This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Bridging the Gap with Natural Language Processing Natural Language Processing (NLP) stands at the forefront of bridging the gap between human language and AI comprehension. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
MLOps are practices that automate and simplify ML workflows and deployments. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). These include version control, experimentation, automation, monitoring, alerting, and governance.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Additionally, it poses a security risk when handling sensitive data, making it a less desirable option in the age of automation and digital security.
They focus on coherence, as opposed to correctness, and develop an automated LLM-based score (BooookScore) for assessing summaries. They first have humans assess each sentence of a sample of generated summaries, then check that the automated metric correlates with the human assessment. Imperial, Google Research.
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. It’s for these reasons that practically everyone involved has a vested interest in SLR automation. dollars apiece. a text file with one word per line).
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
They are now capable of natural language processing ( NLP ), grasping context and exhibiting elements of creativity. Automate tedious, repetitive tasks. Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data. Best practices are evolving rapidly.
Unlike traditional natural language processing (NLP) approaches, such as classification methods, LLMs offer greater flexibility in adapting to dynamically changing categories and improved accuracy by using pre-trained knowledge embedded within the model. This provides an automated deployment experience on your AWS account.
Natural language processing (NLP) focuses on enabling computers to understand and generate human language, making interactions more intuitive and efficient. Recent developments in this field have significantly impacted machine translation, chatbots, and automated text analysis. Check out the Paper and GitHub.
Additionally, the models themselves are created from limited architectures: “Almost all state-of-the-art NLP models are now adapted from one of a few foundation models, such as BERT, RoBERTa, BART, T5, etc. But note, capturing risk well before your model has been developed and is in production is optimal.
Examples of Small Language Models DistilBERT is a quicker, more compact version of BERT that transforms NLP by preserving performance without sacrificing efficiency. Modified iterations of Google’s BERT model, including BERT Mini, Small, Medium, and Tiny, have been designed to accommodate varying resource limitations.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
Bioformer Bioformer is a compact version of BERT that can be used for biomedical text mining. Although BERT has achieved state-of-the-art performance in NLP applications, its parameters could be reduced with a minor impact on performance to improve its computational efficiency.
Initially, organizations struggled with versioning, monitoring, and automating model updates. As MLOps matured, discussions shifted from simple automation to complex orchestration involving continuous integration, deployment (CI/CD), and model drift detection.
Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors. These approaches highlight the importance of causal explanations in NLP systems to ensure safety and establish trust. Impact of the LLM Black Box Problem 1.
Researchers and practitioners explored complex architectures, from transformers to reinforcement learning , leading to a surge in sessions on natural language processing (NLP) and computervision. Starting with BERT and accelerating with the launch of GPT-3 , conference sessions on LLMs and transformers skyrocketed.
Consequently, there’s been a notable uptick in research within the natural language processing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations. Recent approaches automate circuit discovery, enhancing interpretability.
Artificial intelligence (AI) is making significant strides in natural language processing (NLP), focusing on enhancing models that can accurately interpret and generate human language. A major issue facing NLP is sustaining coherence over long texts. In experiments, this model demonstrated marked improvements across various benchmarks.
Authorship Verification (AV) is critical in natural language processing (NLP), determining whether two texts share the same authorship. With deep learning models like BERT and RoBERTa, the field has seen a paradigm shift. BERT and RoBERTa, for example, have shown superior performance over traditional stylometric techniques.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Regex generation Regular expression generation is time-consuming for developers; however, Autoregex.xyz leverages GPT-3 to automate the process.
Sentiment analysis and other natural language programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. W&B Sweeps is a powerful tool to automate hyperparameter optimization. The code can be found on the GitHub repo.
Libraries DRAGON is a new foundation model (improvement of BERT) that is pre-trained jointly from text and knowledge graphs for improved language, knowledge and reasoning capabilities. DRAGON can be used as a drop-in replacement for BERT. AutoKitteh is a developer platform for workflow automation and orchestration.
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and data extraction, among other skills. This course is ideal for learners looking to automate complex workflows and unlock new development capabilities.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
Original natural language processing (NLP) models were limited in their understanding of language. They tended to rely on smaller datasets and more developer handholding, making them less intelligent and more like automation tools. User Experience: LLMs can engage users in more natural, human-like conversations.
AI technologies, such as ML, NLP, and generative models like GPT-3, have reshaped job roles and demanded new skill sets. While some jobs face automation, roles requiring emotional intelligence and creativity remain less susceptible to AI replacement.
CaseHOLD is a new dataset for legal NLP tasks. The CaseHOLD dataset was created to address the lack of large-scale, domain-specific datasets for legal NLP. The dataset is a valuable resource for researchers working on legal NLP as it is the first large-scale, domain-specific dataset for this task. This is where BioBERT comes in.
Deep learning techniques can be used to automate processes that ordinarily require human intellect, such as text-to-sound transcription or the description of photographs. Natural Language Processing (NLP) is a subfield of artificial intelligence. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google.
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. For text tasks such as sentence classification, text classification, and question answering, you can use models such as BERT, RoBERTa, and DistilBERT.
Calculate a ROUGE-N score You can use the following steps to calculate a ROUGE-N score: Tokenize the generated summary and the reference summary into individual words or tokens using basic tokenization methods like splitting by whitespace or natural language processing (NLP) libraries.
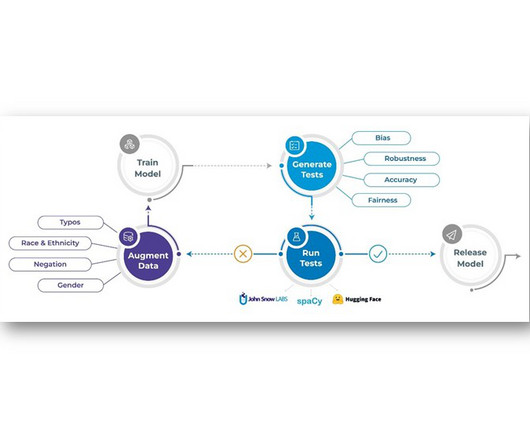
The underlying principles behind the NLP Test library: Enabling data scientists to deliver reliable, safe and effective language models. However, today there is a gap between these principles and current state-of-the-art NLP models. These findings suggest that the current NLP systems are unreliable and flawed.
It automates document analysis, enhances the identification of relevant legal principles, and establishes new benchmarks in the field. Applications of AI in legal research automation AI is reshaping legal research, introducing sophisticated tools that redefine how professionals conduct research, strategize, and engage with clients.
With the increasing need for privacy compliance, including regulations such as GDPR and CCPA, PII Masker provides a powerful means of automating the detection and anonymization of PII. PII Masker utilizes cutting-edge AI models, particularly Natural Language Processing (NLP), to accurately detect and classify sensitive information.
In this post, we explore the utilization of pre-trained models within the Healthcare NLP library by John Snow Labs to map medical terminology to the MedDRA ontology. Let us start with a short Spark NLP introduction and then discuss the details of the response to cancer treatment with some solid results.
Experts Share Perspectives on How Advanced NLP Technologies Will Shape Their Industries and Unleash Better & Faster Results. NLP algorithms can sift through vast medical literature to aid diagnosis, while LLMs facilitate smoother patient-doctor interactions. According to the data collected by Forbes , over a half (53.3%
Unlike traditional NLP models which rely on rules and annotations, LLMs like GPT-3 learn language skills in an unsupervised, self-supervised manner by predicting masked words in sentences. Their foundational nature allows them to be fine-tuned for a wide variety of downstream NLP tasks. This enables pretraining at scale.
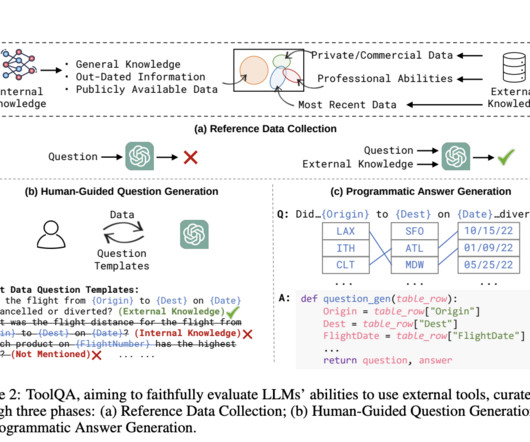
Large Language Models (LLMs) have proven to be really effective in the fields of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., ToolQA involves three automated phases: Reference Data Collection, Human-guided Question Generation, and Programmatic Answer Generation.
The overall business outcome was to improve the organization’s operations by automating an existing manual process and to improve user experience by increasing speed and quality in detecting inappropriate interactions between players, ultimately promoting a cleaner and healthier gaming environment.
By implementing a modern natural language processing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. Before we start training any NLP models, we ensure that the input data is clean and the labels are assigned according to expectation.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., spam vs. not spam), while generative NLP models can create new text based on a given prompt (e.g., a social media post or product description).
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. str.split("|").str[0]
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content