This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AssemblyAI also offers LeMUR , which lets users leverage advanced LLM capabilities to extract insights automatically from audio and video files. Users can toggle on/off AssemblyAI’s various AI models, including Summarization, Auto Chapters (time-stamped summaries), and LeMUR to tailor the summary format and output as desired.
BlueFlame AI offers an AI-native, purpose-built, and LLM-agnostic solution designed for alternative investment managers. First off, understanding where your data is going and how it's being protected is paramount with LLM providers being hosted solutions. Youve emphasized BlueFlame AIs LLM-agnostic approach. to complete deals.
Future AGIs proprietary technology includes advanced evaluation systems for text and images, agent optimizers, and auto-annotation tools that cut AI development time by up to 95%. Enterprises can complete evaluations in minutes, enabling AI systems to be optimized for production with minimal manual effort.
These triggers are how you give your AI Agents tasks to complete. While the simplest way to give your AI agent a task to complete is by sending it a message, you'll often want to give your agent work from external systems. Otherwise, Relevance AI would just be another LLM! Hit “Abilities” in the left panel menu.
LLM-powered meeting summaries This tutorial shows how to use our dedicated AI summarization model. If you want to see how to generate meeting summaries with LLMs, see our related blog. Virtual meetings have become a cornerstone of modern work, but reviewing lengthy recordings can be time-consuming.
Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe. AI Agents vs. ChatGPT Many advanced AI agents, such as Auto-GPT and BabyAGI, utilize the GPT architecture. Their primary focus is to minimize the need for human intervention in AI task completion.
Researchers want to create a system that eventually learns to bypass humans completely by completing the research cycle without human involvement. Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process.
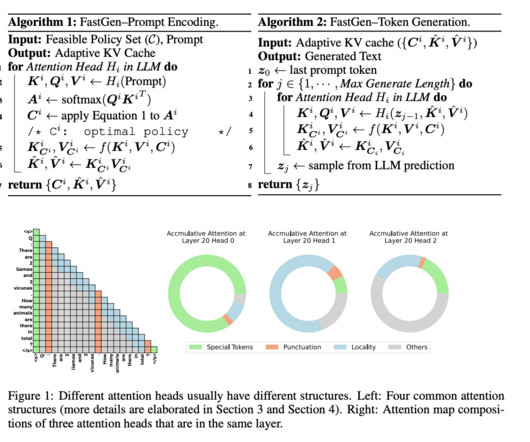
However, these models are only applied to non-autoregressive models and require an extra re-training phrase, making them less suitable for auto-regressive LLMs like ChatGPT and Llama. It is important to consider pruning tokens’ potential within the KV cache of auto-regressive LLMs to fill this gap.
Using Automatic Speech Recognition (also known as speech to text AI , speech AI, or ASR), companies can efficiently transcribe speech to text at scale, completing what used to be a laborious process in a fraction of the time. It would take weeks to filter and categorize all of the information to identify common issues or patterns.
Developing such a model is an exhaustive task, and constructing an application that harnesses the capabilities of an LLM is equally challenging. Given the extensive time and resources required to establish workflows for applications that utilize the power of LLMs, automating these processes holds immense value.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
Instead of formalized code syntax, you provide natural language “prompts” to the models When we pass a prompt to the model, it predicts the next words (tokens) and generates a completion. In this technique, a few logical reasoning steps are added to the prompt as examples for the LLM to understand how to arrive at the desired outcome.
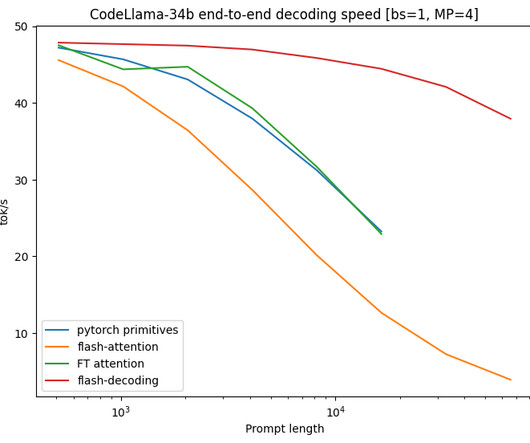
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
Today, generative AI on PC is getting up to 4x faster via TensorRT-LLM for Windows, an open-source library that accelerates inference performance for the latest AI large language models, like Llama 2 and Code Llama. This follows the announcement of TensorRT-LLM for data centers last month.
Auto code completion – It enhances the developer experience by offering real-time suggestions and completions in popular integrated development environments (IDEs), reducing chances of syntax errors and speeding up the coding process. Data preparation In this phase, prepare the training and test data for the LLM.
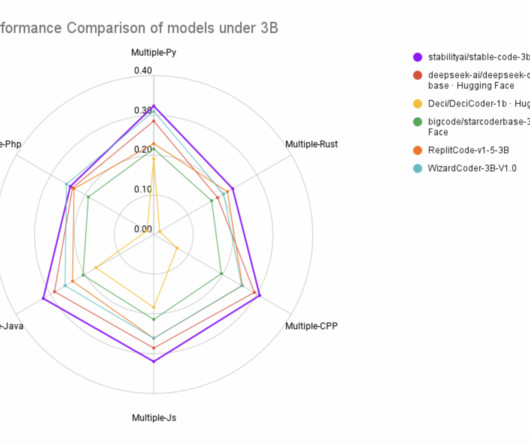
Stable AI has recently released a new state-of-the-art model, Stable-Code-3B , designed for code completion in various programming languages with multiple additional capabilities. Stable-Code-3B is an auto-regressive language model based on the transformer decoder architecture. The model is a follow-up on the Stable Code Alpha 3B.
Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy. It can also modernize legacy code and translate code from one programming language to another.
Generated with Microsoft Designer With the second anniversary of the ChatGPT earthquake right around the corner, the rush to build useful applications based on large language models (LLMs) of its like seems to be in full force. I believe they are highly relevant to other LLM based applications just as much.
By combining LLMs’ creative generation abilities with retrieval systems’ factual accuracy, RAG offers a solution to one of LLMs’ most persistent challenges: hallucination. join([doc.page_content for doc in expanded_retrieved_docs]) # Create prompt for the LLM prompt = f"""<|system|> You are a helpful AI assistant.
Last time we delved into AutoGPT and GPT-Engineering , the early mainstream open-source LLM-based AI agents designed to automate complex tasks. Enter MetaGPT — a Multi-agent system that utilizes Large Language models by Sirui Hong fuses Standardized Operating Procedures (SOPs) with LLM-based multi-agent systems.
The KV cache is not removed from the radix tree when a generation request is completed; it is kept for both the generation results and the prompts. In the second scenario, compiler optimizations like code relocation, instruction selection, and auto-tuning become possible. The researchers used Hugging Face TGI v1.3.0, advice v0.1.8,
In many generative AI applications, a large language model (LLM) like Amazon Nova is used to respond to a user query based on the models own knowledge or context that it is provided. This is the default behavior, so it is consistent with providing no tool choice at all. If the model selects a tool, there will be a tool block and text block.
Another innovative technique is the Tree of Thoughts (ToT) prompting, which allows the LLM to generate multiple lines of reasoning or “thoughts” in parallel, evaluate its own progress towards the solution, and backtrack or explore alternative paths as needed.
MixEval Achieving a balance between thorough user inquiries and effective grading systems is necessary for evaluating LLMs. Conventional standards based on ground truth and LLM-as-judge benchmarks encounter difficulties such as biases in grading and possible contamination over time.
Large language models (LLMs) such as ChatGPT and Llama have garnered substantial attention due to their exceptional natural language processing capabilities, enabling various applications ranging from text generation to code completion. We are also on WhatsApp. Join our AI Channel on Whatsapp.
Since Meta released the latest open-source Large Language Model (LLM), Llama3, various development tools and frameworks have been actively integrating Llama3. Compared to traditional auto-completion tools, Copilot produces more detailed and intelligent code.
Although many LLM acceleration methods aim to decrease the number of non-zero weights, sparsity is the quantity of bits divided by weight. In addition, speculative decoding is a common trend in LLM acceleration. The researchers use an example prompt to examine what occurs in each tier of an LLM to support their approach.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced large language model (LLM) distinguished by its innovative, multi-stage training process. Model Variants The current DeepSeek model collection consists of the following models: DeepSeek-V3 An LLM that uses a Mixture-of-Experts (MoE) architecture.
Prerequisites To complete the solution, you need to have the following prerequisites in place: uv package manager Install Python using uv python install 3.13
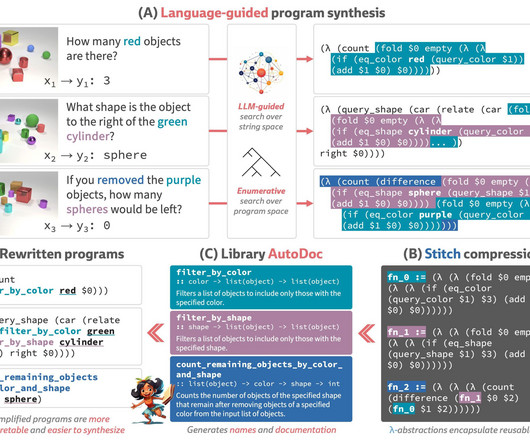
It will be necessary to expand the capabilities of current code completion tools—which are presently utilized by millions of programmers—to address the issue of library learning to solve this multi-objective optimization. Figure 1: The LILO learning loop overview. (Al)
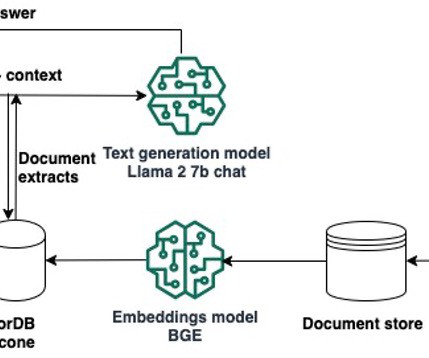
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. There are two models in this implementation: the embeddings model and the LLM that generates the final response.
Evaluating LLM Performance The challenge of evaluating LLMs' performance is met with a strategic approach, incorporating task-specific metrics and innovative evaluation methodologies. Image and Document Processing Multimodal LLMs have completely replaced OCR.
Downstream analytics and LLMs Many features are built on top of speech data and transcripts that allow information to be extracted from recorded speech in a meaningful way. For content with more than one speaker, diarization is needed to assign different AI translated voices to each speaker.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. Follow Octus on LinkedIn and X.
This is probably the easiest way to run an LLM for free on your PC Created using Midjourney. If you would like to be able to test different LLMs locally for free and happen to have a GPU powered PC at home you’re in luck — thanks to the wonderful Open Source community, running different LLMs on Windows is very straightforward.
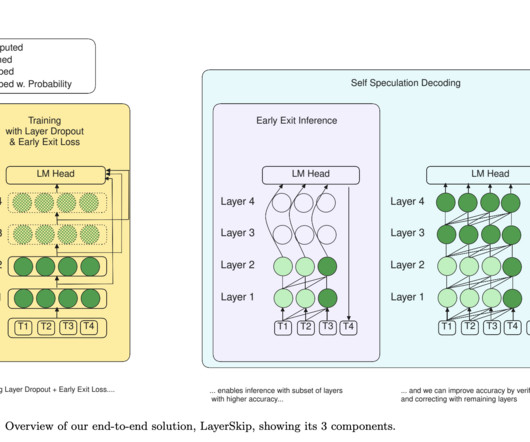
However, the efficiency of LLMs in real-world deployment remains a challenge due to their substantial resource demands, particularly in tasks requiring sequential token generation. One promising solution is Speculative Decoding (SD), a method designed to accelerate LLM inference without compromising generated output quality.
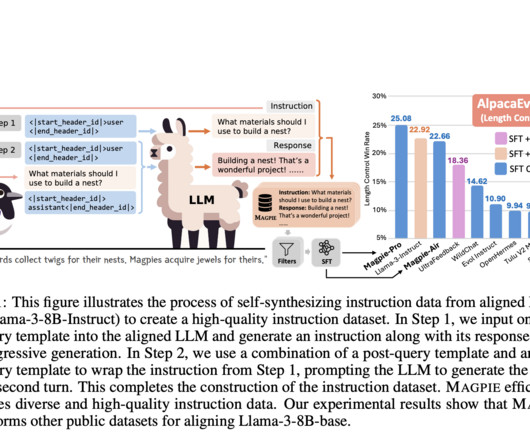
This limitation hinders the advancement of LLM capabilities and their application in diverse, real-world scenarios. Existing methods for generating instruction datasets fall into two categories: human-curated data and synthetic data produced by LLMs. The model then generates diverse user queries based on these templates.
For instance, we’ve used LLM models, including ChatGPT, with a fair amount of success to assist with internal tasks like migrating from one programming language to another, helping developers understand legacy code written by other colleagues, or writing functions for converting data formats. .”
Augmented LLMs are the ones that are added with external tools and skills in order to increase their performance so that they perform beyond their inherent capabilities. Applications like Auto-GPT for autonomous task execution have been made possible by Augmented Language Models (ALMs) only.
Anyspheres Cursor tool, for example, helped advance the genre from simply completing lines or sections of code to building whole software functions based on the plain language input of a human developer. Coding assistants grew considerablyboth in capability and usageduring 2024.
For example, an Avatar configurator can allow designers to build unique, brand-inspired personas for their cars, complete with customized voices and emotional attributes. Li Auto unveiled its multimodal cognitive model, Mind GPT, in June.
ThunderMLA builds upon and substantially improves DeepSeek's FlashMLA through the implementation of a completely fused "megakernel" architecture, achieving performance gains of 20-35% across various workloads. Moreover, users can easily extend to other LLM training and inference frameworks.
Generating configuration management inputs (for CMDB)and changing management inputs based on release notes generated from Agility tool work items completed per release are key Generative AI leverage areas. The ability to generate insights for security validation (from application and platform logs, design points, IAC, etc.)
AI development is always oriented around developing systems that perform tasks that would otherwise require human intelligence, and often significant levels of input, to complete — only at speeds beyond any individual’s or group’s capabilities. Magic Mask has completely changed that workflow. It’s up to 4.5x faster on RTX vs. Mac.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content