This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Before you start To complete this tutorial, you'll need: An upgraded AssemblyAI account A DeepL API account. It returns metadata about the submitted transcription, from which the ID is used to set the ID of the Job. You'll then use DeepL to translate the subtitles into different languages.
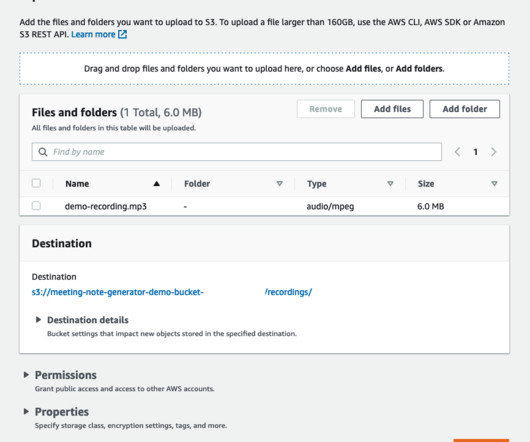
You can use large language models (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering. SageMaker endpoints are fully managed and support multiple hosting options and auto scaling. Complete the following steps: On the Amazon S3 console, choose Buckets in the navigation pane.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the complete model lineage with data/models/experiments used downstream?
Complete the following steps to set up your knowledge base: Sign in to your AWS account, then choose Launch Stack to deploy the CloudFormation template: Provide a stack name, for example contact-center-kb. This is where the content for the demo solution will be stored. For the demo solution, choose the default ( Claude V3 Sonnet ).
In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion. All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
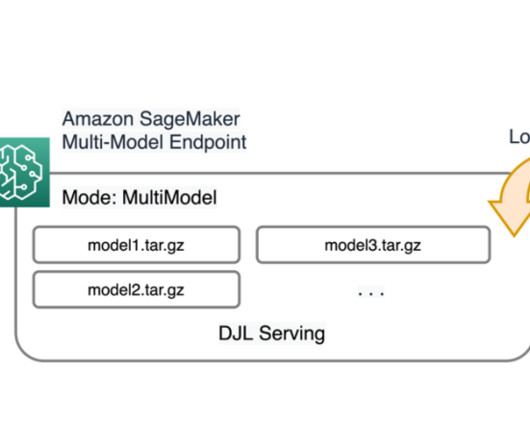
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content