This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A good place to start is refreshing the way organizations govern data, particularly as it pertains to its usage in generative AI solutions. For example: Validating and creating data protection capabilities : Dataplatforms must be prepped for higher levels of protection and monitoring.
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. Rockets legacy data science architecture is shown in the following diagram.
Successful hybrid cloud strategies require a unified control and management plane, enabling automated deployment of applications across various environments, comprehensive observability and improved cyber resiliency.
A long-standing partnership between IBM Human Resources and IBM Global Chief Data Office (GCDO) aided in the recent creation of Workforce 360 (Wf360), a workforce planning solution using IBM’s Cognitive Enterprise DataPlatform (CEDP). What is data quality? First they need to know if the data is accurate.
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps. IBM watsonx consists of the following: IBM watsonx.ai
The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion. Additionally, they aim to report corrected data from low-cost sensors, which requires information beyond specific pollutants.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a DataPlatform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Dataplatforms & Data Governance.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Oftentimes, this requires implementing a “hot” part of the initial dataingest, or landing zone where applications and users can work as fast as possible. Can you elaborate on the AI-enabled workflow management features and how they streamline data processes?
Google Cloud’s AI and machine learning services, including the new generative AI models, empower businesses to harness advanced analytics, automate complex processes, and enhance customer experiences. This led to inconsistent data standards and made it difficult for them to gain actionable insights.
Axfood has a structure with multiple decentralized data science teams with different areas of responsibility. Together with a central dataplatform team, the data science teams bring innovation and digital transformation through AI and ML solutions to the organization.
In order analyze the calls properly, Principal had a few requirements: Contact details: Understanding the customer journey requires understanding whether a speaker is an automated interactive voice response (IVR) system or a human agent and when a call transfer occurs between the two.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer dataplatform that simplifies the deployment and scaling of MongoDB databases in the cloud.
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like Machine Learning. These tools automate the process, making it faster and more accurate.
Whether you aim for comprehensive data integration or impactful visual insights, this comparison will clarify the best fit for your goals. Key Takeaways Microsoft Fabric is a full-scale dataplatform, while Power BI focuses on visualising insights. Data Activator : Automates workflows, making data-triggered actions possible.
As the volume of data keeps increasing at an accelerated rate, these data tasks become arduous in no time leading to an extensive need for automation. This is what data processing pipelines do for you. Data Transformation : Putting data in a standard format post cleaning and validation steps.
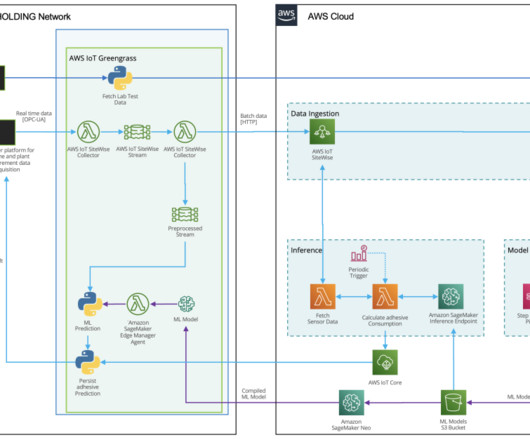
Quality prediction – The estimation of a quality variable on the basis of process variables for decision support or for automation. For example, how much kg/m 3 adhesive ingredient shall be ingested to achieve certain strength and elasticity. Two types of data sources exist for this use case.
Keeping track of how exactly the incoming data (the feature pipeline’s input) has to be transformed and ensuring that each model receives the features precisely how it saw them during training is one of the hardest parts of architecting ML systems. One of the core principles of MLOps is automation. What is a feature store?
Bulk Data Load Data migration to Snowflake can be a challenge. The solution provides Snowpipe for extended data loading; however, sometimes, it’s not the best option. There can be alternatives that expedite and automatedata flows. Therefore, quick dataingestion for instant use can be challenging.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production.
Tools range from dataplatforms to vector databases, embedding providers, fine-tuning platforms, prompt engineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. Monitoring Monitor model performance for data drift and model degradation, often using automated monitoring tools.
It should be able to version the project assets of your data scientists, such as the data, the model parameters, and the metadata that comes out of your workflow. Automation You want the ML models to keep running in a healthy state without the data scientists incurring much overhead in moving them across the different lifecycle phases.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Solution overview The code in the accompanying GitHub repo provided in this solution enables an automated deployment of Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and the required resources to integrate the Amazon Bedrock Knowledge Bases API with a Slack slash command assistant using the Bolt for Python library.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content