This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata.
TL;DR Multimodal LargeLanguageModels (MLLMs) process data from different modalities like text, audio, image, and video. Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
The performance and quality of the models also improved drastically with the number of parameters. These models span tasks like text-to-text, text-to-image, text-to-embedding, and more. You can use largelanguagemodels (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering.
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
Since 2018, using state-of-the-art proprietary and open source largelanguagemodels (LLMs), our flagship product— Rad AI Impressions — has significantly reduced the time radiologists spend dictating reports, by generating Impression sections. 3 seconds, with minimal latency.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. Follow Octus on LinkedIn and X.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. With recent advances in largelanguagemodels (LLMs), Veritone has updated its platform with these powerful new AI capabilities.
Articles ThunderMLA from Stanford researchers, a new optimization approach for variable-length sequence processing to largelanguagemodel inference that addresses critical performance bottlenecks in attention mechanisms. This is a large gap and main premise of the approach is to cover this performance gap.
Evolving Trends in Prompt Engineering for LargeLanguageModels (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. Auto Eval Common Metric Eval Human Eval Custom Model Eval 3. are harnessed to channel LLMs output.
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. Prerequisites Complete the following prerequisite steps: Make sure you have model access in Amazon Bedrock.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Is it accessible from your language/framework/infrastructure, framework, or infrastructure?
SupportGPT leverages state-of-the-art Information Retrieval (IR) systems and largelanguagemodels (LLMs) to power over 30 million customer interactions annually. Forethought uses per-customer fine-tuned models to detect customer intents in order to solve customer interactions. 2xlarge instances.
In this post, we use BLIP-2, which was introduced in BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and LargeLanguageModels , as our VLM. BLIP-2 consists of three models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a largelanguagemodel (LLM).
However, they’re unable to gain insights such as using the information locked in the documents for largelanguagemodels (LLMs) or search until they extract the text, forms, tables, and other structured data. When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console.
The diagram shows the workflow for building and deploying models using the AutoMLV2 API. In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion. Data preparation The foundation of any machine learning project is data preparation.
Retrieval Augmented Generation (RAG) is a technique that enhances largelanguagemodels (LLMs) by incorporating external knowledge sources. A score of 1 means that the generated answer conveys the same meaning as the ground truth answer, whereas a score of 0 suggests that the two answers have completely different meanings.
LargeLanguageModels (LLMs) present a unique challenge when it comes to performance evaluation. Also, while your base model may excel in broad metrics, general performance doesn’t guarantee optimal performance for your specific use cases. auto-evaluation) and using human-LLM hybrid approaches.
Retrieval-augmented generation ( RAG ) has emerged as a powerful paradigm for enhancing the capabilities of largelanguagemodels (LLMs). Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma.
Then we show how you can enhance the in-notebook SQL experience using Text-to-SQL capabilities provided by advanced largelanguagemodels (LLMs) to write complex SQL queries using natural language text as input. Complete the following steps: On the Secrets Manager console, choose Store a new secret.
Today we’re going to be talking essentially about how responsible generative-AI-model adoption can happen at the enterprise level, and what are some of the promises and compromises we face. The foundation of largelanguagemodels started quite some time ago. What are the promises? Billions of parameters.
Today we’re going to be talking essentially about how responsible generative-AI-model adoption can happen at the enterprise level, and what are some of the promises and compromises we face. The foundation of largelanguagemodels started quite some time ago. What are the promises? Billions of parameters.
TL;DR LLMOps involves managing the entire lifecycle of LargeLanguageModels (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. What is LargeLanguageModel Operations (LLMOps)? What the future of LLMOps looks like.
Imagine you’re facing the following challenge: you want to develop a LargeLanguageModel (LLM) that can proficiently respond to inquiries in Portuguese. You have a valuable dataset and can choose from various base models. These models are usually based on an architecture called transformers.
Complete the following steps to set up your knowledge base: Sign in to your AWS account, then choose Launch Stack to deploy the CloudFormation template: Provide a stack name, for example contact-center-kb. When the stack is complete, you can review the resources it creates on the Resources tab for the CloudFormation stack. Choose Next.
In today’s rapidly evolving landscape of artificial intelligence (AI), training largelanguagemodels (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved.
Training job resiliency with the job auto resume functionality – In this section, we demonstrate how scientists can submit and manage their distributed training jobs using either the native Kubernetes CLI (kubectl) or optionally the new HyperPod CLI (hyperpod) with automatic job recovery enabled.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. This allows FMs to retain their inductive abilities while grounding their language understanding and generation in well-structured domain knowledge and logical reasoning.
Not only are largelanguagemodels (LLMs) capable of answering a users question based on the transcript of the file, they are also capable of identifying the timestamp (or timestamps) of the transcript during which the answer was discussed. Below are retrieved chunks of transcript with metadata including the file name.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a largelanguagemodel (LLM). You also need to hire and staff a large team to build, maintain, and manage such a system. Choose Create application.
Amazon Q Business is a conversational assistant powered by generative AI that enhances workforce productivity by answering questions and completing tasks based on information in your enterprise systems, which each user is authorized to access. On the Settings tab, note the Metadata URI. The sample script simple_aq.py
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. DIANNA is a groundbreaking malware analysis tool powered by generative AI to tackle real-world issues, using Amazon Bedrock as its largelanguagemodel (LLM) infrastructure.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




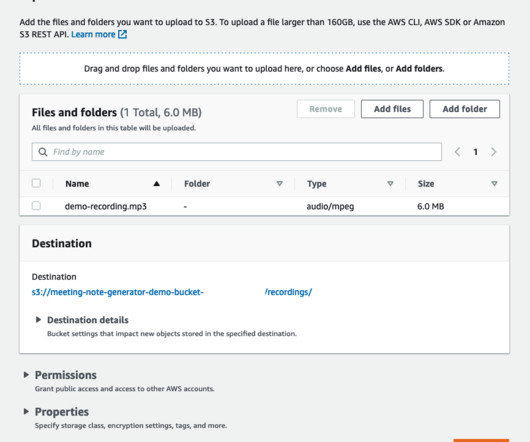

























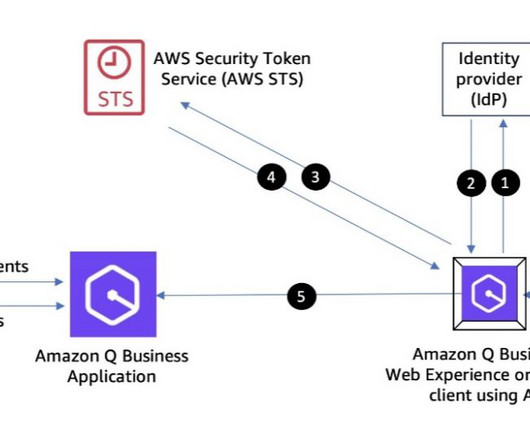







Let's personalize your content