This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brands reputation. Consider another use case of generating personalized product descriptions for an ecommerce site.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. Amazon Comprehend custom classification API is used to organize your documents into categories (classes) that you define. Custom classification is a two-step process.
Existing sales and service engineers can use language-based generative AI to augment their skills and easily find contextual or industrial knowledge to help them deliver better customer experiences or solve problems faster. Besides their conventional programming skills, engineers can now add “promptengineer” to their skill set.
CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification. This is where the power of auto-tagging and attribute generation comes into its own. Moreover, auto-generated tags or attributes can substantially improve product recommendation algorithms.
They’re capable of performing a wide variety of general tasks with a high degree of accuracy based on input prompts. LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction. Promptengineering is an iterative process.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal promptengineering. In this case, the model choice needs to be revisited or further promptengineering needs to be done.
We train an XGBoost model for a classification task on a credit card fraud dataset. Model Framework XGBoost Model Size 10 MB End-to-End Latency 100 milliseconds Invocations per Second 500 (30,000 per minute) ML Task Binary Classification Input Payload 10 KB We use a synthetically created credit card fraud dataset.
Make sure that you import Comet library before PyTorch to benefit from auto logging features Choosing Models for Classification When it comes to choosing a computer vision model for a classification task, there are several factors to consider, such as accuracy, speed, and model size. Pre-trained models, such as VGG, ResNet.
Zero-Shot NER Prompts are now available for FREE Promptengineering is gaining traction as a fast-evolving discipline that aims to guide advanced language models like GPT-3 to generate precise and intended results, such as answering queries or constructing meaningful narratives.
There are several ways to enhance fine tuning through effective promptengineering and here are a few examples. Sample text prompts to descibe some of the most common design elements of casual long skirts for ladies: Design Style: A-line, wrap, maxi, mini, and pleated skirts are some of the most popular styles for casual wear.
The platform also offers features for hyperparameter optimization, automating model training workflows, model management, promptengineering, and no-code ML app development. Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on.
Tools range from data platforms to vector databases, embedding providers, fine-tuning platforms, promptengineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. with efficient methods and enhancing model performance through promptengineering and retrieval augmented generation (RAG).
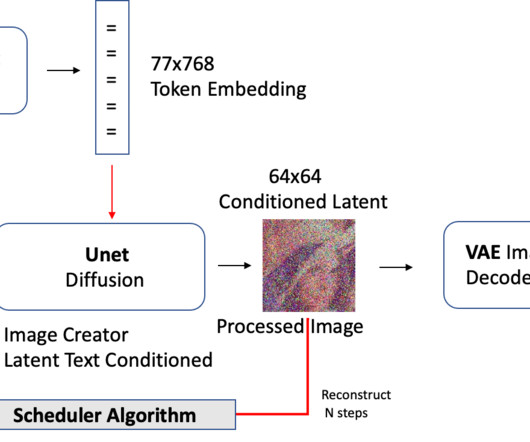
This can be performed using an auto-encoder for instance (remember than an auto-encoder is used to learn efficient low dimensional embeddings of some high dimensional space). Denoising Process Summary Text from a prompt is tokenized and encoded numerically. Scheduler — essentially ODE integration techniques.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
The Inference Challenge with Large Language Models Before the advent of LLMs, natural language processing relied on smaller models focused on specific tasks like text classification, named entity recognition, and sentiment analysis. Let's start by understanding why LLM inference is so challenging compared to traditional NLP models.
It not only requires SQL mastery on the part of the annotator, but also more time per example than more general linguistic tasks such as sentiment analysis and text classification. Enriching the prompt with database information Text2SQL is an algorithm at the interface between unstructured and structured data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content