This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. The classification process needed to operate with low latency to support Lumis market-leading speed-to-decision commitment. This post is co-written with Paul Pagnan from Lumi.
Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In image classification, DOLPHIN improved baseline models like WideResNet by up to 0.8%, achieving a top-1 accuracy of 82.0%.
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Check out the Paper , Project , and Github.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. Solutions Architect in the ML Frameworks Team.
Leave default settings for VPC , Subnet , and Auto-assign public IP. You can use these services to mount the same models and adapters across multiple instances, facilitating seamless access in environments with auto scaling setups. In Network settings , choose Edit , as shown in the following screenshot.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Google Research has been at the forefront of this effort, developing many innovations from privacy-safe recommendation systems to scalable solutions for large-scale ML. You can find other posts in the series here.)
In cases where the MME receives many invocation requests, and additional instances (or an auto-scaling policy) are in place, SageMaker routes some requests to other instances in the inference cluster to accommodate for the high traffic. Then we use a pre-trained BERT (uncased) model from the Hugging Face Model Hub to extract token embeddings.
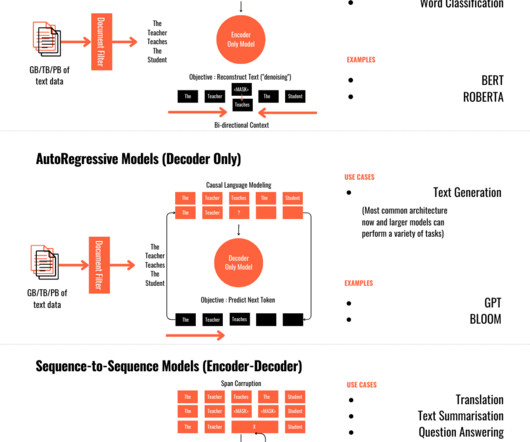
1️⃣ Autoencoders — In auto-encoders, the decoder part of the transformer is discarded after pre-training and only the encoder is used to generated the output. The widely popular BERT and RoBERTa models were based on this architecture and performed well on sentiment analysis and text classification .
In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence). Auto Regression is common in more than just Transformers.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. You can also learn and run sample codes for BERT, GPT-2, and GPT-J on the Amazon SageMaker Examples public repository.
For text classification, however, there are many similarities. Snorkel Flow’s “Auto-Suggest Key Terms” feature works on any language with “white-space” tokenization. The following image shows an auto-suggestion from a Spanish Sentiment dataset (“ mucha suerte” translates to “good luck”).
Then you can use the model to perform tasks such as text generation, classification, and translation. As an example, getting started with a BERT model for question answering (bert-large-uncased-whole-word-masking-finetuned-squad) is as easy as executing these lines: !pip pip install transformers==4.25.1 datarobot==3.0.2
Adherence to such public health programs is a prevalent challenge, so researchers from Google Research and the Indian Institute of Technology, Madras worked with ARMMAN to design an ML system that alerts healthcare providers about participants at risk of dropping out of the health information program. certainty when used correctly.
Have you ever faced the challenge of obtaining high-quality data for fine-tuning your machine learning (ML) models? It is a family of embedding models with a BERT-like architecture, designed to produce high-quality embeddings from text data. Auto scaling helps make sure the endpoint can handle varying workloads efficiently.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content