This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In a bid to accelerate the adoption of AI in the enterprise sector, Wipro has unveiled its latest offering that leverages the capabilities of IBM’s watsonx AI and dataplatform. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
These tools cover a range of functionalities including predictive analytics for lead prospecting, automated property valuation, intelligent lead nurturing, virtual staging, and market analysis. Offrs Offrs is a predictive analytics platform that helps real estate agents identify homeowners likely to sell in the near future.
And AI, both supervised and unsupervised machine learning, is often the best or sometimes only way to unlock these new bigdata insights at scale. How does an open data lakehouse architecture support AI?
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. And you should have experience working with bigdataplatforms such as Hadoop or Apache Spark.
How BigData and AI Work Together: Synergies & Benefits: The growing landscape of technology has transformed the way we live our lives. of companies say they’re investing in BigData and AI. Although we talk about AI and BigData at the same length, there is an underlying difference between the two.
AI can also work from deep learning algorithms, a subset of ML that uses multi-layered artificial neural networks (ANNs)—hence the “deep” descriptor—to model high-level abstractions within bigdata infrastructures. This process can prove unmanageable, if not impossible, for many organizations.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
At the time, Sevilla FC could efficiently access and use quantitative player data in a matter of seconds, but the process of extracting qualitative information from the database was much slower in comparison. In the case of Sevilla FC, using bigdata to recruit players had the potential to change the core business.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a DataPlatform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Dataplatforms & Data Governance.
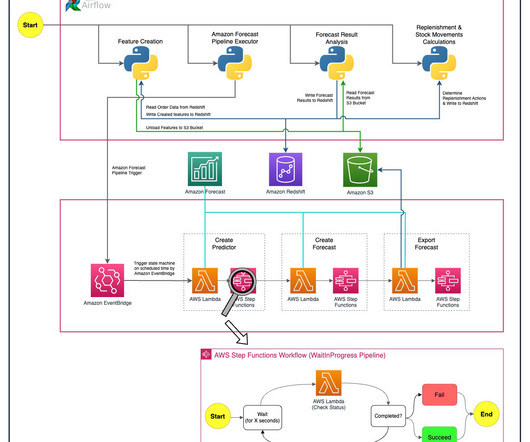
Airflow provides the workflow management capabilities that are integral to modern cloud-native dataplatforms. It automates the execution of jobs, coordinates dependencies between tasks, and gives organizations a central point of control for monitoring and managing workflows.
Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. The serverless batch pipeline architecture we presented offers a scalable solution for automating this process across large enterprise knowledge bases. 201% $12.2B
A framework for vending new accounts is also covered, which uses automation for baselining new accounts when they are provisioned. You can start small with one account for your dataplatform foundations for a proof of concept or a few small workloads.
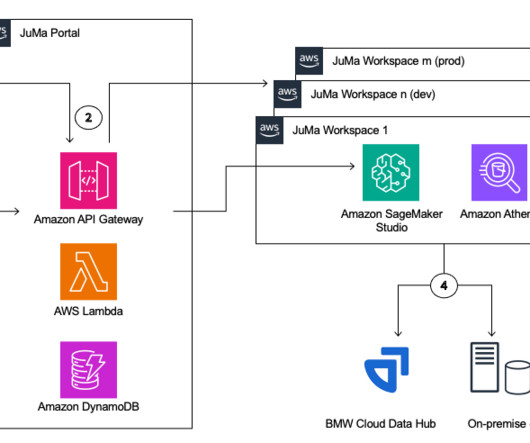
This offering enables BMW ML engineers to perform code-centric data analytics and ML, increases developer productivity by providing self-service capability and infrastructure automation, and tightly integrates with BMW’s centralized IT tooling landscape. A data scientist team orders a new JuMa workspace in BMW’s Catalog.
Additionally, for insights on constructing automated workflows and crafting machine learning pipelines, you can explore AWS Step Functions for comprehensive guidance. He worked at Turkcell, mainly focused on time series forecasting, data visualization, and network automation.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer dataplatform that simplifies the deployment and scaling of MongoDB databases in the cloud.
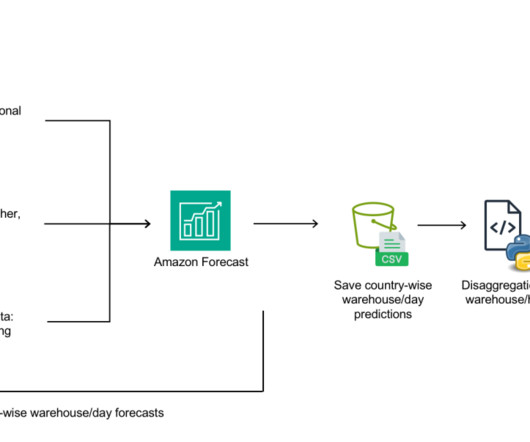
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. Forecast automates much of the time-series forecasting process, enabling you to focus on preparing your datasets and interpreting your predictions.
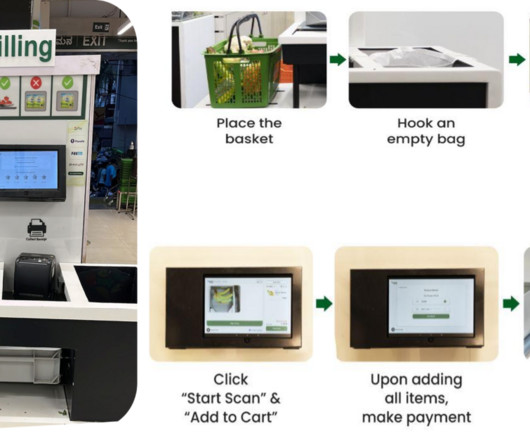
The implementation of an AI-powered automated self-checkout system delivers an improved retail customer experience through innovation, while eliminating human errors in the checkout process. Integrating FSx for Lustre enables fast parallel data access for efficient model retraining with hundreds of new SKUs monthly.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like Machine Learning. These tools automate the process, making it faster and more accurate.
You may use OpenRefine for more than just data cleaning; it can also help you find mistakes and outliers that could compromise your data’s quality. Apache Griffin Apache Griffin is an open-source data quality tool that aims to enhance bigdata processes. It has a quick and clear grasp of data quality issues.
Data gathering, pre-processing, modeling, and deployment are all steps in the iterative process of predictive analytics that results in output. We can automate the procedure to deliver forecasts based on new data continuously fed throughout time. This tool’s user-friendly UI consistently receives acclaim from users.
By automating repetitive tasks and generating boilerplate code, these tools free up time for engineers to focus on more complex, creative aspects of software development. Well, it is offering a way to automate the time-consuming process of writing and running tests. Just keep in mind, that this shouldn’t replace the human element.
As the volume of data keeps increasing at an accelerated rate, these data tasks become arduous in no time leading to an extensive need for automation. This is what data processing pipelines do for you. Let’s understand how the other aspects of a data pipeline help the organization achieve its various objectives.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks. MongoDB, developed by MongoDB Inc.,
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud dataplatform that provides data solutions for data warehousing to data science. Bosco Albuquerque is a Sr.
The entire ETL procedure is automated using an ETL tool. ETL solutions employ several data management strategies to automate the extraction, transformation, and loading (ETL) process, reducing errors and speeding up data integration. Large-scale businesses and BigData firms are its primary target market.
HPCC Systems — The Kit and Kaboodle for BigData and Data Science Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated data lake platform.
A successful load ensures Analysts and decision-makers access to up-to-date, clean data. Common ETL Tools and Technologies Several tools facilitate the ETL process, helping organisations automate and streamline data integration. Apache NiFi : An open-source tool designed for data flow automation and ETL processes.
Use cases range from self-driving cars, content moderation on social media platforms, cancer detection, and automated defect detection. Aamna Najmi is a Data Scientist with AWS Professional Services. She has experience in working on dataplatform and AI/ML projects in the healthcare and life sciences vertical.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production.
For example, McKinsey points out that GenAI can automate the summarization of vast amounts of data from patient logs, which is a time-consuming task, thus freeing up healthcare professionals to focus on more complex patient needs.
Disadvantages of Tableau for Data Science However, apart from the advantages, Tableau for Data Science also has its own disadvantages. These can be explained as follows: Tableau doesn’t have the feature of integration and while Data Scientists make use of automation and integrations.
Experimenting with LLMs to automate fact generation from QA ground truth using LLMs can help. Automate, but verify, with LLMs – Use LLMs to generate initial ground truth answers and facts, with a human review and curation to align with the desired assistant output standards.
For example, McKinsey points out that Gen AI can automate the summarization of vast amounts of data from patient logs, which is a time-consuming task, thus freeing up healthcare professionals to focus on more complex patient needs.
Use dedicated data security software. An integrated data protection system can protect your assets by monitoring them, automating access control, setting up notifications, and auditing your password management. Secure databases in the physical data center, bigdataplatforms and the cloud.
To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and dataplatform. Let’s dive into the analytics landscape and what makes watsonx.data unique.
From data preparation to model deployment, it provides a comprehensive solution. RapidMiner’s versatility for a wide range of data types includes the ability to analyze text, pictures, and audio. Yellowfin’s analytics platform and first-rate customer service allow users to gain insights quickly and effectively.
In-Memory Computing This technology allows for storing and processing data in RAM for faster query response times, enabling real-time analytics. BigData Integration Data warehouses are increasingly incorporating bigdata technologies to handle vast volumes of data from diverse sources.
The risks include non-compliance to regulatory requirements and can lead to excessive hoarding of sensitive data when it’s not necessary. It’s both a data security and privacy issue.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Key Takeaways Business Analytics targets historical insights; Data Science excels in prediction and automation. Business Analytics requires business acumen; Data Science demands technical expertise in coding and ML. Bigdataplatforms such as Apache Hadoop and Spark help handle massive datasets efficiently.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content