This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Test the knowledge base Once the data sync is complete: Choose the expansion icon to expand the full view of the testing area.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. in a code subdirectory. in a code subdirectory.
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. The company found that data scientists were having to remove features from algorithms just so they would run to completion.
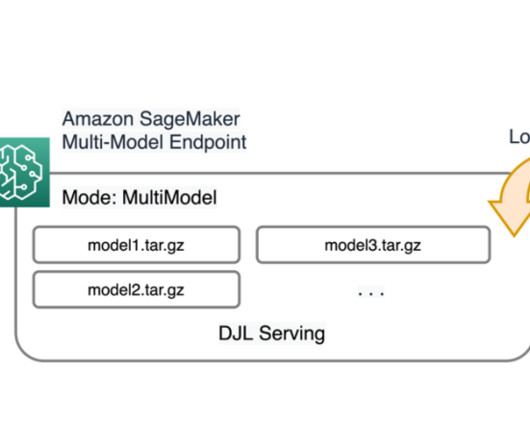
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the complete model lineage with data/models/experiments used downstream?
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. Triton uses TorchScript for improved performance and flexibility.
When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console. These JSON files will contain all the Amazon Textract metadata, including the text that was extracted from within the documents. His focus is natural language processing and computervision.
In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion. All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
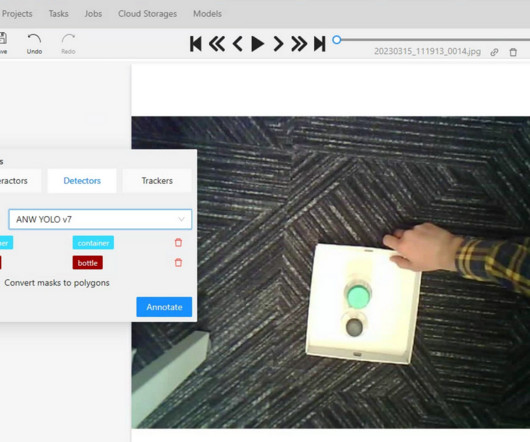
that comply to YOLOv5 with specific requirement on model output, which easily got mess up thru conversion of model from PyTorch > ONNX > Tensorflow > TensorflowJS) ComputerVision Annotation Tool (CVAT) CVAT is build by Intel for doing computervision annotation which put together openCV, OpenVino (to speed up CPU inference).
in their paper Auto-Encoding Variational Bayes. script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. Auto-Encoding Variational Bayes. Or requires a degree in computer science? The config.py
Source Architecture and training PaLM-E is a decoder-only LLM that auto-regressively generates text using a multimodal prompt consisting of text, tokenized image embeddings, and state estimates representing quantities like a robot’s position, orientation, and velocity. lack of annotated data, unreliable labels, noisy inputs).
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Always make sure that sensitive data is handled securely to avoid potential security risks.
Although this post focuses on LLMs, most of its best practices are relevant for any kind of large-model training, including computervision and multi-modal models, such as Stable Diffusion. Amazon FSx is an open-source parallel file system, popular in high-performance computing (HPC).
But nowadays, it is used for various tasks, ranging from language modeling to computervision and generative AI. This helps in training large AI models, even on computers with little memory. <pre <pre class =" hljs " style =" display : block; overflow-x: auto; padding: 0.5
We decided to analyze the images in the following ways: Split the image into tiles and use tiles as input to a computervision model Extract histograms of colors in images Tile generation The raw TIFF input images are too big to use for processing directly. Tile embedding Computervision is a complex problem.
In order to power these applications, as well as those using other data modalities like computervision, we need a robust and efficient workflow to quickly annotate data, train and evaluate models, and iterate quickly. As part of this strategy, they developed an in-house passport analysis model to verify passenger IDs.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. The meticulous nature of this process, combined with the continuous need for scaling, has subsequently led to the development of the auto-evaluation capability.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content