This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
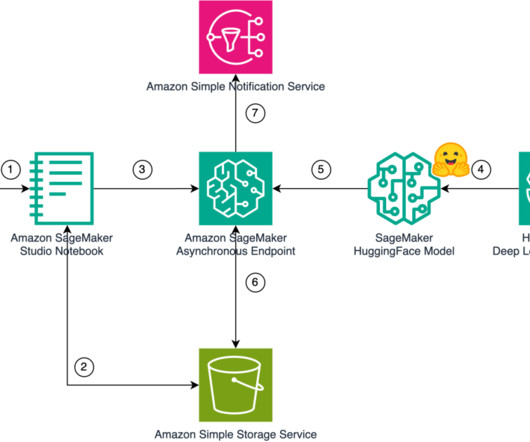
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times.
With AssemblyAI, you can asynchronously transcribe a video and download the transcription as subtitles in either SRT or VTT format. Before you start To complete this tutorial, you'll need: An upgraded AssemblyAI account A DeepL API account. To run the server, first download the dependencies: go get.
x, there is no need to download it separately. You do not need to download the JupyterLab celltags extension separately because it is officially included with JupyterLab 3.x. Tabnine for JupyterLab Typing code is complex without auto-complete options, especially when first starting out.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. Prerequisites Complete the following prerequisite steps: Make sure you have model access in Amazon Bedrock.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the complete model lineage with data/models/experiments used downstream?
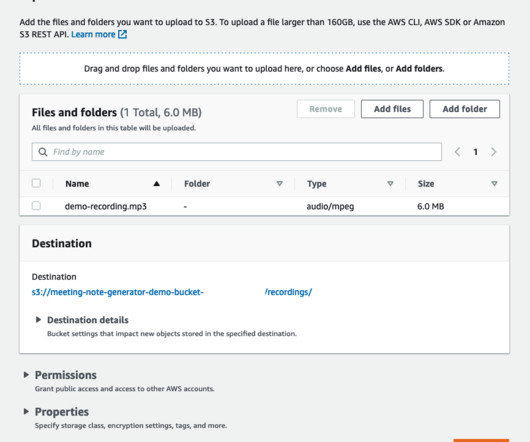
You can use large language models (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering. SageMaker endpoints are fully managed and support multiple hosting options and auto scaling. Complete the following steps: On the Amazon S3 console, choose Buckets in the navigation pane.
jpg and the completemetadata from styles/38642.json. SageMaker starts and manages all of the necessary Amazon Elastic Compute Cloud (Amazon EC2) instances for us, supplies the appropriate Hugging Face container, uploads the specified scripts, and downloads data from our S3 bucket to the container to /opt/ml/input/data.
Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform. Set up your environment To set up your environment, complete the following steps: Launch a SageMaker notebook instance with a g5.xlarge xlarge instance.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Always make sure that sensitive data is handled securely to avoid potential security risks.
In this release, we’ve focused on simplifying model sharing, making advanced features more accessible with FREE access to Zero-shot NER prompting, streamlining the annotation process with completions and predictions merging, and introducing Azure Blob backup integration. With the 5.4 substantially upgrades our annotation capabilities.
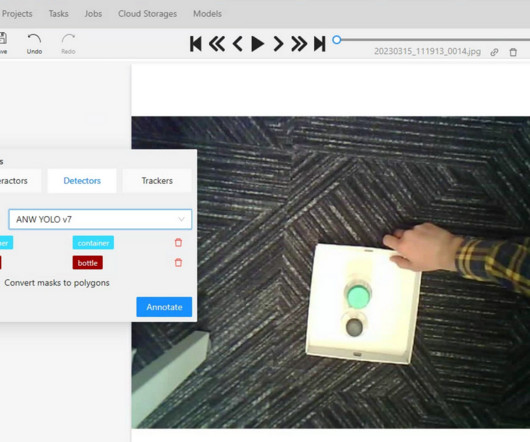
the UI for annotation, image ref: [link] The base containers that run when we put the CVAT stack up (not included auto annotation) (Semi) automated annotation The CVAT (semi) automated annotation allow user to use something call nuclio , which is a tool aimed to assist automated data science through serverless deployment.
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deep learning has achieved remarkable success in supervised tasks, especially in image recognition. in their paper Auto-Encoding Variational Bayes. Auto-Encoding Variational Bayes. Looking for the source code to this post?
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Input and output – These fields are required because NVIDIA Triton needs metadata about the model. Note that the cell takes around 30 minutes to complete. !docker This is run as part of the generate_model.sh
FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. This results in faster restarts and workload completion. Amazon FSx is an open-source parallel file system, popular in high-performance computing (HPC).
You would address it in a completely different way, depending on what’s the problem. This is more about picking, for some active learning or for knowing where the data comes from and knowing the metadata to focus on the data that are the most relevant to start with. This is a much smaller scale than Auto ML.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
The following diagram shows how MusicGen, a single stage auto-regressive Transformer model, can generate high-quality music based on text descriptions or audio prompts. The generated music will be downloaded from the S3 bucket. MusicGen code is released under MIT, model weights are released under CC-BY-NC 4.0.
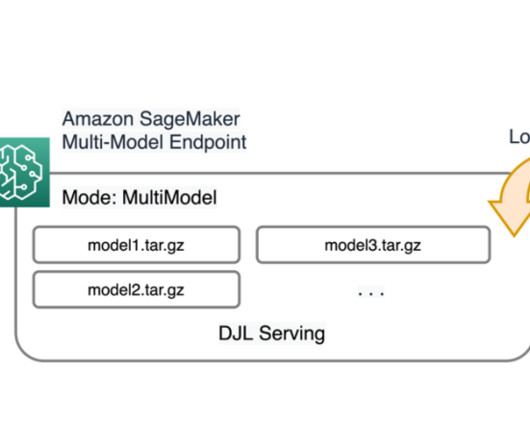
A SageMaker MME dynamically loads models from Amazon Simple Storage Service (Amazon S3) when invoked, instead of downloading all the models when the endpoint is first created. As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency.
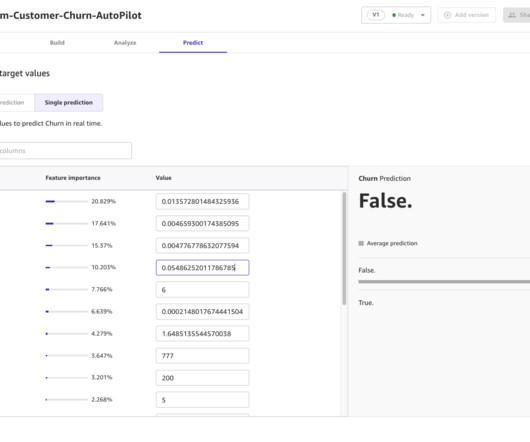
Complete the following steps to use Autopilot AutoML to build, train, deploy, and share an ML model with a business analyst: Download the dataset , upload it to an Amazon S3 ( Amazon Simple Storage Service ) bucket, and make a note of the S3 URI. Download the abalone dataset from Kaggle. Set the target column as churn.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. The following diagram illustrates the end-to-end architecture, consisting of the metadata API layer, ingestion pipeline, embedding generation workflow, and frontend UI.
They proceed to verify the accuracy of the generated answer by selecting the buttons, which auto play the source video starting at that timestamp. The knowledge base sync process handles chunking and embedding of the transcript, and storing embedding vectors and file metadata in an Amazon OpenSearch Serverless vector database.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content