
SGLang: Efficient Execution of Structured Language Model Programs
Unite.AI
AUGUST 6, 2024
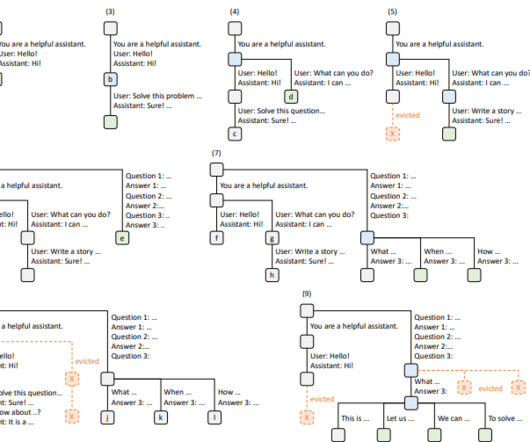
These new use cases necessitate multiple, often dependent, LLM generation calls, indicating a trend of using multi-call structures to complete complex tasks. State-of-the-art inference engines, optimized to reduce latency and improve throughput, lack direct knowledge of the workload, resulting in significant inefficiencies.







Let's personalize your content