This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction The purpose of this project is to develop a Python program that automates the process of monitoring and tracking changes across multiple websites. We aim to streamline the meticulous task of detecting and documenting modifications in web-based content by utilizing Python.
Collecting this data can be time-consuming and prone to errors, presenting a significant challenge in data-driven industries. Traditionally, web scraping tools have been utilized to automate the process of dataextraction. Unlike traditional tools, this innovative solution allows users to describe the needed data.
These APIs allow companies to integrate natural language understanding, generation, and other AI-driven features into their applications, improving efficiency, enhancing customer experiences, and unlocking new possibilities in automation. Flash $0.00001875 / 1K characters $0.000075 / 1K characters $0.0000375 / 1K characters Gemini 1.5
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and dataextraction, among other skills. Versatile Toolset Exposure : Including Python, Java, TensorFlow, and Keras.
Data often comes in different formats depending on the source. These tools help standardize this data, ensuring consistency. Moreover, data integration tools can help companies save $520,000 annually by automating manual data pipeline creation. Fivetran also provides robust data security and governance.
Data often comes in different formats depending on the source. These tools help standardize this data, ensuring consistency. Moreover, data integration tools can help companies save $520,000 annually by automating manual data pipeline creation. Fivetran also provides robust data security and governance.
In this blog, we delve into the characteristics that define scripting languages, explore whether Python fits this classification, and provide examples to illustrate Python’s scripting capabilities. Rapid Prototyping : Python’s scripting capabilities facilitate quick prototyping and iterative development.
These tools offer a variety of choices to effectively extract, process, and analyze data from various web sources. Scrapy A powerful, open-source Python framework called Scrapy was created for highly effective web scraping and dataextraction.
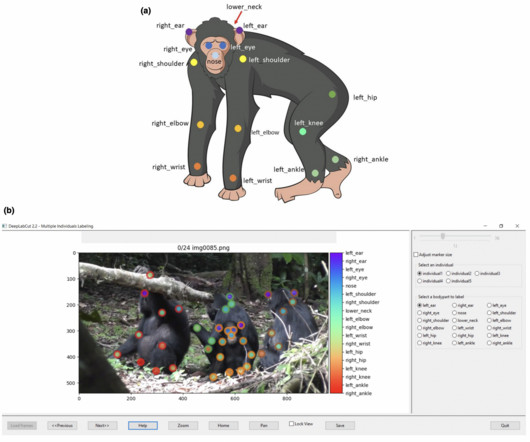
Video coding is preferred for collecting detailed behavioral data, but manually extracting information from extensive video footage is time-consuming. Machine learning has emerged as a solution, automatingdataextraction and improving efficiency while maintaining reliability.
Recognizing and adapting to these variations can be a complex task during dataextraction. To improve dataextraction, organizations often employ manual verification and validation processes, which increases the cost and time of the extraction process. python -m pip install amazon-textract-caller --upgrade !python
Most of these GPTs will help you automate some of your work as a programmer, while one will help you with your coding questions without giving you the answers right away or coding for you … You can find the firt article of these series here. Say I don’t know the difference between tuples and lists/dictionaries in Python.
Dataextraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data. It also automates tasks like information extraction and content categorization. positive, negative or neutral).
One of the key features of the o1 models is their ability to work efficiently across different domains, including natural language processing (NLP), dataextraction, summarization, and even code generation. o1 models also excel in tasks requiring detailed comprehension and information extraction from complex texts.
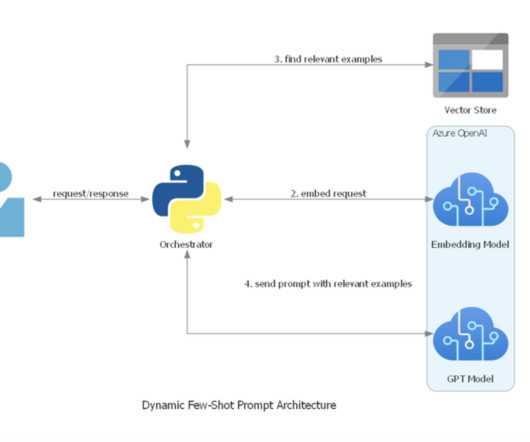
The few-shot approach enhances the model’s ability to perform diverse tasks, making it a powerful tool for applications ranging from text classification to summarization and dataextraction. The result is a highly efficient, scalable, and contextually aware model that can deliver high-quality outputs with minimal data.
It allows us to gather information from web pages and use it for various purposes, such as data analysis, research, or building applications. The GitHub Topics Scraper project automates the process of scraping these topics and retrieving relevant repository information.
Whether you want to automate research, extract insights from articles, or build AI-powered applications, this tutorial provides a robust and adaptable solution. It then scrapes the content of a specified webpage (in this case, Wikipedia’s Python programming language page) and extracts the data in Markdown format.
Keep these in mind as we discuss best practices: Automatically recover from failure – By monitoring your IDP workflow for key performance indicators (KPIs), you can run automation when a threshold is breached. Use automation to simulate different scenarios or recreate scenarios that led to failure before.
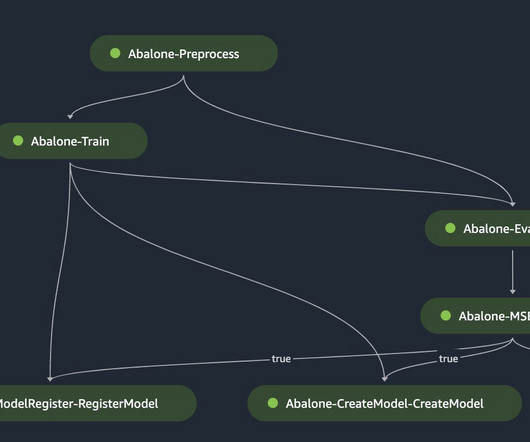
Amazon SageMaker Pipelines , a feature of Amazon SageMaker , is a purpose-built workflow orchestration service for ML that helps you automate end-to-end ML workflows at scale. You can run the following command from your notebook or terminal to install or upgrade the SageMaker Python SDK version to 2.162.0
The postprocessing component uses bounding box metadata from Amazon Textract for intelligent dataextraction. The postprocessing component is capable of extractingdata from complex, multi-format, multi-page PDF files with varying headers, footers, footnotes, and multi-column data.
Better performance and accurate answers for in-context document Q&A and entity extractions using an LLM. There are other possible document automation use cases where Layout can be useful. Extractive tasks refer to activities where the model identifies and extracts specific portions of the input text to construct a response.
Traditionally, the extraction of data from documents is manual, making it slow, prone to errors, costly, and challenging to scale. While the industry has been able to achieve some amount of automation through traditional OCR tools, these methods have proven to be brittle, expensive to maintain, and add to technical debt.
Summary: The ETL process, which consists of dataextraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Web crawling is the automated process of systematically browsing the internet to gather and index information from various web pages. How Web Scraping Works Target Selection : The first step in web scraping is identifying the specific web pages or elements from which data will be extracted. What is Web Crawling?
In this case, we’re going to use a different approach that will help us extractdata from websites by just telling what data we want to get. Once we see how this works, we’re gonna quickly create a GPT to automate all this. Here’s the data you should extract from the first item.
Healthcare NLP Display is an open-source python library for visualizing the generated results. This approach streamlines entity extraction, making it ideal for adapting to evolving research needs with minimal effort. The ability to quickly visualize the entities/relations/assertion statuses, etc.
As the volume of data keeps increasing at an accelerated rate, these data tasks become arduous in no time leading to an extensive need for automation. This is what data processing pipelines do for you. Let’s understand how the other aspects of a data pipeline help the organization achieve its various objectives.
We’ll need to provide the chunk data, specify the embedding model used, and indicate the directory where we want to store the database for future use. It involves selecting, transforming, and combining data attributes to extract meaningful information that can be used for analysis and prediction.
It enables analysis, visualization, diffing operations, pipeline automation, AutoML hyperparameter tuning, scheduling, parallel processing, and remote training. The package comprises data management, orchestration, deployment, ML pipeline management, and data processing. Guild AI The Apache 2.0 Ai-powered DVC family of tools.
The encoder processes the input data, extracting semantic representations, while the decoder generates the output based on the encoded information. Automated benchmarks evaluate model performance on specific tasks or capabilities by providing input samples and comparing model outputs against reference outputs. Highlights.
Arize’s automated model monitoring and observability platform allows ML teams to detect issues when they emerge, troubleshoot why they happened, and manage model performance. You will utilize the Python API for Neptune in this project. Users can automate hyperparameter tuning, debug training runs, log, compare experiments and organize.
Before we explore the examples, it’s crucial to confirm that you have the latest version of the SageMaker Python SDK. Sensitive dataextraction and redaction LLMs show promise for extracting sensitive information for redaction. We use Jupyter notebooks throughout this post.
Impact on Data Quality and Business Operations Using an inappropriate ETL tool can severely affect data quality. Poor data quality can lead to inaccurate business insights and decisions. Dataextraction, transformation, or loading errors can result in data loss or corruption.
Extraction with a multi-modal language model The architecture uses a multi-modal LLM to perform extraction of data from various multi-lingual documents. We specifically used the Rhubarb Python framework to extract JSON schema -based data from the documents.
See in the app Full screen preview All metadata in a single place with an experiment tracker (example in neptune.ai) Integrate bias checks into your CI/CD workflows If your team manages model training through CI/CD, incorporate the automated bias detection scripts (that have already been created) into each pipeline iteration.
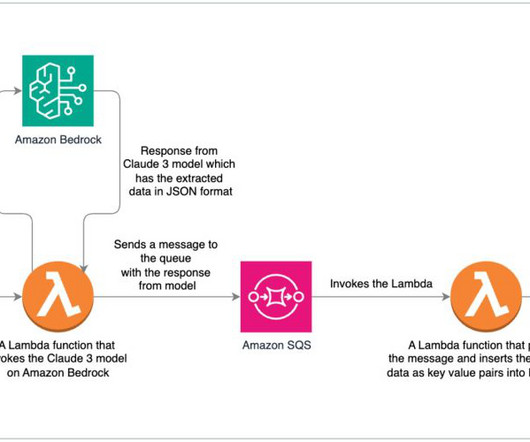
By infusing IDP solutions with generative AI capabilities, organizations can revolutionize their document processing workflows, achieving exceptional levels of automation and reliability. for the runtime, and leave the remaining settings as default. You can download the entire Lambda function code from invoke_bedrock_claude3.py.
Solution overview To personalize users’ feeds, we analyzed extensive historical data, extracting insights into features that include browsing patterns and interests. Model training Meesho used Amazon EMR with Apache Spark to process hundreds of millions of data points, depending on the model’s complexity.
Use case In this example of an insurance assistance chatbot, the customers generative AI application is designed with Amazon Bedrock Agents to automate tasks related to the processing of insurance claims and Amazon Bedrock Knowledge Bases to provide relevant documents. python invoke_bedrock_agent.py "What are the open claims?"
Photo by Nathan Dumlao on Unsplash Introduction Web scraping automates the extraction of data from websites using programming or specialized tools. Required for tasks such as market research, data analysis, content aggregation, and competitive intelligence. Below is a sample Python code.
Developers face significant challenges when using foundation models (FMs) to extractdata from unstructured assets. This dataextraction process requires carefully identifying models that meet the developers specific accuracy, cost, and feature requirements.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content