This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
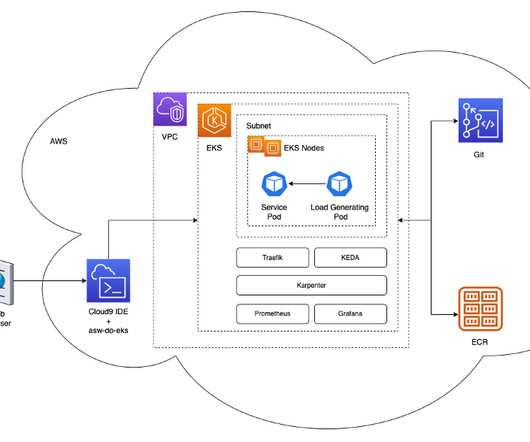
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. We use Amazon EKS and were looking for the best solution to auto scale our worker nodes. This enables all steps to be completed from a web browser.
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 The pipeline begins when researchers manage tags and metadata on the corresponding model artifact. 3 seconds, with minimal latency.
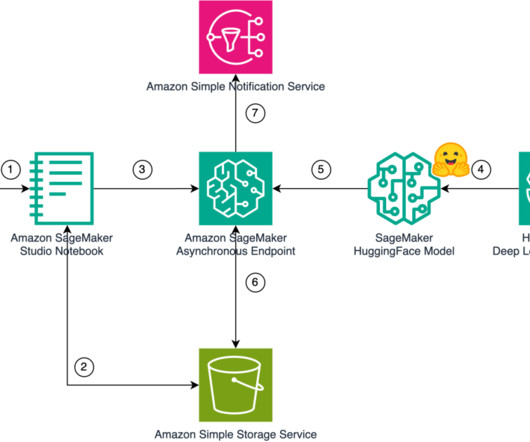
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the complete model lineage with data/models/experiments used downstream?
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
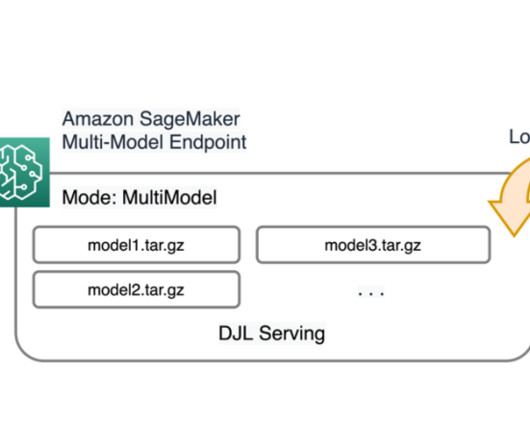
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform. For a list of NVIDIA Triton DeepLearning Containers (DLCs) supported by SageMaker inference, refer to Available DeepLearning Containers Images.
Hyperparameter optimization is highly computationally demanding for deeplearning models. script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. When this step is complete, delete the cluster by using the following script in the eks folder: /eks-delete.sh
To solve this problem, we make the ML solution auto-deployable with a few configuration changes. The training and inference ETL pipeline creates ML features from the game logs and the player’s metadata stored in Athena tables, and stores the resulting feature data in an Amazon Simple Storage Service (Amazon S3) bucket.
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. in their paper Auto-Encoding Variational Bayes. Auto-Encoding Variational Bayes. The config.py The torch.nn
FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. This results in faster restarts and workload completion. Amazon FSx is an open-source parallel file system, popular in high-performance computing (HPC).
auto-evaluation) and using human-LLM hybrid approaches. It will take as input the text generated by an LLM and some metadata, and then output a score that indicates the quality of the text. Auto-evaluation and Hybrid approaches are often used in enterprise settings to scale LLM performance evaluation.
You would address it in a completely different way, depending on what’s the problem. Obviously, different technologies are using what, for most of the time, deeplearning, so different skills. What role have Auto ML models played in computer vision consultant capacity? I would say they’re even easier.
That’s why the clinic wants to harness the power of deeplearning in a bid to help healthcare professionals in an automated way. Using new_from_file only loads image metadata. But it’s not easy to spot the tell-tale signs in scans. Unfortunately, the competition rules prevent us from publishing competition data publicly.
Model management Teams typically manage their models, including versioning and metadata. Observability tools: Use platforms that offer comprehensive observability into LLM performance, including functional logs (prompt-completion pairs) and operational metrics (system health, usage statistics). using techniques like RLHF.)
We normalize these images into a set of uniform thumbnails, which constitute the functional input for the active learning pipeline (auto-labeling and inference). The auto-labeling pipeline focuses on automating SageMaker Ground Truth jobs and sampling images for labeling through those jobs.
Complete the following steps to set up your knowledge base: Sign in to your AWS account, then choose Launch Stack to deploy the CloudFormation template: Provide a stack name, for example contact-center-kb. When the stack is complete, you can review the resources it creates on the Resources tab for the CloudFormation stack. Choose Next.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearning inference library. It’s optimized for NVIDIA GPUs and provides a way to accelerate deeplearning inference in production environments. Input and output – These fields are required because NVIDIA Triton needs metadata about the model.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
Originating from advancements in artificial intelligence (AI) and deeplearning, these models are designed to understand and translate descriptive text into coherent, aesthetically pleasing music. Obtain the AWS DeepLearning Containers for Large Model Inference from pre-built HuggingFace Inference Containers.
Deep Instinct is a cybersecurity company that offers a state-of-the-art, comprehensive zero-day data security solutionData Security X (DSX), for safeguarding your data repositories across the cloud, applications, network attached storage (NAS), and endpoints.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content