This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Future AGIs proprietary technology includes advanced evaluation systems for text and images, agent optimizers, and auto-annotation tools that cut AI development time by up to 95%. Enterprises can complete evaluations in minutes, enabling AI systems to be optimized for production with minimal manual effort.
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels. Because Katana integrates purchasing, sales, and manufacturing in one place, it helps businesses avoid manual data transfer and reduces the risk of errors in production planning.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for DataScience and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
If we consider a simple example: a user inquiring about New York City's weather, ChatGPT, leveraging plugins, could interact with an external weather API, interpret the data, and even course-correct based on the responses received. AI Agents vs. ChatGPT Many advanced AI agents, such as Auto-GPT and BabyAGI, utilize the GPT architecture.
For the complete list of model IDs, see Amazon Bedrock model IDs. After the deployment is complete, you have two options. On the Outputs tab, note of the output values to complete the next steps. Wait for AWS CloudFormation to finish the stack creation. The preferred option is to use the provided postdeploy.sh
These organizations are shaping the future of the AI and datascience industries with their innovative products and services. Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery. Check them out below.
It suggests code snippets and even completes entire functions based on natural language prompts. TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs).
EKS Blueprints helps compose complete EKS clusters that are fully bootstrapped with the operational software that is needed to deploy and operate workloads. Trigger federated training To run federated training, complete the following steps: On the FedML UI, choose Project List in the navigation pane. Choose New Application.
One technique used to solve this problem today is auto-labeling, which is highlighted in the following diagram for a modular functions design for ADAS on AWS. Auto-labeling overview Auto-labeling (sometimes referred to as pre-labeling ) occurs before or alongside manual labeling tasks. kernel in Studio on an ml.m5.large
SageMaker Studio is a fully integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models, improving datascience team productivity by up to 10x.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!) We welcome contributions from not just developers, but also regular users and early career data scientists who want to help shape the direction of sktime. Classification? Annotation?
Finance Organizations Detect Fraud in a Fraction of a Second Financial organizations face a significant challenge in detecting patterns of fraud due to the vast amount of transactional data that requires rapid analysis. Additionally, the scarcity of labeled data for actual instances of fraud poses a difficulty in training AI models.
By responsibly building proprietary AI models created with Verisk’s extensive clinical, claims, and datascience expertise, complex and unstructured documents are automatically organized, reviewed, and summarized. The following figure shows the Discovery Navigator generative AI auto-summary pipeline.
It plays a crucial role in every model’s development process and allows data scientists to focus on the most promising ML techniques. Additionally, AutoML provides a baseline model performance that can serve as a reference point for the datascience team. The following diagram presents the overall solution workflow.
Generating Longer Forecast Output Patches In Large Language Models (LLMs), output is generally produced in an auto-regressive manner, generating one token at a time. However, research suggests that for long-horizon forecasting, predicting the entire horizon at once can lead to better accuracy compared to multi-step auto-regressive decoding.
Tabnine for JupyterLab Typing code is complex without auto-complete options, especially when first starting out. In addition to the spent time inputting method names, the absence of auto-complete promotes shorter naming styles, which is not ideal. For a development environment to be effective, auto-complete is crucial.
Overview of solution Five people from Getir’s datascience team and infrastructure team worked together on this project. The project was completed in a month and deployed to production after a week of testing. He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager.
Each business problem is different, each dataset is different, data volumes vary wildly from client to client, and data quality and often cardinality of a certain column (in the case of structured data) might play a significant role in the complexity of the feature engineering process.
Open DataScience Blog Recap Paris-based Mistral AI is emerging as a formidable challenger to industry giants like OpenAI and Anthropic. Open DataScience Blog Recap Paris-based Mistral AI is emerging as a formidable challenger to industry giants like OpenAI and Anthropic.
medium instance and the DataScience 3.0 First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as DataScience and Kernel as Python 3. jpg and the complete metadata from styles/38642.json. She graduated from TU Delft with a degree in DataScience & Technology.
When you create an AWS account, you get a single sign-on (SSO) identity that has complete access to all the AWS services and resources in the account. Signing in to the AWS Management Console using the email address and password that you used to create the account gives you complete access to all the AWS resources in your account.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
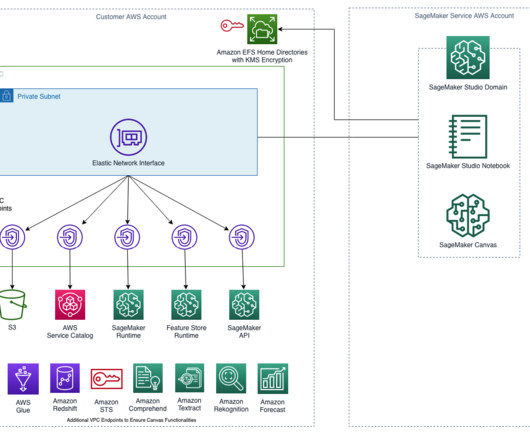
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
In this post, we use Amazon SageMaker Studio with the DataScience 3.0 Install prerequisites to fine tuning the Falcon-7B model Launch the notebook falcon-7b-qlora-remote-decorator_qa.ipynb in SageMaker Studio by selecting the I mage as DataScience and Kernel as Python 3. For details, refer to Creating an AWS account.
Apart from the clear performance benefit, we can be much more confident the agent will remain on track and complete the task. 2: A structured agentic flow with deterministic auto-fixing When dealing with problems in the generated output, I believe it’s best to do as much of the correction deterministically, without involving the LLM again.
To remove an element, omit the text parameter completely. A compact 5-cup single serve coffee maker in matt black with travel mug auto-dispensing feature. - AI/ML Solutions Architect at AWS, focusing on generative AI and applies his knowledge in datascience and machine learning to provide practical, cloud-based business solutions.
Usually agents will have: Some kind of memory (state) Multiple specialized roles: Planner – to “think” and generate a plan (if steps are not predefined) Executor – to “act” by executing the plan using specific tools Feedback provider – to assess the quality of the execution by means of auto-reflection.
For more complex issues like label errors, you can again simply filter out all the auto-detected bad data. For instance, when fine-tuning various LLM models on a text classification task (politeness prediction), this auto-filtering improves LLM performance without any change in the modeling code!
Bigram Models Simplified Image generated by ChatGPT Introduction to Text Generation In Natural Language Processing, text generation creates text that can resemble human writing, ranging from simple tasks like auto-completing sentences to complex ones like writing articles or stories.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
ML model builders spend a ton of time running multiple experiments in a datascience notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. 42% of data scientists are solo practitioners or on teams of five or fewer people.
prompt -> LLM prompt -> LLM -> prompt -> LLM retriever -> response synthesizer As a full DAG (more expressive) When you are required to set up a complete DAG, for instance, a Retrieval Augmented Generation (RAG) pipeline.
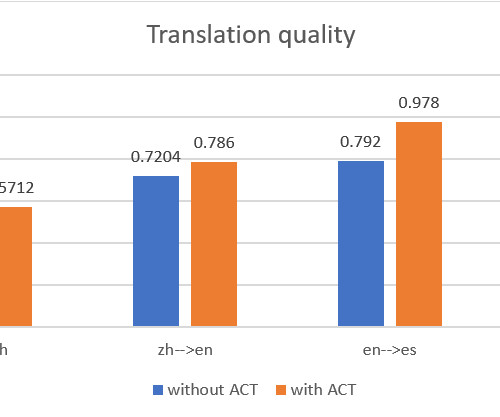
When the job is complete, the parallel data status shows as Active and is ready to use. Run asynchronized batch translation using parallel data The batch translation can be conducted in a process where multiple source documents are automatically translated into documents in target languages.
A graph represents the edges between a collection of nodes; in terms of data, this means the relations between entities or data points. Each component the of graph (like the edges, nodes or the complete graph) can store information. Graphs are an abstract data structure that have a powerful data representation technique.
Evaluating Prompt Completion: The goal is to establish effective evaluation criteria to gauge LLMs’ performance across tasks and domains. Auto Eval Common Metric Eval Human Eval Custom Model Eval 3. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Complete the following steps to edit an existing space: On the space details page, choose Stop space. With this feature, you can do the following: Share data – EFS mounts are ideal for storing large datasets crucial for datascience experiments. Choose Create JupyterLab space. For Name , enter a name for your Space.
trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
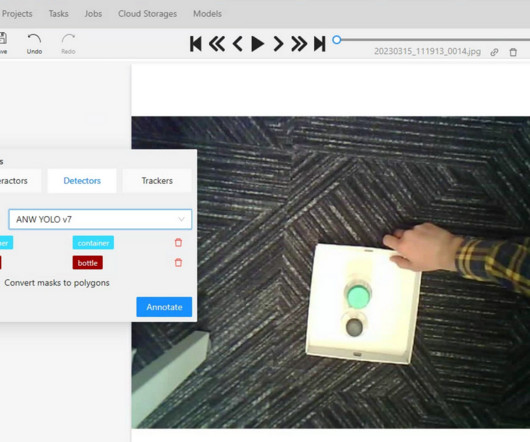
the UI for annotation, image ref: [link] The base containers that run when we put the CVAT stack up (not included auto annotation) (Semi) automated annotation The CVAT (semi) automated annotation allow user to use something call nuclio , which is a tool aimed to assist automated datascience through serverless deployment.
Comet Comet is a machine learning platform built to help data scientists and ML engineers track, compare, and optimize machine learning experiments. It is beneficial for organizing and managing experiments and analyzing and visualizing the results of those datascience experiments. Thanks for reading!
According to OpenAI , “Over 300 applications are delivering GPT-3–powered search, conversation, text completion, and other advanced AI features through our API.” Data Scientists may think the future of AI is GPT-3, and it has created new possibilities in the AI landscape. I am here to convince you not to worry. Believe me.”.
A perfect F1 score of 1 indicates that the model has achieved both perfect precision and perfect recall, and a score of 0 indicates that the model’s predictions are completely wrong. Finally, when it’s complete, the pane will show a list of columns with its impact on the model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content