This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. One of LLMs most fascinating strengths is their inherent ability to understand context.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. Follow Octus on LinkedIn and X.
The automation provided by Rad AI Impressions not only reduces burnout, but also safeguards against errors arising from manual repetition. For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3
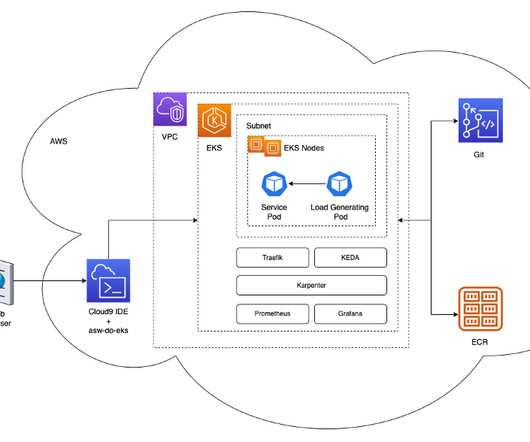
The platform both enables our AI—by supplying data to refine our models—and is enabled by it, capitalizing on opportunities for automated decision-making and data processing. We use Amazon EKS and were looking for the best solution to auto scale our worker nodes. This enables all steps to be completed from a web browser.
This requires not only well-designed features and ML architecture, but also data preparation and ML pipelines that can automate the retraining process. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. ML engineers no longer need to manage this training metadata separately.
With a decade of enterprise AI experience, Veritone supports the public sector, working with US federal government agencies, state and local government, law enforcement agencies, and legal organizations to automate and simplify evidence management, redaction, person-of-interest tracking, and eDiscovery.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. It can take up to 20 minutes for the setup to complete.
Auto-Completion and Refactoring: Enhances coding efficiency and readability. The Python Indent extension automates indentation management, ensuring that your code adheres to best practices. Key Features: Comprehensive Versioning: Beyond just data, DVC versions metadata, plots, models, and entire ML pipelines.
This time-consuming process must be completed before content can be dubbed into another language. Through automation, ZOO Digital aims to achieve localization in under 30 minutes. However, the supply of skilled people is being outstripped by the increasing demand for content, requiring automation to assist with localization workflows.
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. Prerequisites Complete the following prerequisite steps: Make sure you have model access in Amazon Bedrock.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
Furthermore, the dynamic nature of a customer’s data can also result in a large variance of the processing time and resources required to optimally complete the feature engineering. For a given dataset and preprocessing job, the CPU may be undersized, resulting in maxed out processing performance and lengthy times to complete.
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. jpg and the completemetadata from styles/38642.json. From here, we can fetch the image for this product from images/38642.jpg
This feature streamlines the process of launching new instances with the most up-to-date Neuron SDK, enabling you to automate your deployment workflows and make sure you’re always using the latest optimizations. AWS Systems Manager Parameter Store support Neuron 2.18 neuronx-py310-sdk2.18.2-ubuntu20.04 COPY train.py /train.py
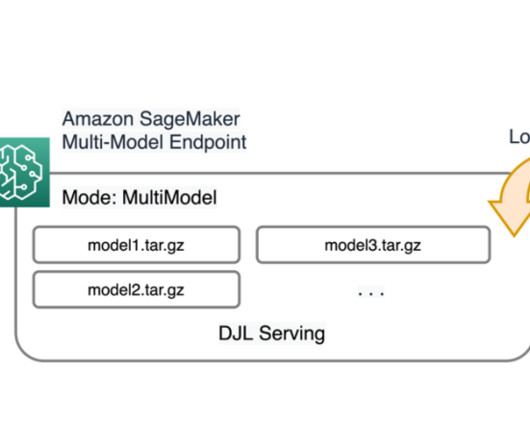
SageMaker simplifies the process of managing dependencies, container images, auto scaling, and monitoring. Specifically for the model building stage, Amazon SageMaker Pipelines automates the process by managing the infrastructure and resources needed to process data, train models, and run evaluation tests.
The integration of large language models helps humanize the interaction with automated agents, creating a more engaging and satisfying support experience. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. The following diagram illustrates our legacy architecture.
It also enables operational capabilities including automated testing, conversation analytics, monitoring and observability, and LLM hallucination prevention and detection. “We Leave the four entries for Index Details at their default values (index name, vector field name, metadata field name, and text field name). seconds or less.
You can use large language models (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering. Solution overview The Meeting Notes Generator Solution creates an automated serverless pipeline using AWS Lambda for transcribing and summarizing audio and video recordings of meetings.
Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. We need both automated continuous monitoring AND periodic manual inspection. There will be only one type of ML metadata store (model-first), not three. Some feedback loops can be automated, but some cannot.
Evaluating this faithfulness, which also serves to measure the presence of hallucinated content, in an automated manner is non-trivial, especially for open-ended responses. Evaluating RAG systems at scale requires an automated approach to extract metrics that are quantitative indicators of its reliability.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from data preparation to model deployment. In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion.
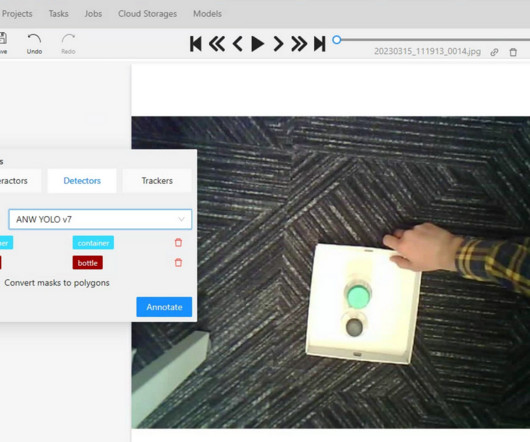
the UI for annotation, image ref: [link] The base containers that run when we put the CVAT stack up (not included auto annotation) (Semi) automated annotation The CVAT (semi) automated annotation allow user to use something call nuclio , which is a tool aimed to assist automated data science through serverless deployment.
With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization from a single visual interface. million reviews spanning May 1996 to July 2014. Next, select a training method.
script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. W&B Sweeps is a powerful tool to automate hyperparameter optimization. W&B Sweeps will automate this kind of exploration. Unless you specify Spot Instances in conf, instances will be created on demand.
auto-evaluation) and using human-LLM hybrid approaches. It will take as input the text generated by an LLM and some metadata, and then output a score that indicates the quality of the text. Both reference comparisons and criteria-based evaluations can be executed either by human evaluators or through automated processes.
FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. and above, AWS contributed an automated communication algorithm selection logic for EFA networks ( NCCL_ALGO can be left unset). Note that effective in NCCL 2.12
Model management Teams typically manage their models, including versioning and metadata. Monitoring Monitor model performance for data drift and model degradation, often using automated monitoring tools. Feedback loops: Use automated and human feedback to improve prompt design continuously. using techniques like RLHF.)
You would address it in a completely different way, depending on what’s the problem. This is more about picking, for some active learning or for knowing where the data comes from and knowing the metadata to focus on the data that are the most relevant to start with. This is a much smaller scale than Auto ML.
Others, toward language completion and further downstream tasks. In terms of technology: generating code snippets, code translation, and automated documentation. In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting.
Others, toward language completion and further downstream tasks. In terms of technology: generating code snippets, code translation, and automated documentation. In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting.
That’s why the clinic wants to harness the power of deep learning in a bid to help healthcare professionals in an automated way. Using new_from_file only loads image metadata. But it’s not easy to spot the tell-tale signs in scans. Unfortunately, the competition rules prevent us from publishing competition data publicly.
In this post, we discuss how United Airlines, in collaboration with the Amazon Machine Learning Solutions Lab , build an active learning framework on AWS to automate the processing of passenger documents. “In We used Amazon Textract to automate information extraction from specific document fields such as name and passport number.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
This capability allows for the seamless addition of SageMaker HyperPod managed compute to EKS clusters, using automated node and job resiliency features for foundation model (FM) development. Automated node recovery – HyperPod performs managed, lightweight, and non-invasive checks , coupled with automated node replacement capability.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
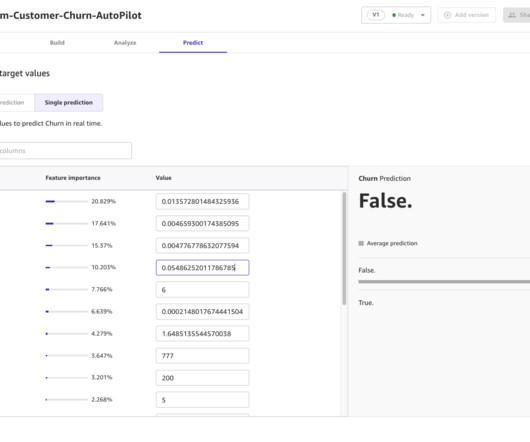
Use Autopilot and Canvas Autopilot automates key tasks of an automatic ML (AutoML) process like exploring data, selecting the relevant algorithm for the problem type, and then training and tuning it. Complete the steps listed in the README file. Set the target column as churn. Let’s assume the role of a data scientist.
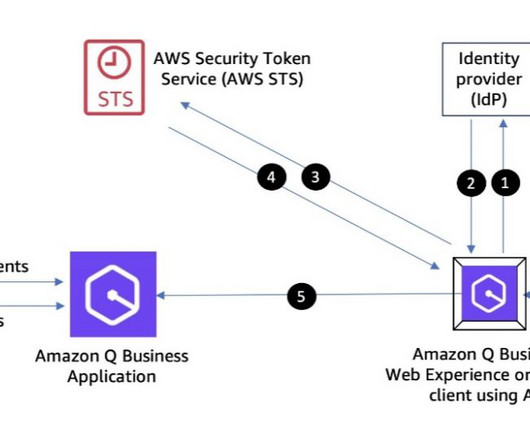
Amazon Q Business is a conversational assistant powered by generative AI that enhances workforce productivity by answering questions and completing tasks based on information in your enterprise systems, which each user is authorized to access. illustrate how the administrators can automate Steps 2 and 3 using AWS APIs.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. The meticulous nature of this process, combined with the continuous need for scaling, has subsequently led to the development of the auto-evaluation capability.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content