This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We are data wranglers at heart, not necessarily softwareengineers by training, and best practices for reproducibility can sometimes get pushed aside in the heat of exploration. As a result, I turned to VS Code, which offers a more robust environment for teamwork and adherence to softwareengineering principles.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. It can take up to 20 minutes for the setup to complete.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. in a code subdirectory. in a code subdirectory.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the complete model lineage with data/models/experiments used downstream?
Just so you know where I am coming from: I have a heavy software development background (15+ years in software). Came to ML from software. Founded two successful software services companies. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”.
Launch the instance using Neuron DLAMI Complete the following steps: On the Amazon EC2 console, choose your desired AWS Region and choose Launch Instance. You can update your Auto Scaling groups to use new AMI IDs without needing to create new launch templates or new versions of launch templates each time an AMI ID changes.
Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform. Set up your environment To set up your environment, complete the following steps: Launch a SageMaker notebook instance with a g5.xlarge xlarge instance.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Varun Shah is a SoftwareEngineer working on Amazon SageMaker Studio at Amazon Web Services.
From a softwareengineering perspective, machine-learning models, if you look at it in terms of the number of parameters and in terms of size, started out from the transformer models. So the application started to go from the pure software-engineering/machine-learning domain to industry and the sciences, essentially.
From a softwareengineering perspective, machine-learning models, if you look at it in terms of the number of parameters and in terms of size, started out from the transformer models. So the application started to go from the pure software-engineering/machine-learning domain to industry and the sciences, essentially.
You would address it in a completely different way, depending on what’s the problem. What I mean is when data scientists are working hand in hand with softwareengineers or MLOps engineers, that would then take over or wrap up the solution. What role have Auto ML models played in computer vision consultant capacity?
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
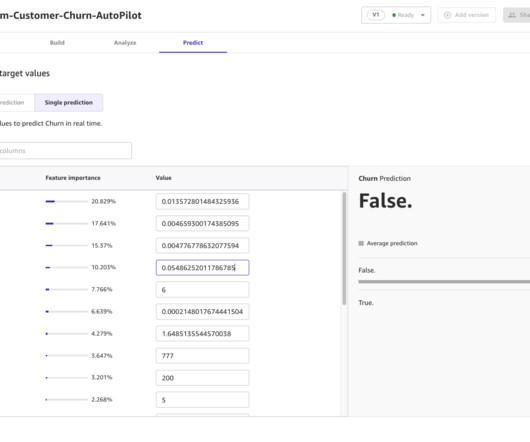
Complete the following steps to use Autopilot AutoML to build, train, deploy, and share an ML model with a business analyst: Download the dataset , upload it to an Amazon S3 ( Amazon Simple Storage Service ) bucket, and make a note of the S3 URI. Complete the steps listed in the README file. Set the target column as churn.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content