This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels. Because Katana integrates purchasing, sales, and manufacturing in one place, it helps businesses avoid manual data transfer and reduces the risk of errors in production planning.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for datascientists and machine learning (ML) engineers.
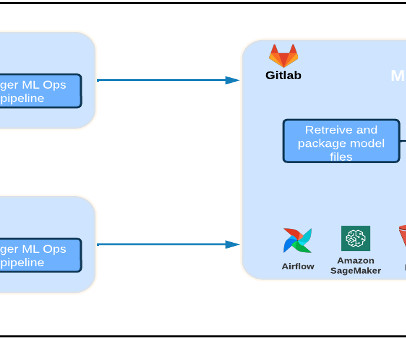
It is critical for the VMware Carbon Black team to design and build a custom end-to-end MLOps pipeline that orchestrates and automates workflows in the ML lifecycle and enables model training, evaluations, and deployments. Amazon SNS is fully managed pub/sub service for A2A and A2P messaging.
Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. SageMaker simplifies the process of managing dependencies, container images, auto scaling, and monitoring. They often work with DevOps engineers to operate those pipelines.
The AWS portfolio of ML services includes a robust set of services that you can use to accelerate the development, training, and deployment of machine learning applications. The suite of services can be used to support the complete model lifecycle including monitoring and retraining ML models.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. Following are the steps completed by using APIs to create and share a model package group across accounts.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute data science workflows.
This allows you to share the intended uses and assessed carbon impact of a model so that datascientists, MLengineers, and other teams can make informed decisions when choosing and running models. Unlike persistent endpoints, clusters are decommissioned when a batch transform job is complete.
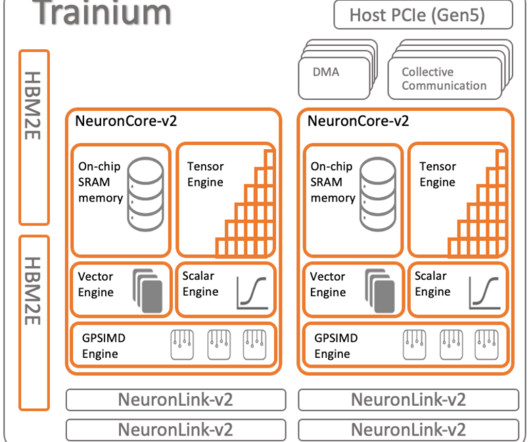
Take for example operators such as TopK, LayerNorm, or ZeroCompression, which read data from memory and only use it for a minimal number of ALU calculations. Regular CPU systems are completely memory bound for these calculations, and performance is limited by the time required to move the data into the CPU.
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. 2xlarge instances.
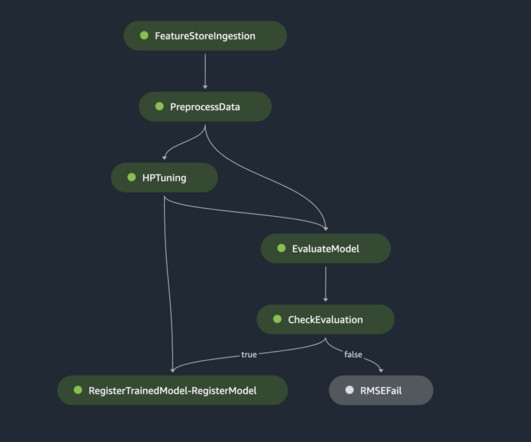
The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. MLengineers no longer need to manage this training metadata separately. We define another pipeline step, step_cond.
ML model builders spend a ton of time running multiple experiments in a data science notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. 42% of datascientists are solo practitioners or on teams of five or fewer people.
Datascientists need to track and compare the performance of different machine learning models while using different hyperparameters. When working on an ML project, we must compare various machine learning models with different hyperparameters and want to understand which models and hyperparameters are most effective for our use case.
Create a KMS key in the dev account and give access to the prod account Complete the following steps to create a KMS key in the dev account: On the AWS KMS console, choose Customer managed keys in the navigation pane. Choose Create key. For Key type , select Symmetric. For Script Path , enter Jenkinsfile. Choose Save.
Most of our customers are doing ML/MLOps at a reasonable scale, NOT at the hyperscale of big-tech FAANG companies. Not a fork: – The MLOps team should consist of a DevOps engineer, a backend software engineer, a datascientist, + regular software folks. How about the MLengineer? Let me explain.
Datascientists have to address challenges like data partitioning, load balancing, fault tolerance, and scalability. MLengineers must handle parallelization, scheduling, faults, and retries manually, requiring complex infrastructure code.
I originally did a master's degree in physics focusing on astrophysics, but around that time, I noticed the breakthroughs happening in ML so I decided to switch the focus of my studies towards ML. data or auto-generated files). cell outputs) for code completion in Jupyter notebooks (see this Jupyter plugin ).
Amazon SageMaker is a fully managed service that allows developers and datascientists to quickly build, train, and deploy machine learning (ML) models. With SageMaker, you can deploy your ML models on hosted endpoints and get real-time inference results.
autogpt : Auto-GPT is an “Autonomous AI agent” that given a goal in natural language, will allow Large Language Models (LLMs) to think, plan, and execute actions for us autonomously. ML/AI Enthusiasts, and Learners Citizen DataScientists who prefer a low code solution for quick testing. It uses OpenAI’s GPT-4 or GPT-3.5
is an auto-regressive language model that uses an optimized transformer architecture. 405B-Instruct You can use Llama models for text completion for any piece of text. The Llama 3.1 At its core, Llama 3.1 Model Name Model ID Default instance type Supported instance types Meta-Llama-3.1-8B 24xlarge, ml.p5.48xlarge Meta-Llama-3.1-8B-Instruct
People will auto-scale up to 10 GPUs to handle the traffic. Let’s assume that we have a model in production that is retrained manually by datascientists, potentially a change of network architecture, extra features, stuff like that every three months. Kyle: That’s a really good question.
SageMaker AI makes sure that sensitive data stays completely within each customer’s SageMaker environment and will never be shared with a third party. It also empowers datascientists and MLengineers to do more with their models by collaborating seamlessly with their colleagues in data and analytics teams.
It allows datascientists and machine learning engineers to interact with their data and models and to visualize and share their work with others with just a few clicks. SageMaker Canvas has also integrated with Data Wrangler , which helps with creating data flows and preparing and analyzing your data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content