This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In image classification, DOLPHIN improved baseline models like WideResNet by up to 0.8%, achieving a top-1 accuracy of 82.0%.
According to the recent statistics released by a local auto industry association, the sales of China’s fuel vehicle market have declined for three consecutive years. The auto parts manufacturers caught in it are facing the problem of how to survive and grow against the increasingly fierce competition.
Second, the White-Box Preset implements simple interpretable algorithms such as Logistic Regression instead of WoE or Weight of Evidence encoding and discretized features to solve binary classification tasks on tabular data. In the situation where there is a single task with a small dataset, the user can manually specify each feature type.
There also now exist incredibly capable LLMs that can be used to ingest accurately recognized speech and generate summaries, insights, takeaways, and classifications that are enabling entirely new products and workflows to be created with voice data for the first time ever.
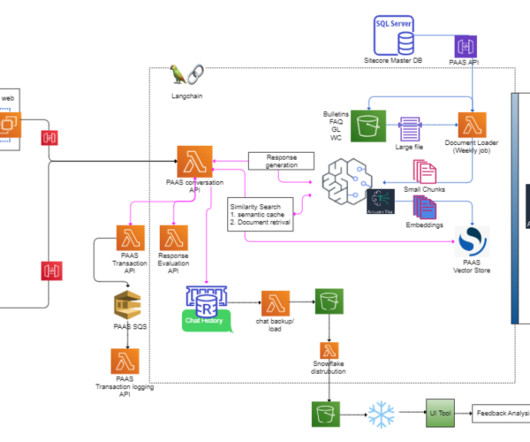
PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation. PAAS offers a wide range of essential services, including more than 40,000 classification guides and more than 500 bulletins.
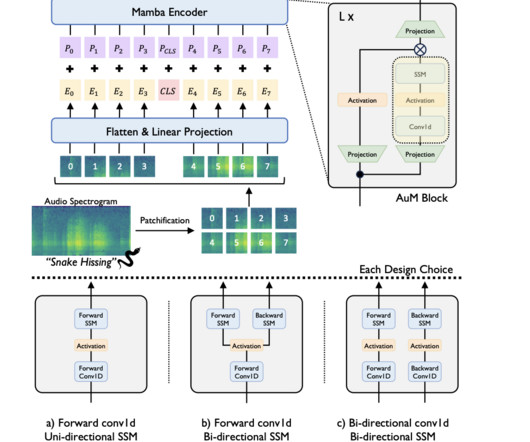
Audio classification has evolved significantly with the adoption of deep learning models. The primary challenge in audio classification is the computational complexity associated with transformers, particularly due to their self-attention mechanism, which scales quadratically with the sequence length.
This situation triggered an auto-scaling rule set to activate at 80% CPU utilization. Due to the auto-scaling of the new EC2 instances, an additional t2.large Additionally, optimize VM sizing based on network traffic through auto-scaling. The rule provisions extra VMs to help ensure that the load on each VM remains below 60%.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. Amazon Comprehend custom classification API is used to organize your documents into categories (classes) that you define. Custom classification is a two-step process.
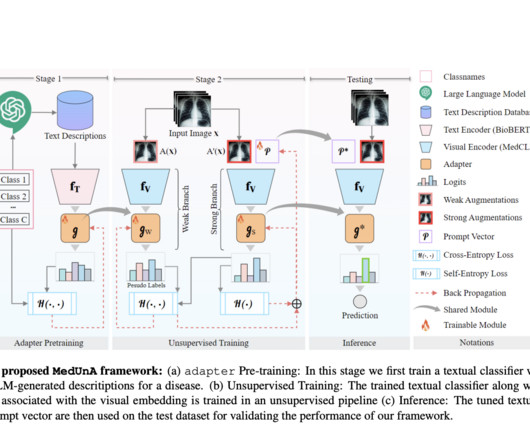
Supervised learning in medical image classification faces challenges due to the scarcity of labeled data, as expert annotations are difficult to obtain. Researchers from Mohamed Bin Zayed University of AI and Inception Institute of AI propose MedUnA, a Medical Unsupervised Adaptation method for image classification.
Whether you’re working on product review classification, AI-driven recommendation systems, or domain-specific search engines, this method allows you to fine-tune large-scale models on a budget efficiently. Here is the Colab Notebook for the above project.
In an effort to track its advancement towards creating Artificial Intelligence (AI) that can surpass human performance, OpenAI has launched a new classification system. Level 5: Organizations The highest ranking level in OpenAI’s classification is Level 5, or “Organisations.”
The first generation, exemplified by CLIP and ALIGN, expanded on large-scale classification pretraining by utilizing web-scale data without requiring extensive human labeling. These models used caption embeddings obtained from language encoders to broaden the vocabulary for classification and retrieval tasks.
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
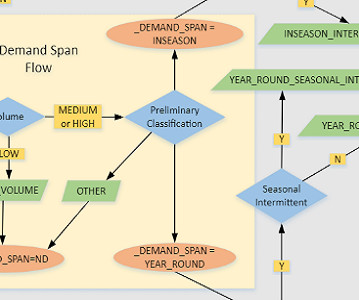
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? After implementing our changes, the demand classification pipeline reduces the overall error in our forecasting process by approx. 21% compared to the Auto-Forecasting one — quite impressive!
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Furthermore, the crate model exhibits many useful features.
Modules include building neural networks with Keras, computer vision, natural language processing, audio classification, and customizing models with lower-level TensorFlow code. It covers various aspects, from using larger datasets to preventing overfitting and moving beyond binary classification.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). Designed primarily for image recognition and classification, its ideal for prototyping and educational purposes.
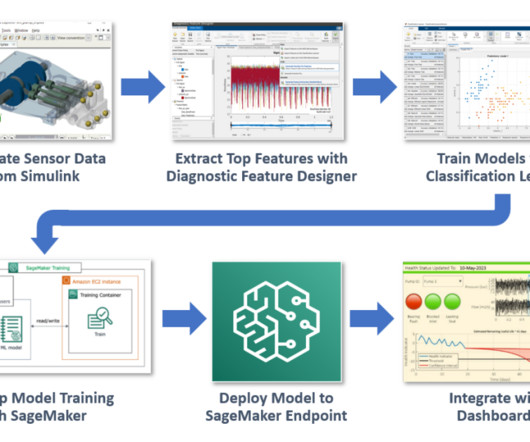
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Here, you use Auto Features , which quickly extracts a broad set of time and frequency domain features from the dataset and ranks the top candidates for model training. classifierModel = fitctree(.
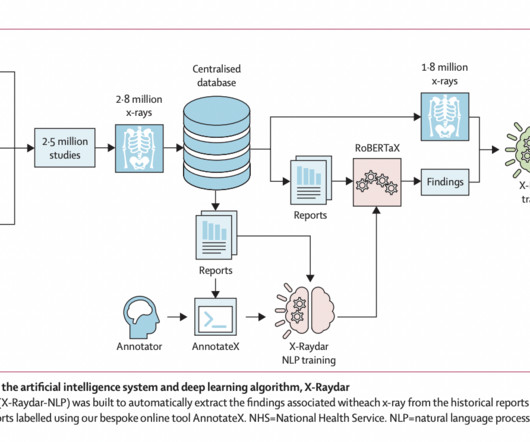
The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test. For testing, a consensus set of 1,427 images annotated by expert radiologists, an auto-labeled set (n=103,328), and an independent dataset, MIMIC-CXR (n=252,374), were employed.
Auto-constructed data lineage : Helps visualize the flow of data through systems without the need for complex hand-coded solutions. Auto-generated audit logs : Record data interactions to understand how employees use data. For example, a bank customer’s documents might have sensitive information, such as account numbers, hidden.
One reason for rephrasing a regression problem into a classification problem could be that the user wants to focus on a specific price range and requires a model that can predict this range with high accuracy. Labeling The dataset contains continuous prices that are converted into categories with respect to the provided thresholds.
The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brands reputation. Consider another use case of generating personalized product descriptions for an ecommerce site.
Furthermore, it was observed that when the developers used the interpolation augmentation method, there was a drop in model’s accuracy during quantization, but at the same time, there was also a boost in model’s inference speed, and classification generalization.
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. The pipeline we’re going to talk about now is zero-hit classification.
A typical application of GNN is node classification. The problems that GNNs are used to solve can be divided into the following categories: Node Classification: The goal of this task is to determine the labeling of samples (represented as nodes) by examining the labels of their immediate neighbors (i.e., their neighbors’ labels).
Use case overview The use case outlined in this post is of heart disease data in different organizations, on which an ML model will run classification algorithms to predict heart disease in the patient. module.eks_blueprints_kubernetes_addons -auto-approve terraform destroy -target=module.m_fedml_edge_client_2.module.eks_blueprints_kubernetes_addons
Existing sales and service engineers can use language-based generative AI to augment their skills and easily find contextual or industrial knowledge to help them deliver better customer experiences or solve problems faster.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. This shared embedding space enables CLIP to perform tasks like zero-shot classification and cross-modal retrieval without additional fine-tuning.
CNNs excel in tasks like object classification, detection, and segmentation, achieving human-level accuracy in diagnosing conditions from radiographs, dermatology images, retinal scans, and more. Deep Learning in Medical Imaging: Deep learning, particularly through CNNs, has significantly advanced computer vision in medical imaging.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
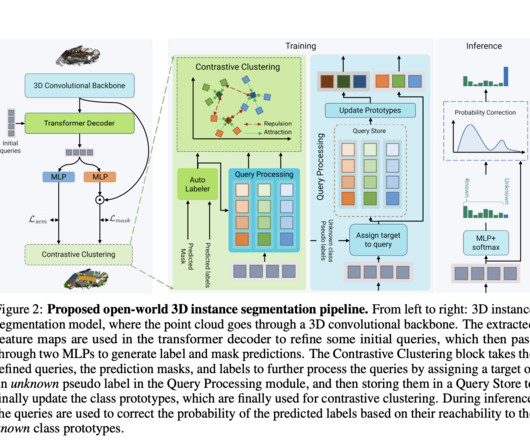
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. They use an auto-labeling approach to distinguish between known and unknowable class labels to produce pseudo-labels during training.
But from an ML standpoint, both can be construed as binary classification models, and therefore could share many common steps from an ML workflow perspective, including model tuning and training, evaluation, interpretability, deployment, and inference. The final outcome is an auto scaling, robust, and dynamically monitored solution.
Auto-Scaling for Dynamic Workloads One of the key benefits of using SageMaker for model deployment is its ability to auto-scale. pip install sagemaker pip install boto3 This Python code snippet demonstrates how to deploy a pre-trained DistilBERT model from Hugging Face onto AWS SageMaker for text classification tasks.
In supervised image classification and self-supervised learning, there’s a trend towards using richer pointwise Bernoulli conditionals parameterized by sigmoid functions, moving away from output conditional categorical distributions typically parameterized by softmax.
” This generated text is stored as metadata, enabling more efficient video classification and facilitating search engine accessibility. Flamingo employs its advanced visual language model to generate explanatory text by analyzing the initial frames of YouTube Shorts videos.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
To frame this research and give concrete evaluation targets, Thomson Reuters focused on several real-world tasks: legal summarization, classification, and question answering. Legal classification In other legal tasks, such as classification that was measured in accuracy and precision or recall, there’s still room to improve.
A CNN is a neural network with one or more convolutional layers and is used mainly for image processing, classification, segmentation, and other auto-correlated data. Yann LeCun et al.,
By leveraging pre-trained LLMs and powerful vision foundation models (VFMs), the model demonstrates promising performance in discriminative tasks like image-text retrieval and zero classification, as well as generative tasks such as visual question answering (VQA), visual reasoning, image captioning, region captioning/VQA, etc.
Relative performance results of three GNN variants ( GCN , APPNP , FiLM ) across 50,000 distinct node classification datasets in GraphWorld. Structure of auto-bidding online ads system. We find that academic GNN benchmark datasets exist in regions where model rankings do not change.
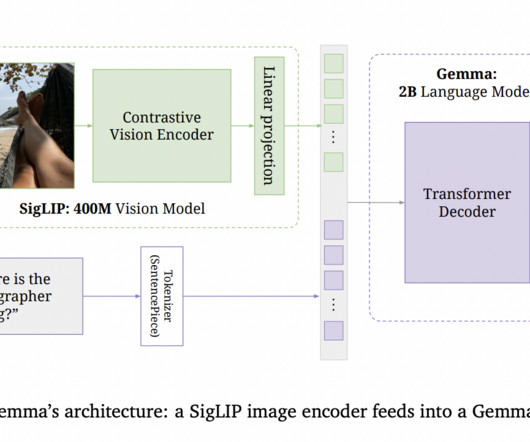
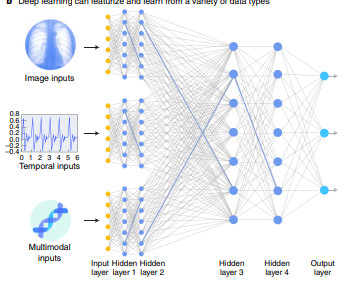
An output could be, e.g., a text, a classification (like “dog” for an image), or an image. It can perform visual dialogue, visual explanation, visual question answering, image captioning, math equations, OCR, and zero-shot image classification with and without descriptions. Basic structure of a multimodal LLM.
Here’s an overview of the Data-centric Foundation Model Development capabilities: Warm Start: Auto-label training data using the power of FMs + state-of-the-art zero- or few-shot learning techniques during onboarding, helping get to a powerful baseline “first pass” with minimal human effort.
Researchers still do great work in model-centric AI, but off-the-shelf models and auto ML techniques have improved so much that model choice has become commoditized at production time. When that’s the case, the best way to improve these models is to supply them with more and better data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content