This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. The classification process needed to operate with low latency to support Lumis market-leading speed-to-decision commitment. This post is co-written with Paul Pagnan from Lumi.
Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In image classification, DOLPHIN improved baseline models like WideResNet by up to 0.8%, achieving a top-1 accuracy of 82.0%.
We have seen how the domain moved from sequence-to-sequence modeling to transformers and soon toward a generalized learning approach. Prerequisite Before we dive into understanding BERT, we need to understand in order to create the model, the authors have used or referenced several concepts and improvements from several other preceding works.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo. eks-create.sh
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
In cases where the MME receives many invocation requests, and additional instances (or an auto-scaling policy) are in place, SageMaker routes some requests to other instances in the inference cluster to accommodate for the high traffic. Then we use a pre-trained BERT (uncased) model from the Hugging Face Model Hub to extract token embeddings.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. You can also learn and run sample codes for BERT, GPT-2, and GPT-J on the Amazon SageMaker Examples public repository.
Understanding the biggest neural network in Deep Learning Join 34K+ People and get the most important ideas in AI and MachineLearning delivered to your inbox for free here Deep learning with transformers has revolutionized the field of machinelearning, offering various models with distinct features and capabilities.
Machinelearning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. For example, an image classification use case may use three different models to perform the task. These endpoints are fully managed and support auto scaling.
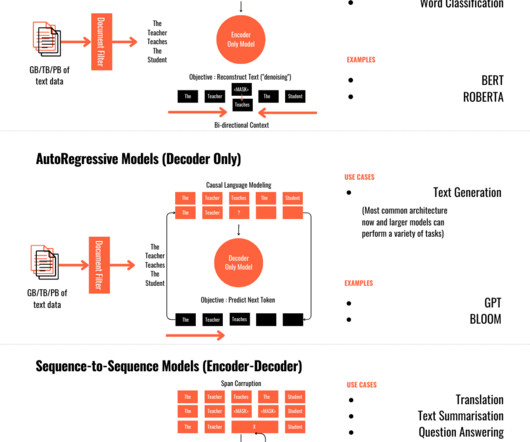
1️⃣ Autoencoders — In auto-encoders, the decoder part of the transformer is discarded after pre-training and only the encoder is used to generated the output. The widely popular BERT and RoBERTa models were based on this architecture and performed well on sentiment analysis and text classification .
Performant machinelearning systems need to support this demand. In this article, we discuss key Snorkel Flow features and capabilities that help data science and machinelearning teams to adapt NLP models to non-English languages. For text classification, however, there are many similarities.
Large language models, also known as foundation models, have gained significant traction in the field of machinelearning. Learn how you can easily deploy a pre-trained foundation model using the DataRobot MLOps capabilities, then put the model into production. What Are Large Language Models? pip install transformers==4.25.1
This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. These models revolutionized how machines understand and generate human language by learning from vast data, allowing them to generalize across various tasks. Over the years, Meta has released several influential models and tools.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M MultiBERTs Predictions on Winogender Predictions of BERT on Winogender before and after several different interventions. VideoCC A dataset containing (video-URL, caption) pairs for training video-text machinelearning models.
This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well. Attention , a central concept in transformers, and how recent work leads to visualizations that are more faithful to its role. --> In the language of Interpretable MachineLearning (IML) literature like Molnar et al.
Data Any machinelearning endeavour starts with data, so we will start by clarifying the structure of the input and target data that are used during training and prediction. 4] In the open-source camp, initial attempts at solving the Text2SQL puzzle were focussed on auto-encoding models such as BERT, which excel at NLU tasks.[5,
Have you ever faced the challenge of obtaining high-quality data for fine-tuning your machinelearning (ML) models? It is a family of embedding models with a BERT-like architecture, designed to produce high-quality embeddings from text data. Auto scaling helps make sure the endpoint can handle varying workloads efficiently.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content