This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Go to Definition: This feature lets users right-click on any Python variable or function to access its definition. This facilitates seamless navigation through the codebase, allowing users to locate and understand variable or function definitions quickly. This visual aid helps developers quickly identify and correct mistakes.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps.
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. This is made possible by automating tedious, repetitive MLOps tasks as part of the template.
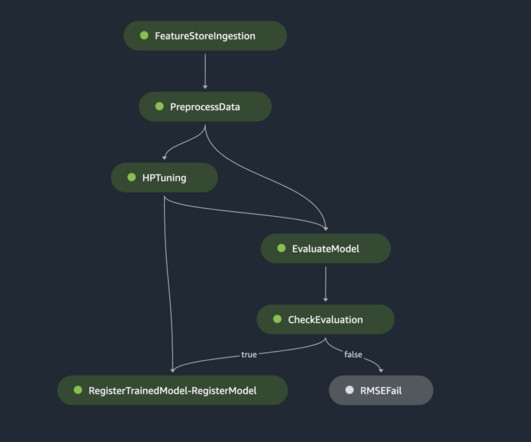
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. Choose the car-data-ingestion-pipeline.
The ecosystem has definitely matured, but the opportunity for us was to create a business focused only on Google Cloud engineering from the beginning. This is just the beginning of the age of AI in everyday life for organizations running on Google Cloud and it’s definitely where we see a lot of momentum.
Other steps include: dataingestion, validation and preprocessing, model deployment and versioning of model artifacts, live monitoring of large language models in a production environment, monitoring the quality of deployed models and potentially retraining them. Of course, the desired level of automation is different for each project.
Codify Operations for Efficiency and Reproducibility By performing operations as code and incorporating automated deployment methodologies, organizations can achieve scalable, repeatable, and consistent processes. By centralizing datasets within the flywheel’s dedicated Amazon S3 data lake, you ensure efficient data management.
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from data preparation and training to model deployment as automated workflows. Ingesting features into the feature store contains the following steps: Define a feature group and create the feature group in the feature store.
Integrating advanced tools and services simplifies how organisations ingest, process, and analyse data for actionable insights. With an estimated market share of 30.03% , Microsoft Fabric is a preferred choice for businesses seeking efficient and scalable data solutions.
Relying on a credible Data Governance platform is paramount to seamlessly implementing Data Governance policies. These platforms are centralized and designed to manage data practices, facilitate collaboration among different stakeholders, and automate the Data Governance workflow. The same applies to data.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. API Integration: Accessing data through Application Programming Interfaces (APIs) provided by external services. Frequently Asked Questions What is a Data Pipeline?
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production.
Features (also called alphas , signals , or predictors ) are statistical representations of the data, which can then be used in downstream model building. A current trend in the FSI prediction space is the large-scale automation of dataset ingestion, curation, processing, feature extraction, feature combination, and model building.
Routine tasks Automation AI CRMs are designed to automate routine tasks, such as customer behavior analysis, data entry, customer follow-up emails, delivery status, sales entries, etc. Automation saves time while allowing teams to focus on strategic planning and innovation.
It should be able to version the project assets of your data scientists, such as the data, the model parameters, and the metadata that comes out of your workflow. Automation You want the ML models to keep running in a healthy state without the data scientists incurring much overhead in moving them across the different lifecycle phases.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment. Architecture overview Our MLOps architecture is designed to automate and monitor all stages of the ML lifecycle. The following figure shows schema definition and model which reference it.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content