

How DPG Media uses Amazon Bedrock and Amazon Transcribe to enhance video metadata with AI-powered pipelines
AWS Machine Learning Blog
OCTOBER 16, 2024
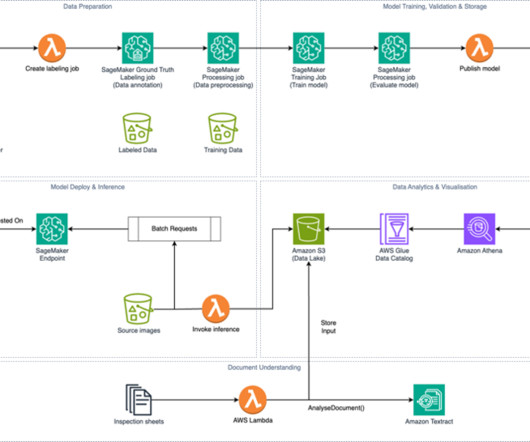
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.













































Let's personalize your content