
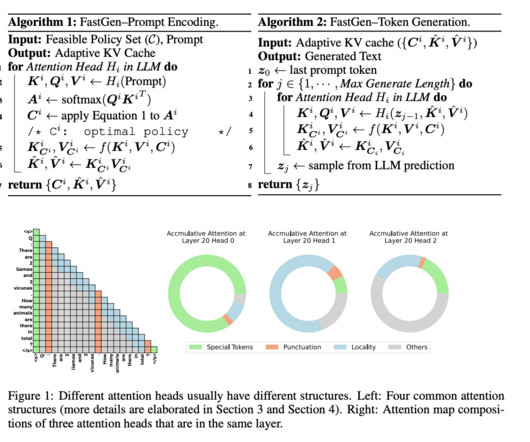
FastGen: Cutting GPU Memory Costs Without Compromising on LLM Quality
Marktechpost
MAY 12, 2024
Recently, a technique that adds a token selection task to the original BERT model learns to select performance-crucial tokens and detect unimportant tokens to prune using a designed learnable threshold. It is important to consider pruning tokens’ potential within the KV cache of auto-regressive LLMs to fill this gap.


















Let's personalize your content