This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Moreover, Crawl4AI offers features such as user-agent customization, JavaScript execution for dynamic dataextraction, and proxy support to bypass web restrictions, enhancing its versatility compared to traditional crawlers. The tool then fetches web pages, following links and adhering to website policies like robots.txt.
Annotating transcripts with metadata such as timestamps, speaker labels, and emotional tone gives researchers a comprehensive understanding of the context and nuances of spoken interactions. Marvin also provides users with a PII Redaction model to automatically filter out personally identifiable information from the data.
The traditional approach of using human reviewers to extract the data is time-consuming, error-prone, and not scalable. In this post, we show how to automate the accounts payable process using Amazon Textract for dataextraction. You can visualize the indexed metadata using OpenSearch Dashboards.
The postprocessing component uses bounding box metadata from Amazon Textract for intelligent dataextraction. The postprocessing component is capable of extractingdata from complex, multi-format, multi-page PDF files with varying headers, footers, footnotes, and multi-column data.
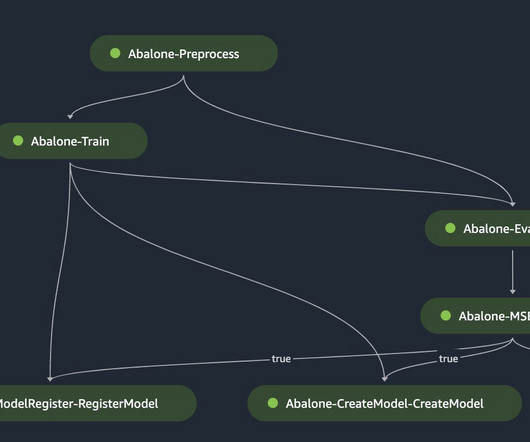
Amazon SageMaker Pipelines , a feature of Amazon SageMaker , is a purpose-built workflow orchestration service for ML that helps you automate end-to-end ML workflows at scale. MLOps tooling helps you repeatably and reliably build and simplify these processes into a workflow that is tailored for ML.
Extracting layout elements for search indexing and cataloging purposes. The contents of the LAYOUT_TITLE or LAYOUT_SECTION_HEADER , along with the reading order, can be used to appropriately tag or enrich metadata. Better performance and accurate answers for in-context document Q&A and entity extractions using an LLM.
In machine learning, experiment tracking stores all experiment metadata in a single location (database or a repository). Model hyperparameters, performance measurements, run logs, model artifacts, data artifacts, etc., Neptune AI ML model-building metadata may be managed and recorded using the Neptune platform.
Clinical data abstraction is a standard process in many hospitals and healthcare facilities, which requires enormous amounts of specialized work to extractdata from noisy and unstructured sources. Historically, there have been three major barriers to automating this process.
Web crawling is the automated process of systematically browsing the internet to gather and index information from various web pages. How Web Scraping Works Target Selection : The first step in web scraping is identifying the specific web pages or elements from which data will be extracted. What is Web Crawling?
The MLflow Tracking component has an API and UI that enable different logging metadata (such as parameters, code versions, metrics, and output files) and afterward viewing the outcomes. You can utilize Polyaxon UI or incorporate it with another board, such as TensorBoard, to display the logged metadata later. Guild AI The Apache 2.0
Impact on Data Quality and Business Operations Using an inappropriate ETL tool can severely affect data quality. Poor data quality can lead to inaccurate business insights and decisions. Dataextraction, transformation, or loading errors can result in data loss or corruption.
Sensitive dataextraction and redaction LLMs show promise for extracting sensitive information for redaction. In real-life applications, however, additional evaluation is often necessary to improve the reliability and safety of LLMs for handling confidential data.
The major functionalities of LabelBox are: – Labeling data across all data modalities – Data, metadata and model predictions – Improving data and models LightTag LightTag is a text annotation tool that manages and executes text annotation projects.
See in the app Full screen preview All metadata in a single place with an experiment tracker (example in neptune.ai) Integrate bias checks into your CI/CD workflows If your team manages model training through CI/CD, incorporate the automated bias detection scripts (that have already been created) into each pipeline iteration.
Understanding Data Warehouse Functionality A data warehouse acts as a central repository for historical dataextracted from various operational systems within an organization. DataExtraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
By taking advantage of advanced natural language processing (NLP) capabilities and data analysis techniques, you can streamline common tasks like these in the financial industry: Automatingdataextraction – The manual dataextraction process to analyze financial statements can be time-consuming and prone to human errors.
Use case In this example of an insurance assistance chatbot, the customers generative AI application is designed with Amazon Bedrock Agents to automate tasks related to the processing of insurance claims and Amazon Bedrock Knowledge Bases to provide relevant documents. PII Anonymization.
Photo by Nathan Dumlao on Unsplash Introduction Web scraping automates the extraction of data from websites using programming or specialized tools. Required for tasks such as market research, data analysis, content aggregation, and competitive intelligence. Including how to use LangChain and LLMs for web scraping!
Gladia's platform also enables real-time extraction of insights and metadata from calls and meetings, supporting key enterprise use cases such as sales assistance and automated customer support. A common challenge with unstructured data is that this critical information isnt readily accessibleit's buried within the transcript.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content