This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels. Because Katana integrates purchasing, sales, and manufacturing in one place, it helps businesses avoid manual data transfer and reduces the risk of errors in production planning.
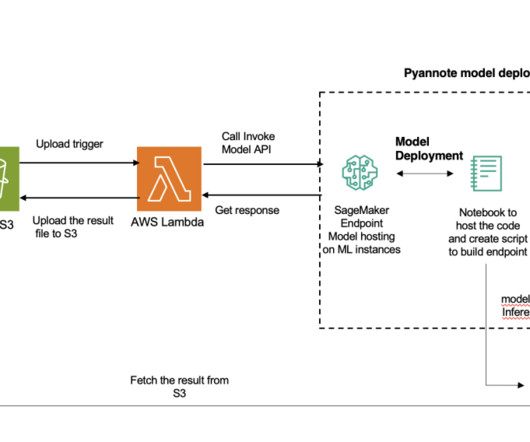
Solution overview The following diagram illustrates iFoods legacy architecture, which had separate workflows for data science and engineering teams, creating challenges in efficiently deploying accurate, real-time machine learning models into production systems. The ML platform empowers the building and evolution of ML systems.
If we consider a simple example: a user inquiring about New York City's weather, ChatGPT, leveraging plugins, could interact with an external weather API, interpret the data, and even course-correct based on the responses received. AI Agents vs. ChatGPT Many advanced AI agents, such as Auto-GPT and BabyAGI, utilize the GPT architecture.
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
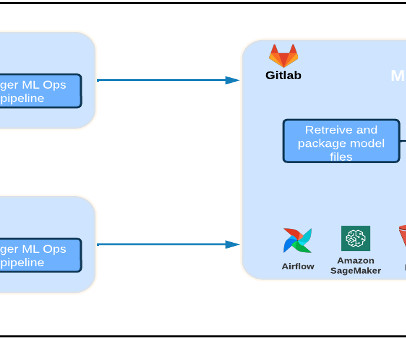
A RayJob also manages the lifecycle of the Ray cluster, making it ephemeral by automatically spinning up the cluster when the job is submitted and shutting it down when the job is complete. The following diagram illustrates the complete architecture you have built after completing these steps.
As an extension of Support Vector Machines (SVM) , Support Vector Regression has revolutionized how datascientists approach complex regression problems. Its ability to handle complex nonlinear relationships while maintaining robust predictions makes it invaluable for datascientists and machine learning engineers.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for datascientists and machine learning (ML) engineers.
GitHub Copilot GitHub Copilot is an AI-powered code completion tool that analyzes contextual code and delivers real-time feedback and recommendations by suggesting relevant code snippets. Tabnine Tabnine is an AI-based code completion tool that offers an alternative to GitHub Copilot.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
Generative AI auto-summarization creates summaries that employees can easily refer to and use in their conversations to provide product, service or recommendations (and it can also categorize and track trends). In another instance, Lloyds Banking Group was struggling to meet customer needs with their existing web and mobile application.
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. SageMaker features and capabilities help developers and datascientists get started with natural language processing (NLP) on AWS with ease.
There are two main purposes for building this pipeline: support the datascientists for late-stage model development, and surface model predictions in the product by serving models in high volume and in real-time production traffic. Amazon SNS is fully managed pub/sub service for A2A and A2P messaging.
For a complete list of runtime configurations, please refer to text-generation-launcher arguments. SageMaker endpoints also support auto-scaling, allowing DeepSeek-R1 to scale horizontally based on incoming request volume while seamlessly integrating with elastic load balancing. GenAI DataScientist at AWS.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
The suite of services can be used to support the complete model lifecycle including monitoring and retraining ML models. Collaboration – Datascientists each worked on their own local Jupyter notebooks to create and train ML models. They lacked an effective method for sharing and collaborating with other datascientists.
Enterprises seeking to harness the power of AI must establish a data pipeline that involves extracting data from diverse sources, transforming it into a consistent format and storing it efficiently. The company found that datascientists were having to remove features from algorithms just so they would run to completion.
By surrounding unparalleled human expertise with proven technology, data and AI tools, Octus unlocks powerful truths that fuel decisive action across financial markets. Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle.
Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!) Whether you’re an experienced datascientist working with time series or a newcomer to the field, join us! We encourage you to complete your user registration here: [link].
Tabnine for JupyterLab Typing code is complex without auto-complete options, especially when first starting out. In addition to the spent time inputting method names, the absence of auto-complete promotes shorter naming styles, which is not ideal. For a development environment to be effective, auto-complete is crucial.
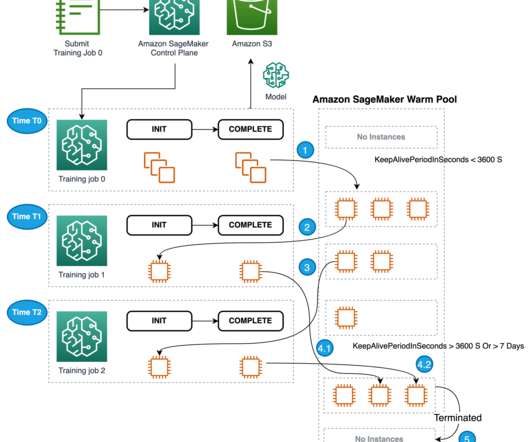
Datascientists train multiple ML algorithms to examine millions of consumer data records, identify anomalies, and evaluate if a person is eligible for credit. This is a common problem that datascientists face when training their models. The below workflow depicts a series of training job runs using warm pool.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. Following are the steps completed by using APIs to create and share a model package group across accounts.
In such cases, datascientists have to provide these parameters to their ML model training and deployment code manually, by noting down subnets, security groups, and KMS keys. This puts the onus on the datascientists to remember to specify these configurations, to successfully run their jobs, and avoid getting Access Denied errors.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute data science workflows.
With SageMaker, datascientists and developers can quickly and effortlessly build and train ML models, and then directly deploy them into a production-ready hosted environment. Overview of solution Five people from Getir’s data science team and infrastructure team worked together on this project.
This integration of model development and sharing creates a tighter collaboration between business and data science teams and lowers time to value. Business teams can use existing models built by their datascientists or other departments to solve a business problem instead of rebuilding new models in outside environments.
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
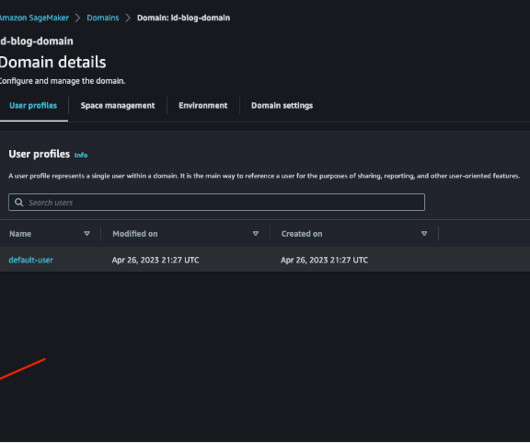
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. When this is complete, the document can be routed to the appropriate department or downstream process. The following diagram outlines the proposed solution architecture. append(e["Text"].upper())
Optionally, if you’re using Snowflake OAuth access in SageMaker Data Wrangler, refer to Import data from Snowflake to set up an OAuth identity provider. Datascientists should have the following prerequisites Access to Amazon SageMaker , an instance of Amazon SageMaker Studio , and a user for SageMaker Studio.
jpg and the complete metadata from styles/38642.json. About the Authors Antonia Wiebeler is a DataScientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Daniel Zagyva is a DataScientist at AWS Professional Services. bias="none", # the bias type for Lora.
Going from Data to Insights LexisNexis At HPCC Systems® from LexisNexis® Risk Solutions you’ll find “a consistent data-centric programming language, two processing platforms, and a single, complete end-to-end architecture for efficient processing.” These tools are designed to help companies derive insights from big data.
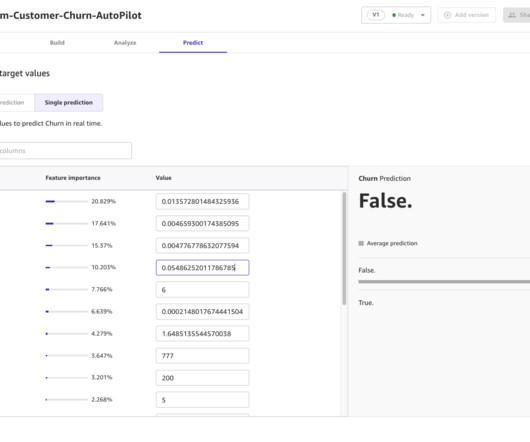
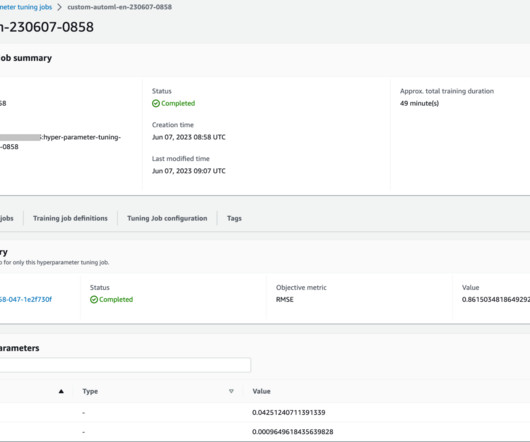
It plays a crucial role in every model’s development process and allows datascientists to focus on the most promising ML techniques. Additionally, AutoML provides a baseline model performance that can serve as a reference point for the data science team. The following diagram presents the overall solution workflow.
The previous blog posts, “Data Acquisition & Exploration” and “Data Transformation and Feature Engineering”, explored how AWS SageMaker’s capabilities can help datascientists collaborate and accelerate data exploration, understanding, transformation, and feature engineering. Source: Image by the author.
For any machine learning (ML) problem, the datascientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
Amazon SageMaker is a fully managed service that enables developers and datascientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. You can also edit the auto scaling policy on the Auto-scaling tab on this page. SageMaker provides a variety of options to deploy models.
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. Using PyTorch Neuron gives datascientists the ability to track training progress in a TensorBoard. This results in faster restarts and workload completion.
Amazon SageMaker is a fully managed service that allows developers and datascientists to quickly build, train, and deploy machine learning (ML) models. Based on customer SLAs and data volume, we can choose batch inference, real-time hosting with auto-scaling, or serverless hosting.
Usually agents will have: Some kind of memory (state) Multiple specialized roles: Planner – to “think” and generate a plan (if steps are not predefined) Executor – to “act” by executing the plan using specific tools Feedback provider – to assess the quality of the execution by means of auto-reflection.
Take for example operators such as TopK, LayerNorm, or ZeroCompression, which read data from memory and only use it for a minimal number of ALU calculations. Regular CPU systems are completely memory bound for these calculations, and performance is limited by the time required to move the data into the CPU.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
The models can be completely heterogenous, with their own independent serving stack. After these business logic steps are complete, the inputs are passed through to ML models. And during idle time, it should be able to turn off compute capacity completely so that you’re not charged. ML inference options.
This allows you to share the intended uses and assessed carbon impact of a model so that datascientists, ML engineers, and other teams can make informed decisions when choosing and running models. If your workloads can tolerate latency, consider deploying your model on Amazon SageMaker Asynchronous Inference with auto-scaling groups.
SageMaker and Forethought SageMaker is a fully managed service that provides developers and datascientists the ability to build, train, and deploy ML models quickly. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. 2xlarge instances.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























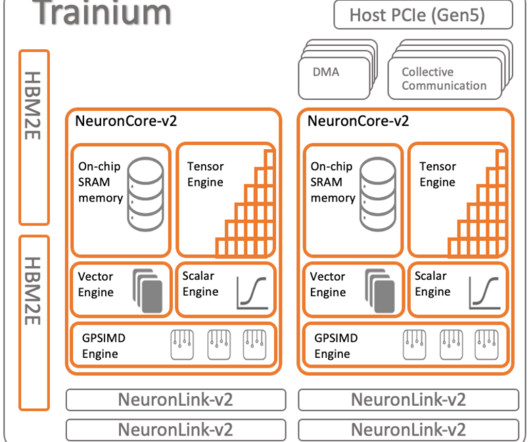










Let's personalize your content