This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
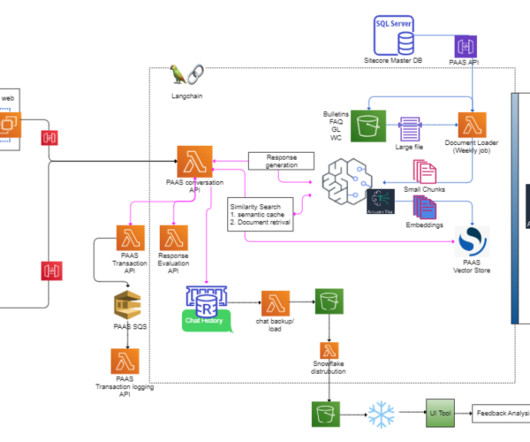
PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation. PAAS offers a wide range of essential services, including more than 40,000 classification guides and more than 500 bulletins.
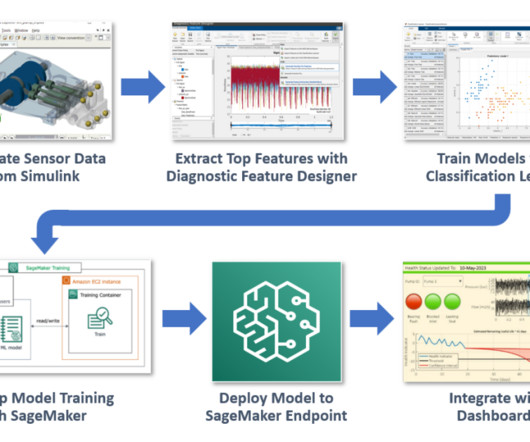
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Here, you use Auto Features , which quickly extracts a broad set of time and frequency domain features from the dataset and ranks the top candidates for model training. classifierModel = fitctree(.
The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brands reputation. Consider another use case of generating personalized product descriptions for an ecommerce site.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
Use case overview The use case outlined in this post is of heart disease data in different organizations, on which an ML model will run classification algorithms to predict heart disease in the patient. module.eks_blueprints_kubernetes_addons -auto-approve terraform destroy -target=module.m_fedml_edge_client_2.module.eks_blueprints_kubernetes_addons
When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. With a background in softwareengineering, she organically moved into an architecture role.
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, softwareengineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps? We also save the trained model as an artifact using wandb.save().
We train an XGBoost model for a classification task on a credit card fraud dataset. Model Framework XGBoost Model Size 10 MB End-to-End Latency 100 milliseconds Invocations per Second 500 (30,000 per minute) ML Task Binary Classification Input Payload 10 KB We use a synthetically created credit card fraud dataset.
In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence). Auto Regression is common in more than just Transformers. This is where autoencoding models come into play.
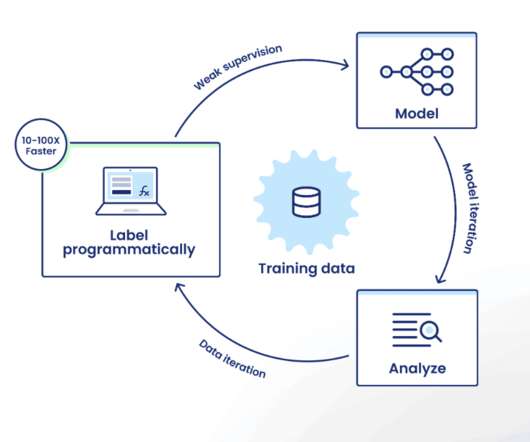
If you’re not familiar with the Snorkel Flow platform, the iteration loop looks like this: Label programmatically: Encode labeling rationale as labeling functions (LFs) that the platform uses as sources of weak supervision to intelligently auto-label training data at scale. Auto-generated tag-based LFs. Streamlined tagging workflows.
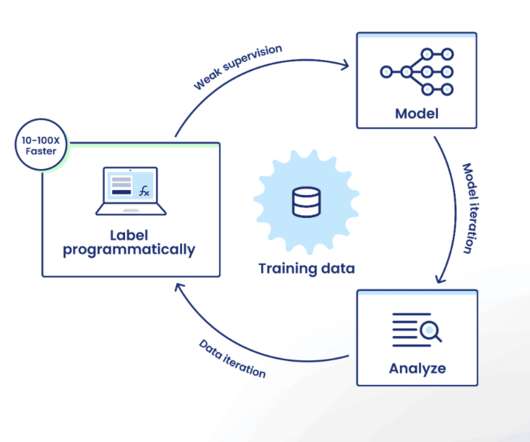
If you’re not familiar with the Snorkel Flow platform, the iteration loop looks like this: Label programmatically: Encode labeling rationale as labeling functions (LFs) that the platform uses as sources of weak supervision to intelligently auto-label training data at scale. Auto-generated tag-based LFs. Streamlined tagging workflows.
Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. The platform provides a comprehensive set of annotation tools, including object detection, segmentation, and classification.
What sets this challenge apart from any other reinforcement learning problems is the fact that a classification needs to be made at the end of this agent’s interaction with this MDP — the decision of whether the MDP is the same as the reference MDP or not. Figure 7 : Performance of different bug classification models with different RL agents.
What I mean is when data scientists are working hand in hand with softwareengineers or MLOps engineers, that would then take over or wrap up the solution. What’s your approach to different modalities of classification detection and segmentation? ” Michal: To be honest, we don’t use Auto ML too often.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. Nitin Eusebius is a Sr.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content