This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recent advancements in deeplearning offer a transformative approach by enabling end-to-end learning models that can directly process raw biomedical data. Despite the promise of deeplearning in healthcare, its adoption has been limited due to several challenges.
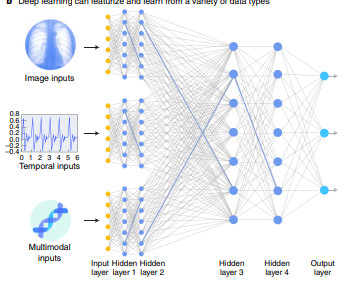
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier.
Second, the White-Box Preset implements simple interpretable algorithms such as Logistic Regression instead of WoE or Weight of Evidence encoding and discretized features to solve binary classification tasks on tabular data. Finally, the CV Preset works with image data with the help of some basic tools.
How pose estimation works: Deeplearning methods Use Cases and pose estimation applications How to get started with AI motion analysis Real-time full body pose estimation in construction – built with Viso Suite About us: Viso.ai Definition: What is pose estimation? Variations: Head pose estimation, animal pose estimation, etc.
This article lists the top TensorFlow courses that can help you gain the expertise needed to excel in the field of AI and machine learning. TensorFlow fundamentals This course introduces the fundamentals of deeplearning with TensorFlow, covering key concepts and practical knowledge for building machine learning models.
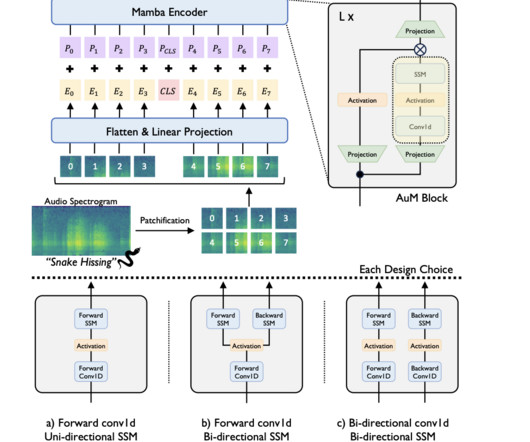
Audio classification has evolved significantly with the adoption of deeplearning models. Transformers surpass CNNs in performance, creating a paradigm shift in deeplearning, especially for functions requiring extensive contextual understanding and handling diverse input data types.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Armed with these foundational skills, youre now ready to move to the next level: integrating a real-world machine learning model into a FastAPI application. Or requires a degree in computer science?
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? However, we already know that: Machine Learning models deliver better results in terms of accuracy when we are dealing with interrelated series and complex patterns in our data.
How to use deeplearning (even if you lack the data)? You can create synthetic data that acts just like real data – and so allows you to train a deeplearning algorithm to solve your business problem, leaving your sensitive data with its sense of privacy, intact. What is deeplearning?
Furthermore, ML models are often dependent on DeepLearning, Deep Neural Networks, Application Specific Integrated Circuits (ASICs) and Graphic Processing Units (GPUs) for processing the data, and they often have a higher power & memory requirement.
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
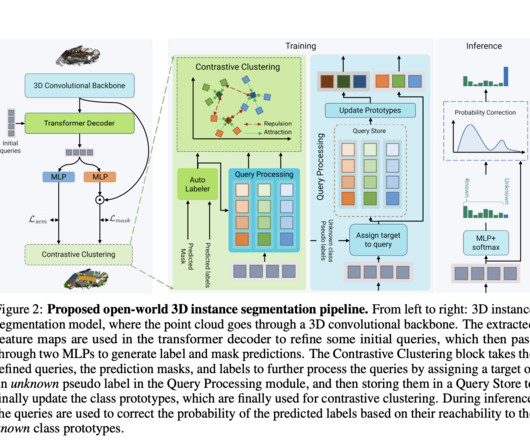
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. They use an auto-labeling approach to distinguish between known and unknowable class labels to produce pseudo-labels during training.
Photo by NASA on Unsplash Hello and welcome to this post, in which I will study a relatively new field in deeplearning involving graphs — a very important and widely used data structure. This post includes the fundamentals of graphs, combining graphs and deeplearning, and an overview of Graph Neural Networks and their applications.
Based on this classification, it then decides whether to establish boundaries using visual-based shot sequences or audio-based conversation topics. The following example demonstrates a typical chapter-level analysis: [00:00:20;04 00:00:23;01] Automotive, Auto Type The video showcases a vintage urban street scene from the mid-20th century.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deeplearning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Utilizing the latest Hugging Face LLM modules on Amazon SageMaker, AWS customers can now tap into the power of SageMaker deeplearning containers (DLCs).
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deeplearning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. We’ve entered a pivotal time, one that requires organizations to fight AI with AI.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
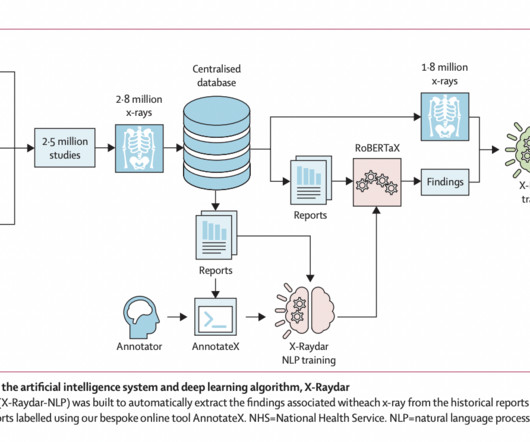
The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test. For testing, a consensus set of 1,427 images annotated by expert radiologists, an auto-labeled set (n=103,328), and an independent dataset, MIMIC-CXR (n=252,374), were employed.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. In this post, we dive deep to see how Amazon SageMaker can serve these models using NVIDIA Triton Inference Server. The outputs are then returned.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. It uses attention as the learning mechanism to achieve close to human-level performance. 24xlarge, ml.g5.48xlarge, ml.p4d.24xlarge,
When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. Note that although the MMS configurations don’t apply in this case, the policy considerations still do.)
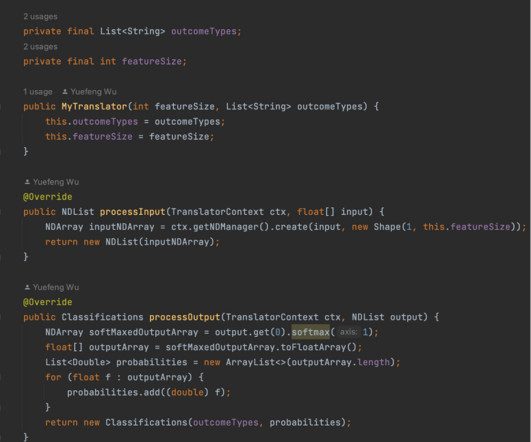
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. In our case, we chose to use a float[] as the input type and the built-in DJL classifications as the output type.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling.
Relative performance results of three GNN variants ( GCN , APPNP , FiLM ) across 50,000 distinct node classification datasets in GraphWorld. Structure of auto-bidding online ads system. We find that academic GNN benchmark datasets exist in regions where model rankings do not change.
Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python.
To frame this research and give concrete evaluation targets, Thomson Reuters focused on several real-world tasks: legal summarization, classification, and question answering. It provides resilient and persistent clusters for large-scale deeplearning training of FMs on long-running compute clusters.
Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. The platform provides a comprehensive set of annotation tools, including object detection, segmentation, and classification.
Recent scientific breakthroughs in deeplearning (DL), large language models (LLMs), and generative AI is allowing customers to use advanced state-of-the-art solutions with almost human-like performance. In this post, we show how to run multiple deeplearning ensemble models on a GPU instance with a SageMaker MME.
The Inference Challenge with Large Language Models Before the advent of LLMs, natural language processing relied on smaller models focused on specific tasks like text classification, named entity recognition, and sentiment analysis. Let's start by understanding why LLM inference is so challenging compared to traditional NLP models.
The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. Basically, it predicts a word with the context of the previous word.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. First, we’ll build a deep-learning model with Lightning. PyTorch-Lightning As you know, PyTorch is a popular framework for building deeplearning models.
of Large Model Inference (LMI) DeepLearning Containers (DLCs). For the TensorRT-LLM container, we use auto. option.tensor_parallel_degree=max option.max_rolling_batch_size=32 option.rolling_batch=auto option.model_loading_timeout = 7200 We package the serving.properties configuration file in the tar.gz
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. We provide guidance on building, training, and deploying deeplearning networks on Amazon SageMaker.
CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification. This is where the power of auto-tagging and attribute generation comes into its own. Moreover, auto-generated tags or attributes can substantially improve product recommendation algorithms.
This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Auto scaling. We don’t cover auto scaling in this post specifically, but it’s an important consideration in order to provision the correct number of instances based on the workload.
Understanding the biggest neural network in DeepLearning Join 34K+ People and get the most important ideas in AI and Machine Learning delivered to your inbox for free here Deeplearning with transformers has revolutionized the field of machine learning, offering various models with distinct features and capabilities.
Prime Air (our drones) and the computer vision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deeplearning. We’ll initially have two Titan models.
Machine learning frameworks like scikit-learn are quite popular for training machine learning models while TensorFlow and PyTorch are popular for training deeplearning models that comprise different neural networks. We also save the trained model as an artifact using wandb.save().
Popular Machine Learning Frameworks Tensorflow Tensorflow is a machine learning framework that was developed by Google’s brain team and has a variety of features and benefits. This framework can perform classification, regression, etc., It is mainly used for deeplearning applications.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself. trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content