This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArtificialIntelligence (AI) has moved from a futuristic idea to a powerful force changing industries worldwide. NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments.
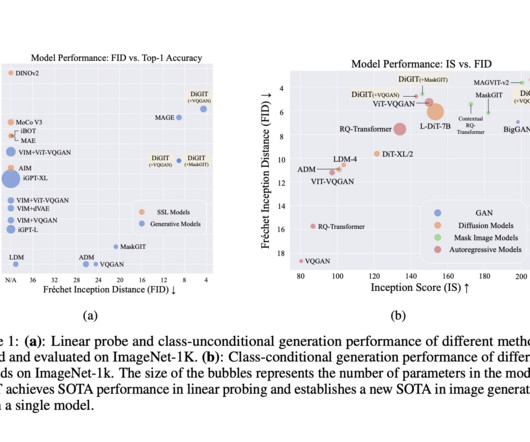
Considering the major influence of autoregressive ( AR ) generative models, such as Large Language Models in naturallanguageprocessing ( NLP ), it’s interesting to explore whether similar approaches can work for images. Don’t Forget to join our 55k+ ML SubReddit.
Generative Large Language Models (LLMs) are well known for their remarkable performance in a variety of tasks, including complex NaturalLanguageProcessing (NLP), creative writing, question answering, and code generation.
Artificialintelligence (AI) is making significant strides in naturallanguageprocessing (NLP), focusing on enhancing models that can accurately interpret and generate human language. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
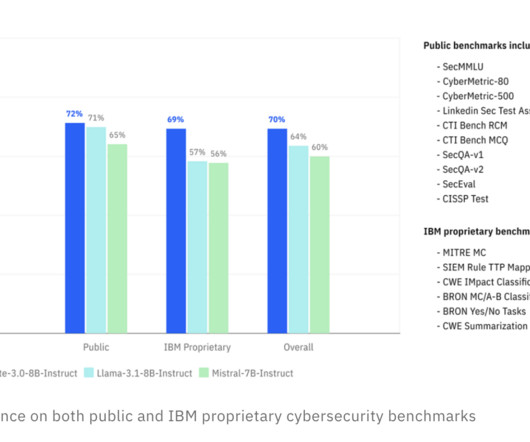
Artificialintelligence is advancing rapidly, but enterprises face many obstacles when trying to leverage AI effectively. The models are trained on over 12 trillion tokens across 12 languages and 116 programming languages, providing a versatile base for naturallanguageprocessing (NLP) tasks and ensuring privacy and security.
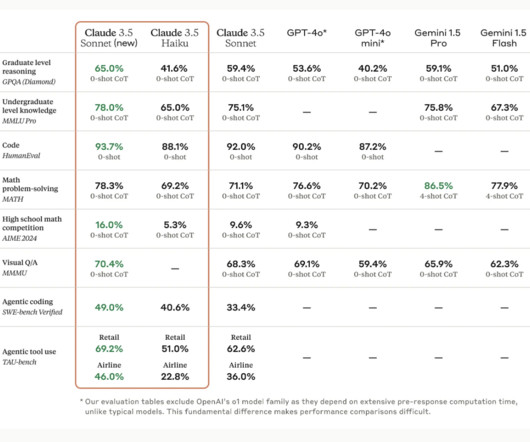
The advancement of artificialintelligence often reveals new ways for machines to augment human capabilities. by generating elegant and articulate poetry in structured forms, demonstrating a powerful synergy of naturallanguageprocessing (NLP) and creative AI. This capability allows Claude 3.5
The models are named based on their respective parameter counts—3 billion and 8 billion parameters—which are notably efficient for edge environments while still being robust enough for a wide range of naturallanguageprocessing tasks. If you like our work, you will love our newsletter.
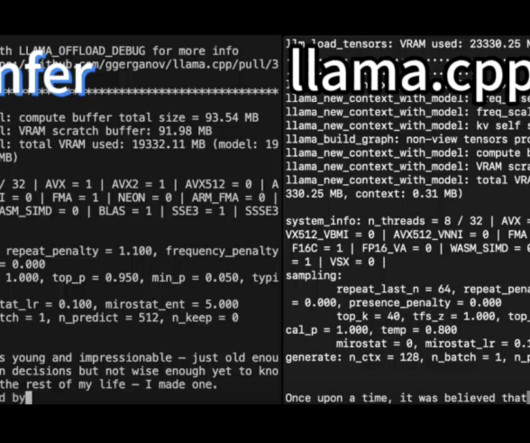
In this article, we will discuss PowerInfer, a high-speed LLM inferenceengine designed for standard computers powered by a single consumer-grade GPU. The PowerInfer framework seeks to utilize the high locality inherent in LLM inference, characterized by a power-law distribution in neuron activations.
Recent advancements in Large Language Models (LLMs) have reshaped the Artificialintelligence (AI)landscape, paving the way for the creation of Multimodal Large Language Models (MLLMs). If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
Overall, this work presents a significant advancement in generative modeling techniques, provides a promising pathway toward better naturallanguageprocessing outcomes, and marks a new benchmark for similar future research in this domain. Check out the Paper and GitHub. If you like our work, you will love our newsletter.
The empirical results of the Starbucks methodology demonstrate that it performs very well by improving the relevant performance metrics on the given tasks of naturallanguageprocessing, particularly while considering the assessment task of text similarity and semantic comparison, as well as its information retrieval variant.
LLMs leverage the transformer architecture, particularly the self-attention mechanism, for high performance in naturallanguageprocessing tasks. These “lazy layers” become redundant as they fail to learn meaningful representations. If you like our work, you will love our newsletter.
Large language models (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized naturallanguageprocessing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference. If you like our work, you will love our newsletter.
The ever-increasing size of Large Language Models (LLMs) presents a significant challenge for practical deployment. Despite their transformative impact on naturallanguageprocessing, these models are often hindered by high memory transfer requirements, which pose a bottleneck during autoregressive generation.
Large language models (LLMs) have become crucial in naturallanguageprocessing, particularly for solving complex reasoning tasks. However, while LLMs can process and generate responses based on vast amounts of data, improving their reasoning capabilities is an ongoing challenge.
VideoVerse’s enterprise solution, called Magnifi, uses AI technologies such as vision analysis, naturallanguageprocessing and optical character recognition to streamline editing workflows by detecting players, identifying key moments and tracking ball movement across multiple camera angles.
Photo by Will Truettner on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 07.26.20 GitHub: Tencent/TurboTransformers Make transformers serving fast by adding a turbo to your inferenceengine!Transformer Primus The Liber Primus is unsolved to this day.
Artificialintelligence (AI) and machine learning (ML) revolve around building models capable of learning from data to perform tasks like languageprocessing, image recognition, and making predictions. These models use attention mechanisms to process data sequences more effectively.
Large Language Models (LLMs) have demonstrated remarkable progress in naturallanguageprocessing tasks, inspiring researchers to explore similar approaches for text-to-image synthesis. At the same time, diffusion models have become the dominant approach in visual generation. Don’t Forget to join our 50k+ ML SubReddit.
Overall, TensorRT’s combination of techniques results in faster inference and lower latency compared to other inferenceengines. The TensorRT backend for Triton Inference Server is designed to take advantage of the powerful inference capabilities of NVIDIA GPUs.
Text embedding, a central focus within naturallanguageprocessing (NLP), transforms text into numerical vectors capturing the essential meaning of words or phrases. These embeddings enable machines to processlanguage tasks like classification, clustering, retrieval, and summarization.
Despite rapid advancements in language technology, significant gaps in representation persist for many languages. Most progress in naturallanguageprocessing (NLP) has focused on well-resourced languages like English, leaving many others underrepresented. Check out the Details , 8B Model and 32B Model.
John on Patmos | Correggio NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER The NLP Cypher | 02.14.21 DeepSparse: a CPU inferenceengine for sparse models. Sparsify: a UI interface to optimize deep neural networks for better inference performance. The Vision of St. Heartbreaker Hey Welcome back!
This quantization approach retains the critical features and capabilities of Llama 3, such as its ability to perform advanced naturallanguageprocessing (NLP) tasks, while making the models much more lightweight. The benefits are clear: Quantized Llama 3.2 If you like our work, you will love our newsletter.
For example, the smaller 9B and 12B parameter models are suitable for tasks where latency and speed are crucial, such as interactive applications or real-time inference. Furthermore, these models have been trained on a diverse dataset aimed at reducing bias and improving generalizability. If you like our work, you will love our newsletter.
amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117" cu117" ) print(f"Image going to be used is - > {inference_image_uri}") In addition to that, we need to have a serving.properties file that configures the serving properties, including the inferenceengine to use, the location of the model artifact, and dynamic batching.
In the ever-evolving landscape of machine learning and artificialintelligence, developers are increasingly seeking tools that can integrate seamlessly into a variety of environments. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Transformers.js
John on Patmos | Correggio NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER The NLP Cypher | 02.14.21 DeepSparse: a CPU inferenceengine for sparse models. Sparsify: a UI interface to optimize deep neural networks for better inference performance. The Vision of St. Heartbreaker Hey Welcome back!
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









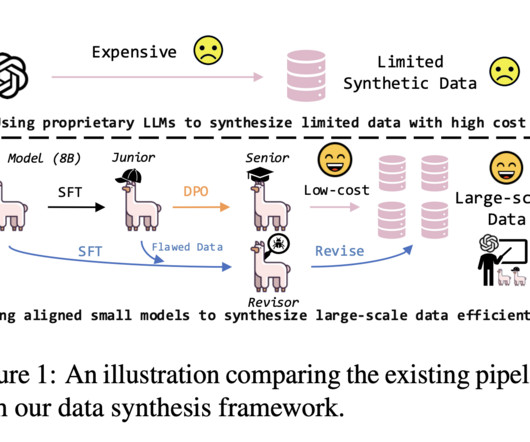
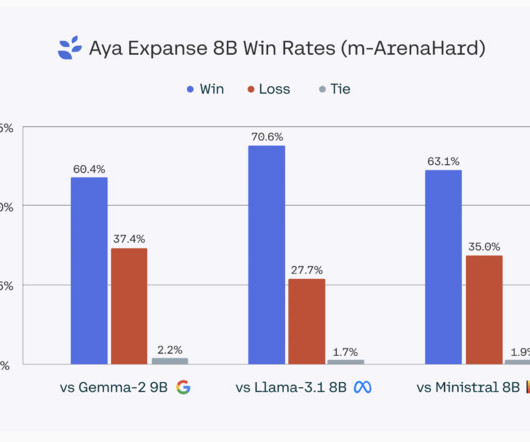

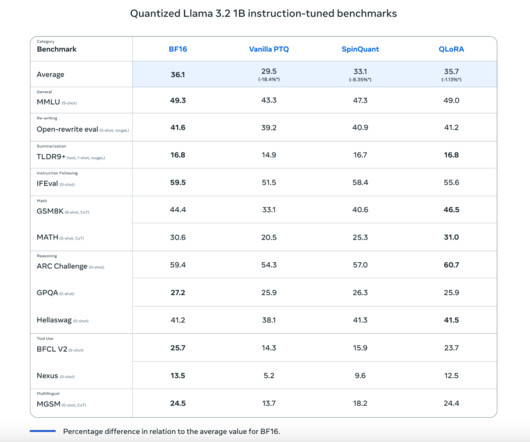








Let's personalize your content