluge into a workable digital transformation strategy, and DataOps carries on from where DevOps started. And everybody agrees that in production, this should be automated.” It’s all data driven,” Faruqui explains.
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. This created a challenge for data scientists to become productive.
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Mateusz Zaremba is a DevOps Architect at AWS Professional Services. Amazon Transcribe’s new ASR foundation model supports 100+ language variants.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps.
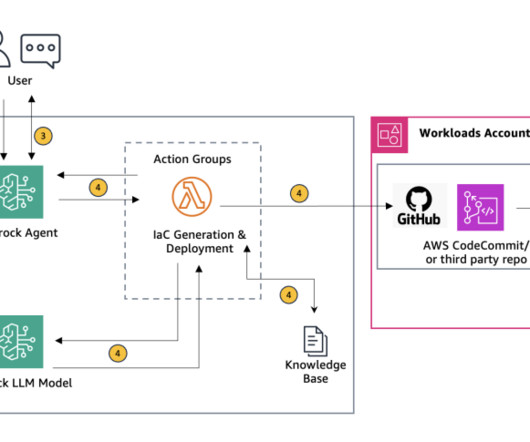
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. Select the KB and in the Data source section, choose Sync to begin dataingestion. When dataingestion completes, a green success banner appears if it is successful.
Automation of building new projects based on the template is streamlined through AWS Service Catalog , where a portfolio is created, serving as an abstraction for multiple products. The model will be approved by designated data scientists to deploy the model for use in production.
That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in. All steps are run in an automated manner after the pipeline has been run. This step produces an expanded report containing the model’s metrics.
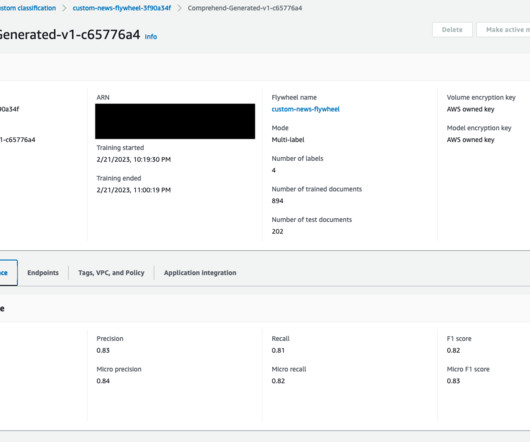
MLOps focuses on the intersection of data science and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. An Amazon Comprehend flywheel automates this ML process, from dataingestion to deploying the model in production.
This includes AWS Identity and Access Management (IAM) or single sign-on (SSO) access, security guardrails, Amazon SageMaker Studio provisioning, automated stop/start to save costs, and Amazon Simple Storage Service (Amazon S3) set up. MLOps engineering – Focuses on automating the DevOps pipelines for operationalizing the ML use case.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Prioritize Data Quality Implement robust data pipelines for dataingestion, cleaning, and transformation. Use tools like Apache Airflow to orchestrate these pipelines and ensure consistent data quality for model training and production use.
It should be able to version the project assets of your data scientists, such as the data, the model parameters, and the metadata that comes out of your workflow. Automation You want the ML models to keep running in a healthy state without the data scientists incurring much overhead in moving them across the different lifecycle phases.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production.
The first part is all about the core TFX pipeline handling all the steps from dataingestion to model deployment. The last one is about automation and implementing CI/CD using GitHub Actions. TFX Pipeline The ML pipeline is written entirely in TFX, from dataingestion to model deployment. Hub service.
Second, the platform gives data science teams the autonomy to create accounts, provision ML resources and access ML resources as needed, reducing resource constraints that often hinder their work. Alberto Menendez is a DevOps Consultant in Professional Services at AWS. You can choose which option to use depending on your setup.
The pipelines let you orchestrate the steps of your ML workflow that can be automated. The orchestration here implies that the dependencies and data flow between the workflow steps must be completed in the proper order. Reduce the time it takes for data and models to move from the experimentation phase to the production phase.
Regardless of the models used, they all include data preprocessing, training, and inference over several billions of records containing weekly data spanning multiple years and markets to produce forecasts. A fully automated production workflow The MLOps lifecycle starts with ingesting the training data in the S3 buckets.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content