This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
Bridging the Gap with NaturalLanguageProcessingNaturalLanguageProcessing (NLP) stands at the forefront of bridging the gap between human language and AI comprehension. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for naturallanguageprocessing tasks like answering questions, analyzing sentiment, and translation.
Researchers have focused on developing and building models to process and compare human language in naturallanguageprocessing efficiently. This technology is crucial for semantic search, clustering, and naturallanguage inference tasks.
MLOps are practices that automate and simplify ML workflows and deployments. LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs can understand the complexities of human language better than other models.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. Enhancing Processing Pipelines The use of LLMs marks a significant shift in automating both preprocessing and post-processing stages.
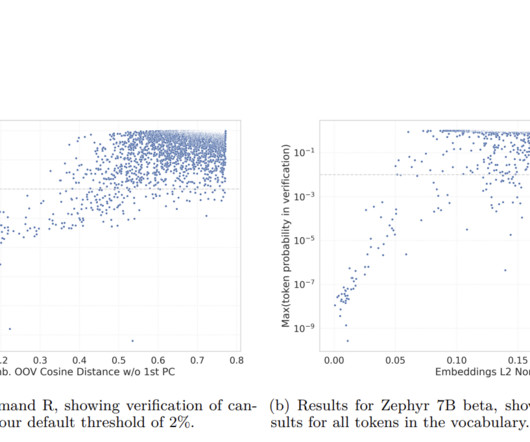
Researchers from Cohere introduce a novel approach that utilizes the model’s embedding weights to automate and scale the detection of under-trained tokens. The study demonstrated the effectiveness of this new method by applying it to several well-known models, including variations of Google’s BERT and OpenAI’s GPT series.
They are now capable of naturallanguageprocessing ( NLP ), grasping context and exhibiting elements of creativity. Automate tedious, repetitive tasks. Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice.
Large Language Models (LLMs), like GPT, PaLM, LLaMA, etc., Their ability to utilize the strength of NaturalLanguageProcessing, Generation, and Understanding by generating content, answering questions, summarizing text, and so on have made LLMs the talk of the town in the last few months.
Naturallanguageprocessing (NLP) focuses on enabling computers to understand and generate human language, making interactions more intuitive and efficient. Recent developments in this field have significantly impacted machine translation, chatbots, and automated text analysis.
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model. .”
Consequently, there’s been a notable uptick in research within the naturallanguageprocessing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations. Recent approaches automate circuit discovery, enhancing interpretability.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
A foundation model is built on a neural network model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
Researchers and practitioners explored complex architectures, from transformers to reinforcement learning , leading to a surge in sessions on naturallanguageprocessing (NLP) and computervision. The real game-changer, however, was the rise of Large Language Models (LLMs). Whats Next for DataScience?
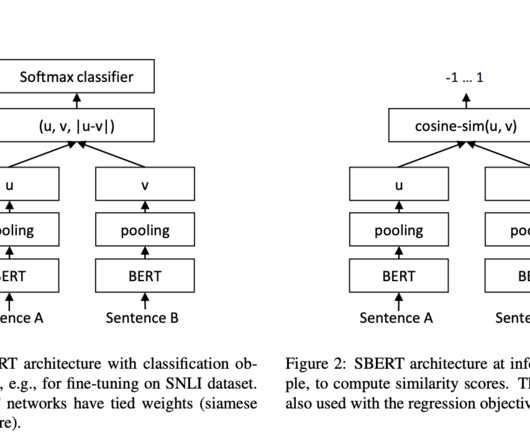
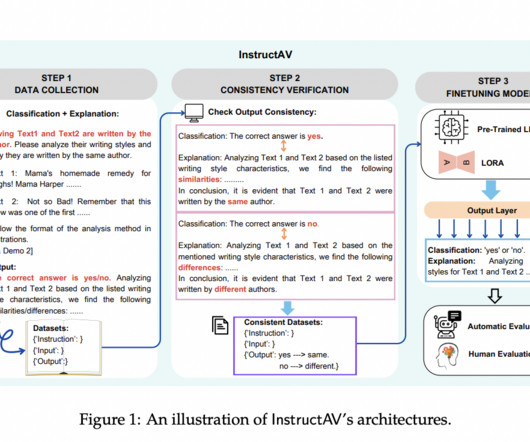
Authorship Verification (AV) is critical in naturallanguageprocessing (NLP), determining whether two texts share the same authorship. With deep learning models like BERT and RoBERTa, the field has seen a paradigm shift. Existing methods for AV have advanced significantly with the use of deep learning models.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
In the rapidly evolving field of artificial intelligence, naturallanguageprocessing has become a focal point for researchers and developers alike. We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. billion word corpus).
Sentiment analysis and other naturallanguage programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. W&B Sweeps is a powerful tool to automate hyperparameter optimization. The code can be found on the GitHub repo.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of Deep Learning. Image by YouTube video “Introduction to large language models” on YouTube Channel “Google Cloud Tech” What are Large Language Models? NaturalLanguageProcessing (NLP) is a subfield of artificial intelligence.
Original naturallanguageprocessing (NLP) models were limited in their understanding of language. They tended to rely on smaller datasets and more developer handholding, making them less intelligent and more like automation tools. User Experience: LLMs can engage users in more natural, human-like conversations.
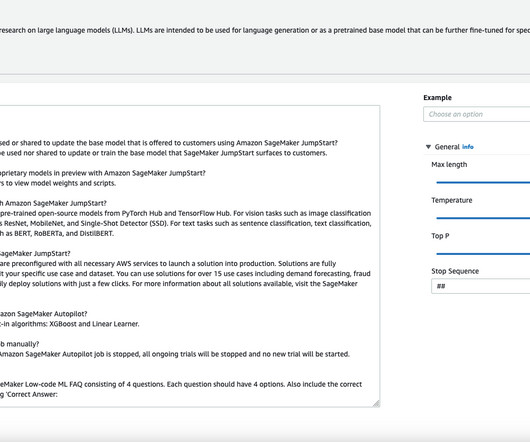
Large language models In recent years, language models have seen a huge surge in size and popularity. In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. Q: What solutions come pre-built with Amazon SageMaker JumpStart?
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. and GPT-4, marked a significant advancement in the field of large language models.
Here, learners delve into the art of crafting prompts for large language models like ChatGPT, learning how to leverage their capabilities for a range of applications. The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter.
Artificial intelligence (AI) is making significant strides in naturallanguageprocessing (NLP), focusing on enhancing models that can accurately interpret and generate human language.
Large Language Models (LLMs) have proven to be really effective in the fields of NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., Being trained on massive amounts of datasets, these LLMs capture a vast amount of knowledge.
These embeddings are useful for various naturallanguageprocessing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. str.split("|").str[0]
With the increasing need for privacy compliance, including regulations such as GDPR and CCPA, PII Masker provides a powerful means of automating the detection and anonymization of PII. PII Masker utilizes cutting-edge AI models, particularly NaturalLanguageProcessing (NLP), to accurately detect and classify sensitive information.
Here are a few examples across various domains: NaturalLanguageProcessing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., For example, large language models (LLMs) are trained by randomly replacing some of the tokens in training data with a special token, such as [MASK].
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing naturallanguageprocessing and AI. Techniques like Word2Vec and BERT create embedding models which can be reused. Google's MUM model uses VATT transformer to produce entity-aware BERT embeddings.
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. In our example, we use the Bidirectional Encoder Representations from Transformers (BERT) model, commonly used for naturallanguageprocessing.
Calculate a ROUGE-N score You can use the following steps to calculate a ROUGE-N score: Tokenize the generated summary and the reference summary into individual words or tokens using basic tokenization methods like splitting by whitespace or naturallanguageprocessing (NLP) libraries.
LLMs are pre-trained on extensive data on the web which shows results after comprehending complexity, pattern, and relation in the language. LLMs apply powerful NaturalLanguageProcessing (NLP), machine translation, and Visual Question Answering (VQA). GPT-4, BERT) based on your specific task requirements.
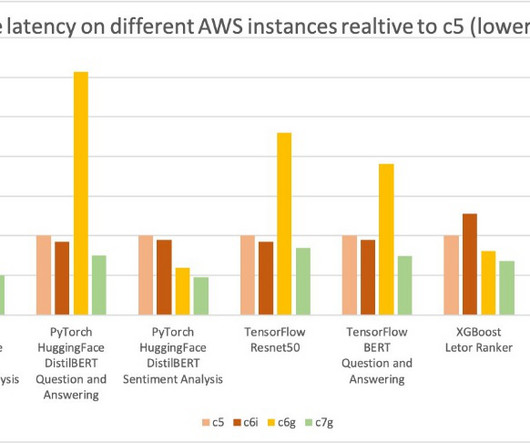
We cover computer vision (CV), naturallanguageprocessing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking.
The previous year saw a significant increase in the amount of work that concentrated on Computer Vision (CV) and NaturalLanguageProcessing (NLP). Because of this, academics worldwide are looking at the potential benefits deep learning and large language models (LLMs) might bring to audio generation.
Moreover, metadata automation has progressed significantly, aided by advanced naturallanguageprocessing (NLP) and computer vision techniques. They utilized techniques such as Conditional Random Fields, BiLSTM with BERT representations, and innovative multimodal and TextMap methods.
source: author Introduction Sentiment analysis is a rapidly growing field within the NaturalLanguageProcessing (NLP) domain, which deals with the automatic analysis and classification of emotions and opinions expressed in text. The robust and flexible programming language R is widely used for data analysis and visualisation.
Speech Recognition Speech recognition involves converting spoken language into text so that computers can hear and interpret it more easily. Numerous applications, such as automated customer service, virtual assistants, and speech-to-text transcription, use speech recognition extensively. Why Did RoBERTa Get Developed?
I have written short summaries of 68 different research papers published in the areas of Machine Learning and NaturalLanguageProcessing. They focus on coherence, as opposed to correctness, and develop an automated LLM-based score (BooookScore) for assessing summaries. Imperial, Google Research.
While a majority of NaturalLanguageProcessing (NLP) models focus on English, the real world requires solutions that work with languages across the globe. Labeling data from scratch for every new language would not scale, even if the final architecture remained the same.
Summary : Sentiment Analysis is a naturallanguageprocessing technique that interprets and classifies emotions expressed in text. Sentiment Analysis is a popular task in naturallanguageprocessing. It uses various NaturalLanguageProcessing algorithms such as Rule-based, Automatic, and Hybrid.
On the other hand, LangTest has emerged as a transformative force in the realm of NaturalLanguageProcessing (NLP) and Large Language Model (LLM) evaluation. The library’s core emphasis is on depth, automation, and adaptability, ensuring that any system integrated into real-world scenarios is beyond reproach.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content