This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Future AGIs proprietary technology includes advanced evaluation systems for text and images, agent optimizers, and auto-annotation tools that cut AI development time by up to 95%. Enterprises can complete evaluations in minutes, enabling AI systems to be optimized for production with minimal manual effort.
The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels. Key features of Katana: Live Inventory Control: Real-time tracking of raw materials and products with auto-booking to allocate stock to orders efficiently.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. SageMaker simplifies the process of managing dependencies, container images, auto scaling, and monitoring. They often work with DevOps engineers to operate those pipelines.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
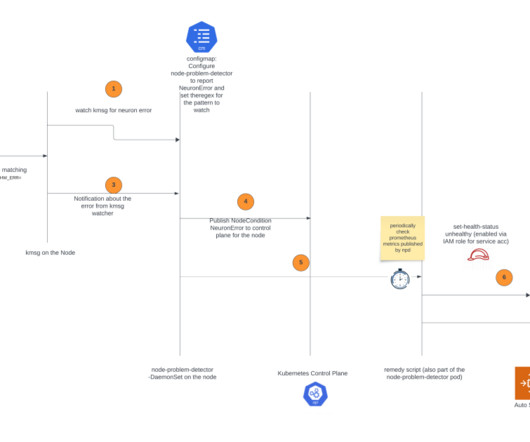
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. This solution is applicable if you’re using managed nodes or self-managed node groups (which use Amazon EC2 Auto Scaling groups ) on Amazon EKS. and public.ecr.aws.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. Following are the steps completed by using APIs to create and share a model package group across accounts.
The AWS portfolio of ML services includes a robust set of services that you can use to accelerate the development, training, and deployment of machine learning applications. The suite of services can be used to support the complete model lifecycle including monitoring and retraining ML models.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Complete the following steps: Choose Prepare and analyze data. Complete the following steps: Choose Run Data quality and insights report. Choose Create. Choose Export.
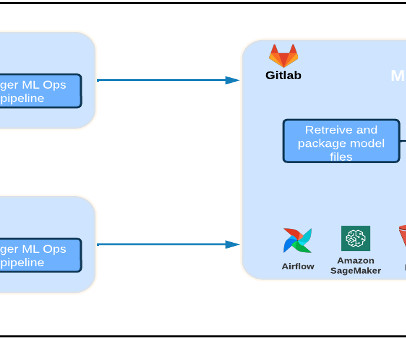
We orchestrate our ML training and deployment pipelines using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which enables us to focus more on programmatically authoring workflows and pipelines without having to worry about auto scaling or infrastructure maintenance.
Nothing in the world motivates a team of MLengineers and scientists to spend the required amount of time in data annotation and labeling. Now if you see, it's a complete workflow optimization challenge centered around the ability to execute data-related operations 10x faster. It's a new need now.
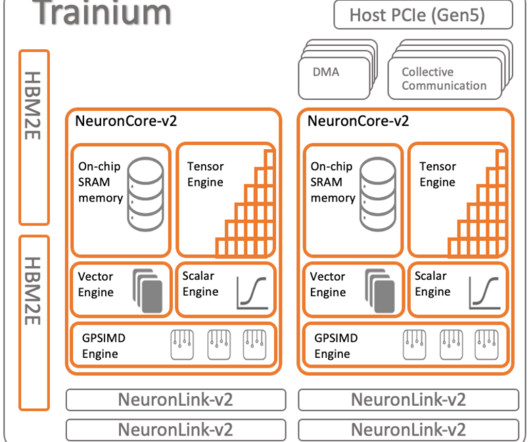
Regular CPU systems are completely memory bound for these calculations, and performance is limited by the time required to move the data into the CPU. In Trainium, the GP-SIMD engines are tightly coupled with the on-chip caches using a high bandwidth streaming interface, which can sustain 2 TB/sec of memory bandwidth.
This allows you to share the intended uses and assessed carbon impact of a model so that data scientists, MLengineers, and other teams can make informed decisions when choosing and running models. If your workloads can tolerate latency, consider deploying your model on Amazon SageMaker Asynchronous Inference with auto-scaling groups.
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. 2xlarge instances.
Create a KMS key in the dev account and give access to the prod account Complete the following steps to create a KMS key in the dev account: On the AWS KMS console, choose Customer managed keys in the navigation pane. Choose Create key. For Key type , select Symmetric. For Script Path , enter Jenkinsfile. Choose Save.
The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. MLengineers no longer need to manage this training metadata separately. We define another pipeline step, step_cond.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. Auto-scale compute. In the DataRobot left sidebar, there is a table of contents auto-generated from the hierarchy of Markdown cells.
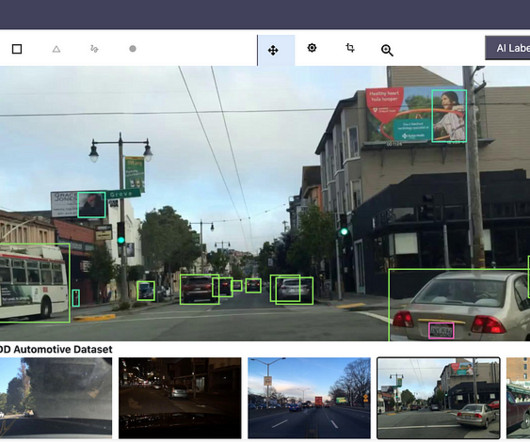
Can you see the complete model lineage with data/models/experiments used downstream? Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. MLOps workflows for computer vision and ML teams Use-case-centric annotations.
data or auto-generated files). cell outputs) for code completion in Jupyter notebooks (see this Jupyter plugin ). Were there any research breakthroughs in StarCoder, or would you say it was more of a crafty MLengineering effort? In addition we labelled a PII dataset for code to train a PII detector.
Comet Comet is a machine learning platform built to help data scientists and MLengineers track, compare, and optimize machine learning experiments. Image by Author If you want to end the experiment, you can use the end method of the Experiment object to mark the experiment as complete. #
MLengineers must handle parallelization, scheduling, faults, and retries manually, requiring complex infrastructure code. In this post, we discuss the benefits of using Ray and Amazon SageMaker for distributed ML, and provide a step-by-step guide on how to use these frameworks to build and deploy a scalable ML workflow.
Provides modularity as a series of completely configurable, independent modules that can be combined with the fewest restrictions possible. It is used by programmers to handle multidimensional arrays and gives users the option to optimize mathematical representations in ML applications. It is very fast and supports GPU.
I believe the team will look something like this: Software delivery reliability: DevOps engineers and SREs ( DevOps vs SRE here ) ML-specific software: software engineers and data scientists Non-ML-specific software: software engineers Product: product people and subject matter experts Wait, where is the MLOps engineer?
But ideally, we strive for complete independence of the models in our system so that we can update them without then having to go update every other model in the pipeline – that’s a danger that you can run into. But it’s absolutely critical for most people in our space that you do some type of auto-scaling.
Technical Debt Mitigation : Amazon SageMaker , being a managed service, allowed us to free our MLengineers from the burden of inference, enabling them to focus more on our core platform features—this relief from technical debt is a significant advantage of using SageMaker, reassuring us of its efficiency.
People will auto-scale up to 10 GPUs to handle the traffic. Does it mean that the production code has to be rewritten by, for example, MLengineers manually to be optimized for GPU with each update? Each of them may be with separate resource constraints, auto-scaling policies, and such. That’ll be easier short term.
is an auto-regressive language model that uses an optimized transformer architecture. 405B-Instruct You can use Llama models for text completion for any piece of text. The Llama 3.1 At its core, Llama 3.1 Model Name Model ID Default instance type Supported instance types Meta-Llama-3.1-8B 24xlarge, ml.p5.48xlarge Meta-Llama-3.1-8B-Instruct
autogpt : Auto-GPT is an “Autonomous AI agent” that given a goal in natural language, will allow Large Language Models (LLMs) to think, plan, and execute actions for us autonomously. The complete code of the APP can be found here. It is built on top of OpenAI’s Generative Pretrained Transformer (GPT-3.5 If you liked the blog post pls.
In your AWS account, prepare a table using Amazon DataZone and Athena completing Step 1 through Step 8 in Amazon DataZone QuickStart with AWS Glue data. 1 MinContainers Minimum containers for auto scaling. 1 MaxContainers Maximum containers for auto scaling. An email address must be included while creating the user.
SageMaker AI makes sure that sensitive data stays completely within each customer’s SageMaker environment and will never be shared with a third party. It also empowers data scientists and MLengineers to do more with their models by collaborating seamlessly with their colleagues in data and analytics teams.
After the model has completed training, you will be routed to the Analyze tab. Note that your numbers might differ from the ones you see in the following figure, because of the stochastic nature of the ML process. You’ll see the following after the batch prediction is complete. Now the model is being created.
Challenges in deploying LLMs for inference As LLMs and their respective hosting containers continue to grow in size and complexity, AI and MLengineers face increasing challenges in deploying and scaling these models efficiently for inference. To run this benchmark, we use sub-minute metrics to detect the need for scaling.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content