This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
By combining LLMs’ creative generation abilities with retrieval systems’ factual accuracy, RAG offers a solution to one of LLMs’ most persistent challenges: hallucination. Let us get started. Step 1 : Setting Up Our Environment First, we need to install all the required libraries.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. Follow Octus on LinkedIn and X.
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 The pipeline begins when researchers manage tags and metadata on the corresponding model artifact. 3 seconds, with minimal latency.
ThunderMLA builds upon and substantially improves DeepSeek's FlashMLA through the implementation of a completely fused "megakernel" architecture, achieving performance gains of 20-35% across various workloads. Moreover, users can easily extend to other LLM training and inference frameworks.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. With recent advances in large language models (LLMs), Veritone has updated its platform with these powerful new AI capabilities.
Unlike traditional machine learning where outcomes are often binary, LLM outputs dwell in a spectrum of correctness. Therefore, a holistic approach to evaluating LLMs must utilize a variety of approaches, such as using LLMs to evaluate LLMs (i.e., auto-evaluation) and using human-LLM hybrid approaches.
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. Prerequisites Complete the following prerequisite steps: Make sure you have model access in Amazon Bedrock.
How do multimodal LLMs work? A typical multimodal LLM has three primary modules: The input module comprises specialized neural networks for each specific data type that output intermediate embeddings. Basic structure of a multimodal LLM. The fusion module converts the intermediate embeddings into a joint representation.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the complete model lineage with data/models/experiments used downstream?
It also enables operational capabilities including automated testing, conversation analytics, monitoring and observability, and LLM hallucination prevention and detection. “We An optional CloudFormation stack to enable an asynchronous LLM hallucination detection feature. seconds or less. This represents about a full page of text.
Training job resiliency with the job auto resume functionality – In this section, we demonstrate how scientists can submit and manage their distributed training jobs using either the native Kubernetes CLI (kubectl) or optionally the new HyperPod CLI (hyperpod) with automatic job recovery enabled.
BLIP-2 consists of three models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model (LLM). We use a version of BLIP-2, that contains Flan-T5-XL as the LLM. jpg and the completemetadata from styles/38642.json. From here, we can fetch the image for this product from images/38642.jpg
It allows LLMs to reference authoritative knowledge bases or internal repositories before generating responses, producing output tailored to specific domains or contexts while providing relevance, accuracy, and efficiency. Generation is the process of generating the final response from the LLM.
Imagine you’re facing the following challenge: you want to develop a Large Language Model (LLM) that can proficiently respond to inquiries in Portuguese. We will fine-tune different foundation LLM models on a dataset, evaluate them, and select the best model. You have a valuable dataset and can choose from various base models.
LLMs’ generative abilities make them popular for text synthesis, summarization, machine translation, and more. The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges. In the past few years, numerous customers have been using the AWS Cloud for LLM training.
In this blog post, our objective is to illuminate the constantly evolving research around the LLMs space, while also addressing key ethical considerations and trying to provide practical guidance to AI practitioners and clients with examples of our internal use cases, facilitating the responsible development of LLM applications.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. This adaptation is facilitated through the use of LLM prompts. For Secret type , choose Other type of secret.
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. Prompt-response management: Refining LLM-backed applications through continuous prompt-response optimization and quality control.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Others, toward language completion and further downstream tasks. Hope you can all hear me well.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Others, toward language completion and further downstream tasks. Hope you can all hear me well.
The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from data preparation to training and deployment. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. The following diagram illustrates the end-to-end architecture, consisting of the metadata API layer, ingestion pipeline, embedding generation workflow, and frontend UI.
Not only are large language models (LLMs) capable of answering a users question based on the transcript of the file, they are also capable of identifying the timestamp (or timestamps) of the transcript during which the answer was discussed. Each citation can point to a different video, or to different timestamps within the same video.
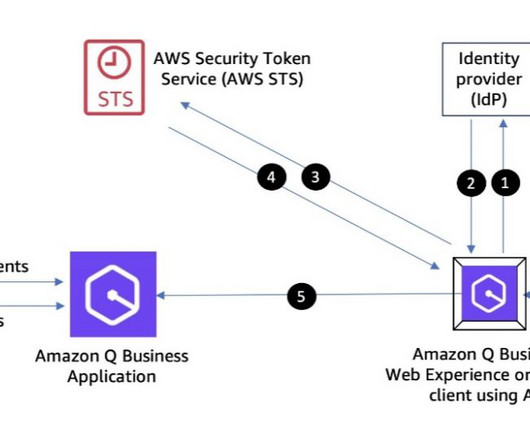
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a large language model (LLM). Complete the following steps to create your application: On the Amazon Q Business console, choose Applications in the navigation pane.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. DIANNA is a groundbreaking malware analysis tool powered by generative AI to tackle real-world issues, using Amazon Bedrock as its large language model (LLM) infrastructure.
Amazon Q Business is a conversational assistant powered by generative AI that enhances workforce productivity by answering questions and completing tasks based on information in your enterprise systems, which each user is authorized to access. On the Settings tab, note the Metadata URI. The sample script simple_aq.py
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content