This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ahead of AI & BigData Expo Europe , Han Heloir, EMEA gen AI senior solutions architect at MongoDB , discusses the future of AI-powered applications and the role of scalable databases in supporting generative AI and enhancing business processes. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
“If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got data ingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
Data often comes in different formats depending on the source. These tools help standardize this data, ensuring consistency. Moreover, data integration tools can help companies save $520,000 annually by automating manual data pipeline creation. Fivetran also provides robust data security and governance.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
Data often comes in different formats depending on the source. These tools help standardize this data, ensuring consistency. Moreover, data integration tools can help companies save $520,000 annually by automating manual data pipeline creation. Fivetran also provides robust data security and governance.
This involves a series of semi-automated or automated operations implemented through data engineering pipeline frameworks. ELT Pipelines: Typically used for bigdata, these pipelines extract data, load it into data warehouses or lakes, and then transform it.
Data warehousing has evolved quite a bit in the past 20-25 years. There are a lot of repetitive tasks and automation's goal is to help users in front of repetition. We already know patterns- the patterns have been around for such a long time and the patterns are repetitive. Why is Astera a superior solution than competing platforms?
The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems. To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. Amazon Bedrock Agents streamlines workflows and automates repetitive tasks.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. How is Data Engineering Different from Data Science?
Extract, Transform, and Load are referred to as ETL. ETL is the process of gathering data from numerous sources, standardizing it, and then transferring it to a central database, data lake, data warehouse, or data store for additional analysis. Involved in each step of the end-to-end ETL process are: 1.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more. We use the following prompt: Human: Your job is to act as an expert on ETL pipelines.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations.
This allows data engineers, data scientists, business analysts, and other data practitioners working from the same tool to quickly understand how an application works, seamlessly review each others work, and make the required changes. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Summary: Apache NiFi is a powerful open-source data ingestion platform design to automatedata flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. What is Apache NiFi?
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like Machine Learning. These tools automate the process, making it faster and more accurate.
You may use OpenRefine for more than just data cleaning; it can also help you find mistakes and outliers that could compromise your data’s quality. Apache Griffin Apache Griffin is an open-source data quality tool that aims to enhance bigdata processes. It has a quick and clear grasp of data quality issues.
Architecture overview Our MLOps architecture is designed to automate and monitor all stages of the ML lifecycle. An example direct acyclic graph (DAG) might automatedata ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. The serverless batch pipeline architecture we presented offers a scalable solution for automating this process across large enterprise knowledge bases. 201% $12.2B
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
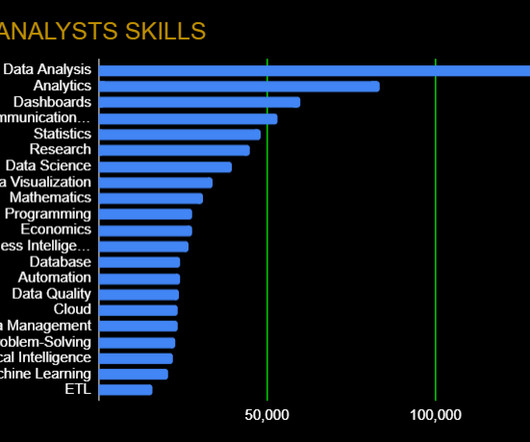
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format. Data Quality Management : Ensures that the integrated data is accurate, consistent, and reliable for analysis. They store structured data in a format that facilitates easy access and analysis.
Data gathering, pre-processing, modeling, and deployment are all steps in the iterative process of predictive analytics that results in output. We can automate the procedure to deliver forecasts based on new data continuously fed throughout time. This tool’s user-friendly UI consistently receives acclaim from users.
As the volume of data keeps increasing at an accelerated rate, these data tasks become arduous in no time leading to an extensive need for automation. This is what data processing pipelines do for you. Let’s understand how the other aspects of a data pipeline help the organization achieve its various objectives.
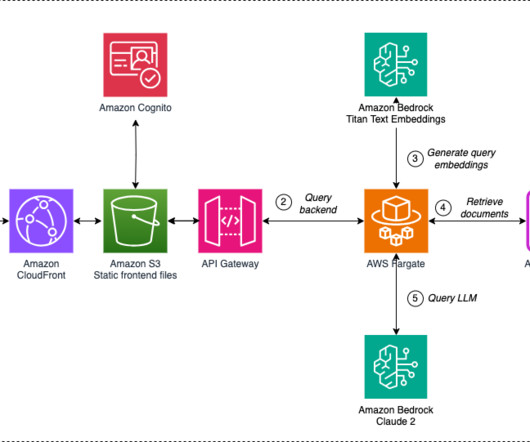
About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química. He has more than 8 years of experience with bigdata and machine learning projects in financial, retail, energy, and chemical industries. The following diagram illustrates this architecture.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks. MongoDB, developed by MongoDB Inc.,
The pay-per-use cloud-based data warehousing technologies are quick, effective, and highly scalable. Importance of Data Warehouse To meet the continuously shifting needs of business, modern data warehousing solutions automate the repetitive tasks of designing, developing, and putting in place a data warehouse architecture.
By automating repetitive tasks and generating boilerplate code, these tools free up time for engineers to focus on more complex, creative aspects of software development. Well, it is offering a way to automate the time-consuming process of writing and running tests. Just keep in mind, that this shouldn’t replace the human element.
Such success stories have largely depended on Data Engineering processes. This article explores how data engineering can improve Customer 360 initiatives for AWS data engineering , bigdata engineering, and data analytics companies. Data Storage: Keeping altered data within Azure Synapse’s enrichment layer.
[link] Tables The table in GCP BigQuery is a collection of rows and columns that can store and manage massive amounts of data. It’s a managed, cloud-based service that’s designed to handle bigdata processing with ease. You can use stored procedures to handle complex ETL processes, make API calls, and perform data validation.
Power Query Power Query is a powerful ETL (Extract, Transform, Load) tool within Power BI that helps users clean and transform raw data into usable formats. Key Features Data Cleaning Functions: Remove duplicates, fill missing values, or standardise formats. Automation of Tasks: Save time by automating repetitive query steps.
Experimenting with LLMs to automate fact generation from QA ground truth using LLMs can help. Automate, but verify, with LLMs – Use LLMs to generate initial ground truth answers and facts, with a human review and curation to align with the desired assistant output standards.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
This is a new capability that enables data engineers and scientists to quickly identify and resolve issues in their Spark applications. This feature uses ML and generative AI technologies to provide automated root cause analysis for failed Spark applications, along with actionable recommendations and remediation steps. Choose your job.
In contrast, MongoDB uses a more straightforward query language that works well with JSON data structures. MongoDB’s horizontal scaling capabilities surpass relational databases’ typical vertical scaling limitations, making it suitable for bigdata applications. What Is a MongoDB Atlas?
The answer lay in using generative AI through Amazon Bedrock Flows, enabling them to build an automated, intelligent request handling system that would transform their client service operations. Path to the solution When evaluating solutions for email triage automation, several approaches appeared viable, each with its own pros and cons.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content