
This AI Paper from Meta AI Unveils Dualformer: Controllable Fast and Slow Thinking with Randomized Reasoning Traces, Revolutionizing AI Decision-Making
Marktechpost
OCTOBER 25, 2024
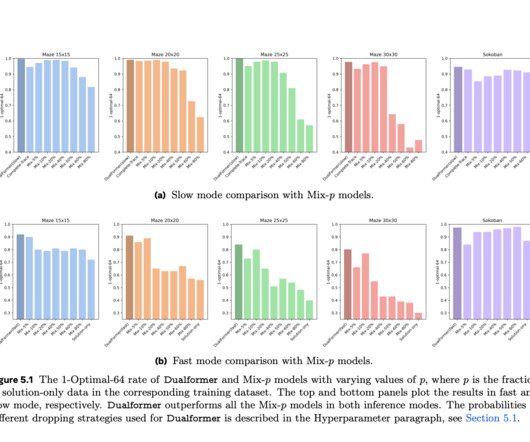
On the other hand, models relying on slow and complete reasoning traces, such as Searchformer, provide better accuracy but underperform due to longer steps of reasoning and its high computational cost. Besides that, when in auto mode, the model selects its strategy, it still stays high, with a high optimal rate of 96.6%








Let's personalize your content