This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, Amazon Web Services (AWS) announced the general availability of Amazon Bedrock Knowledge Bases GraphRAG (GraphRAG), a capability in Amazon Bedrock Knowledge Bases that enhances Retrieval-Augmented Generation (RAG) with graph data in Amazon Neptune Analytics.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. The request is sent to the prompt generator. Also note the completion metrics on the left pane, displaying latency, input/output tokens, and quality scores. Cohere Embed supports 108 languages. Rerun the translation.
By surrounding unparalleled human expertise with proven technology, data and AI tools, Octus unlocks powerful truths that fuel decisive action across financial markets. Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle.
At the same time, our generativeAI models automatically design molecules targeting improvement across numerous properties, searching millions of candidates, and requiring enormous throughput and medium latency. We wanted to build a scalable system to support AI training and inference.
This data is used to enrich the generativeAI prompt to deliver more context-specific and accurate responses without continuously retraining the FM, while also improving transparency and minimizing hallucinations. Prerequisites Complete the following prerequisite steps: Make sure you have model access in Amazon Bedrock.
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generatingcomplete results seamlessly in 0.5–3 In this post, we share how Rad AI reduced real-time inference latency by 50% using Amazon SageMaker. 3 seconds, with minimal latency.
Using generativeAI and new multimodal foundation models (FMs) could be very strategic for Veritone and the businesses they serve, because it would significantly improve media indexing and retrieval based on contextual meaning—a critical first step to eventually generating new content.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. It can take up to 20 minutes for the setup to complete.
To address this challenge, the contact center team at DoorDash wanted to harness the power of generativeAI to deploy a solution quickly, and at scale, while maintaining their high standards for issue resolution and customer satisfaction. This represents about a full page of text. For the percentage overlap, use 10%. Choose Next.
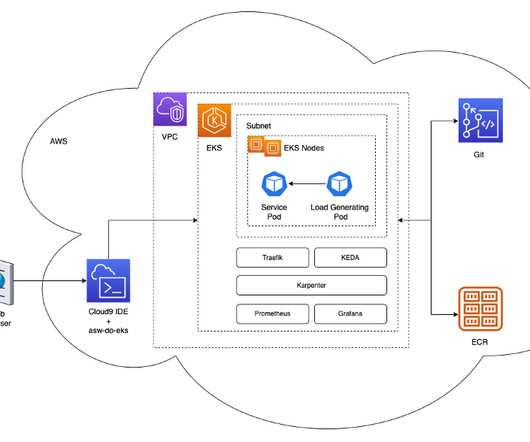
Forethought is a leading generativeAI suite for customer service. Once these gaps are identified, SupportGPT can automatically generate articles and other content to fill these knowledge voids, ensuring the support knowledge base remains customer-centric and up to date. The following diagram illustrates our legacy architecture.
Similarly, a study by Meta AI and Carnegie Melon university found that, in the worst cases, 43 percent of compute time was wasted because of overheads due to hardware failures. This can adversely impact a customer’s ability to keep up with the pace of innovation in generativeAI and can also increase the time-to-market for their models.
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. The company found that data scientists were having to remove features from algorithms just so they would run to completion.
With the advancement of GenerativeAI , we can use vision-language models (VLMs) to predict product attributes directly from images. You can use a managed service, such as Amazon Rekognition , to predict product attributes as explained in Automating product description generation with Amazon Bedrock.
Launch the instance using Neuron DLAMI Complete the following steps: On the Amazon EC2 console, choose your desired AWS Region and choose Launch Instance. You can update your Auto Scaling groups to use new AMI IDs without needing to create new launch templates or new versions of launch templates each time an AMI ID changes.
AWS delivers services that meet customers’ artificial intelligence (AI) and machine learning (ML) needs with services ranging from custom hardware like AWS Trainium and AWS Inferentia to generativeAI foundation models (FMs) on Amazon Bedrock. Download the generated text file to view the transcription. format(' '.join(chunk_summaries),
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generativeAI applications with security, privacy, and responsible AI.
When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console. These JSON files will contain all the Amazon Textract metadata, including the text that was extracted from within the documents. This is a key prerequisite to using your documents for generativeAI and search.
To learn more about SageMaker Studio JupyterLab Spaces, refer to Boost productivity on Amazon SageMaker Studio: Introducing JupyterLab Spaces and generativeAI tools. To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret.
LLMs such as GPT-4 , PaLM-2 , Llama-2 , and others are propelling the surge of GenerativeAI, ushering in novel applications that are reshaping both technological and business landscapes. Evaluating Prompt Completion: The goal is to establish effective evaluation criteria to gauge LLMs’ performance across tasks and domains.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Others, toward language completion and further downstream tasks. In retail: generating product descriptions and recommendations and customer churn and these types of things.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Others, toward language completion and further downstream tasks. In retail: generating product descriptions and recommendations and customer churn and these types of things.
But nowadays, it is used for various tasks, ranging from language modeling to computer vision and generativeAI. The encoder receives the inputs and generates a contextualized interpretation of the inputs, called embeddings. This helps in training large AI models, even on computers with little memory. <pre
NVIDIA NeMo Framework NVIDIA NeMo is an end-to-end cloud-centered framework for training and deploying generativeAI models with billions and trillions of parameters at scale. NVIDIA NeMo simplifies generativeAI model development, making it more cost-effective and efficient for enterprises. 24xlarge instances.
We normalize these images into a set of uniform thumbnails, which constitute the functional input for the active learning pipeline (auto-labeling and inference). The auto-labeling pipeline focuses on automating SageMaker Ground Truth jobs and sampling images for labeling through those jobs.
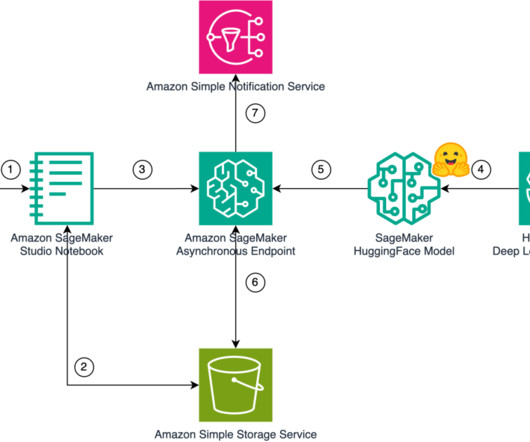
Originating from advancements in artificial intelligence (AI) and deep learning, these models are designed to understand and translate descriptive text into coherent, aesthetically pleasing music. GenerativeAI models are revolutionizing music creation and consumption. Create a Hugging Face model. Deploy the model on SageMaker.
Training job resiliency with the job auto resume functionality – In this section, we demonstrate how scientists can submit and manage their distributed training jobs using either the native Kubernetes CLI (kubectl) or optionally the new HyperPod CLI (hyperpod) with automatic job recovery enabled.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. This allows FMs to retain their inductive abilities while grounding their language understanding and generation in well-structured domain knowledge and logical reasoning.
GenerativeAI provides the ability to take relevant information from a data source and deliver well-constructed answers back to the user. Building a generativeAI -based conversational application that is integrated with the data sources that contain relevant content requires time, money, and people.
They proceed to verify the accuracy of the generated answer by selecting the buttons, which auto play the source video starting at that timestamp. The knowledge base sync process handles chunking and embedding of the transcript, and storing embedding vectors and file metadata in an Amazon OpenSearch Serverless vector database.
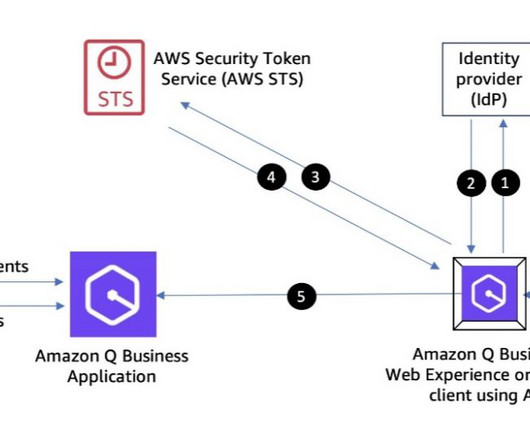
Amazon Q Business is a conversational assistant powered by generativeAI that enhances workforce productivity by answering questions and completing tasks based on information in your enterprise systems, which each user is authorized to access. On the Settings tab, note the Metadata URI. For Name , enter [link].
DSX provides unmatched prevention and explainability by using a powerful combination of deep learning-based DSX Brain and generativeAI DSX Companion to protect systems from known and unknown malware and ransomware in real-time.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content