This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. The following sample XML illustrates the prompts template structure: EN FR Prerequisites The project code uses the Python version of the AWS Cloud Development Kit (AWS CDK). The request is sent to the prompt generator.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
Photo by maria vechtomova on Linkedln Here’s a glimpse at the list: Python Pylance Jupyter Jupyter Notebook Renderer Gitlens Python Indent DVC Error lens GitHub Co-pilot Data Wrangler ZenML Studio Kedro SandDance 1. Auto-Completion and Refactoring: Enhances coding efficiency and readability.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you render audio/video?
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. The company found that data scientists were having to remove features from algorithms just so they would run to completion.
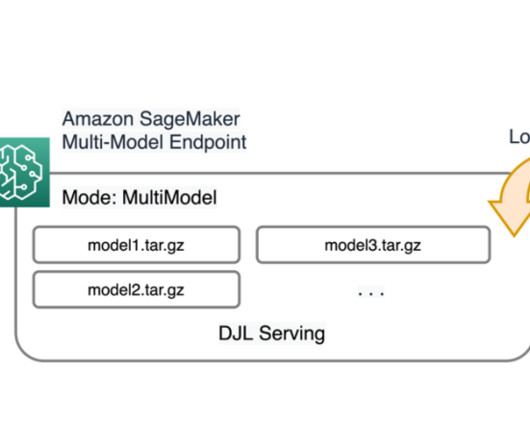
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console. We provide you with two different solutions for this use case.
Tabnine for JupyterLab Typing code is complex without auto-complete options, especially when first starting out. In addition to the spent time inputting method names, the absence of auto-complete promotes shorter naming styles, which is not ideal. For a development environment to be effective, auto-complete is crucial.
SageMaker simplifies the process of managing dependencies, container images, auto scaling, and monitoring. To install the controller in your EKS cluster, complete the following steps: Configure IAM permissions to make sure the controller has access to the appropriate AWS resources. amazonaws.com/sagemaker-xgboost:1.7-1",
One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. TorchScript is a static subset of Python that captures the structure of a PyTorch model. Triton uses TorchScript for improved performance and flexibility. xlarge instance.
First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3. jpg and the completemetadata from styles/38642.json. You need to clone this GitHub repository for replicating the solution demonstrated in this post. lora_alpha=32, # the alpha parameter for Lora scaling.
With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization from a single visual interface. million reviews spanning May 1996 to July 2014. Next, select a training method.
script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. Create a Python job controller script that creates N training manifest files, one for each training run, and submits the jobs to the EKS cluster. script, you likely need to run a Python job to preprocess the data.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code. For Secret type , choose Other type of secret.
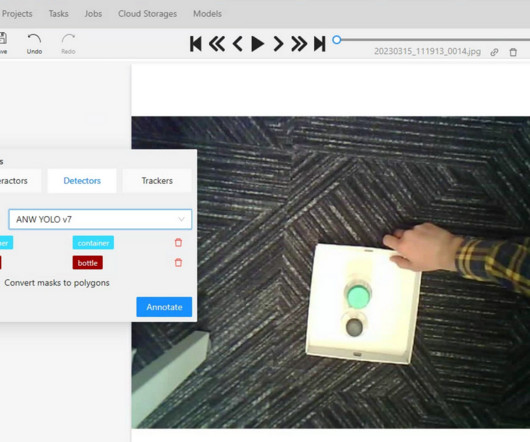
the UI for annotation, image ref: [link] The base containers that run when we put the CVAT stack up (not included auto annotation) (Semi) automated annotation The CVAT (semi) automated annotation allow user to use something call nuclio , which is a tool aimed to assist automated data science through serverless deployment.
To solve this problem, we make the ML solution auto-deployable with a few configuration changes. The training and inference ETL pipeline creates ML features from the game logs and the player’s metadata stored in Athena tables, and stores the resulting feature data in an Amazon Simple Storage Service (Amazon S3) bucket.
FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. The AWS Python SDK Boto3 may also be combined with Torch Dataset classes to create custom data loading code. This results in faster restarts and workload completion.
in their paper Auto-Encoding Variational Bayes. script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. Auto-Encoding Variational Bayes. VAEs were introduced in 2013 by Diederik et al. The config.py The torch.nn
You can find all the code in two Colab notebooks: Fine-tuning Model selection Related post How to Version and Organize ML Experiments That You Run in Google Colab Read more We will use Python 3.10 <pre class =" hljs " style =" display : block; overflow-x: auto; padding: 0.5 in our codes. bitsandbytes==0.41.3 accelerate==0.25.0
The lines are then parsed into pythonic dictionaries. Processing large medical images Handling large TIFF input images cannot be implemented using standard Python tools for image loading ( PIL ) simply because of memory constraints. Using new_from_file only loads image metadata. Patient ID is used as the key.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
The following diagram shows how MusicGen, a single stage auto-regressive Transformer model, can generate high-quality music based on text descriptions or audio prompts. The model package contains a requirements.txt file that lists the necessary Python packages to be installed to serve the MusicGen model. Create a Hugging Face model.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
They proceed to verify the accuracy of the generated answer by selecting the buttons, which auto play the source video starting at that timestamp. The knowledge base sync process handles chunking and embedding of the transcript, and storing embedding vectors and file metadata in an Amazon OpenSearch Serverless vector database.
Amazon Q Business is a conversational assistant powered by generative AI that enhances workforce productivity by answering questions and completing tasks based on information in your enterprise systems, which each user is authorized to access. requirements.txt – The file containing a list of Python modules that are required to be installed.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content