This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. The post ETL Tools: A Brief Introduction appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. While handling this huge amount of data, one has to […].
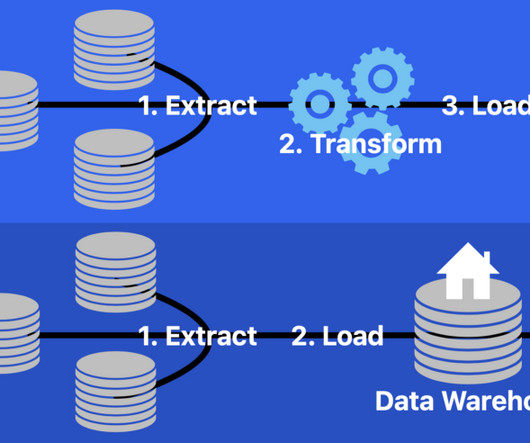
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. Introduction Have you ever struggled with managing complex data transformations?
Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. The post An Introduction on ETL Tools for Beginners appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. While handling this huge amount of data, one has to […].
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! leadership in artificialintelligence, focusing on innovation, infrastructure, national security, and intellectual property. Register by Friday for 30%off.
Coding in English at the speed of thoughtHow To Use ChatGPT as your next OCR & ETL Solution, Credit: David Leibowitz For a recent piece of research, I challenged ChatGPT to outperform Kroger’s marketing department in earning my loyalty.
In this article, we will look at some data engineering basics for developing a so-called ETL pipeline. For example, recently, I started working on developing a model in an open-science manner for the European Space Agency for fine-tuning an LLM on data concerning earth observation and earth science.
Selecting a database that can manage such variety without complex ETL processes is important. This remains unchanged in the age of artificialintelligence. AI models often need access to real-time data for training and inference, so the database must offer low latency to enable real-time decision-making and responsiveness.
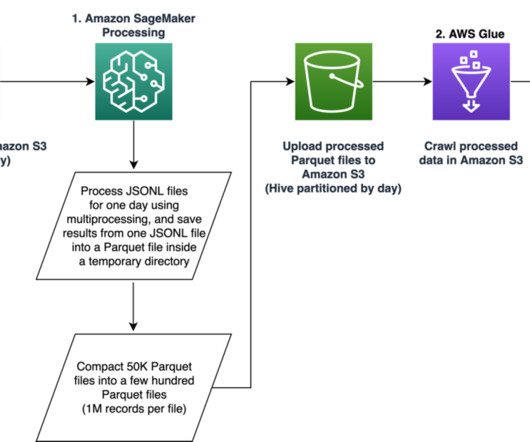
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL).
Leaders feel the pressure to infuse their processes with artificialintelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement. Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI).
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Our product is one of those that is able to do the entire automation including the ETL pipelines and data modeling and loading data into your star schemas or data wall automatically and also maintaining it using CDC. What are the four fundamental principles that businesses should consider for their data warehouse development?
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Introduction The ETL process is crucial in modern data management. What is ETL? ETL stands for Extract, Transform, Load.
The explosion of generative AI and LLMs has redefined how businesses and developers interact with artificialintelligence. 20222024: As AI models required larger and cleaner datasets, interest in data pipelines, ETL frameworks, and real-time data processing surged.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. ETL ProcessBasics So what exactly is ETL? filling missing values with AI predictions).
By integrating ChatGPT Code Interpreter with your app, Lightski can provide your users with an artificialintelligence/ data scientist superior to Excel. By combining artificialintelligence with code execution, Lightski offers embedded data analytics that is more effective than Looker and Tableau and does it without hallucinations.
” He notes it’s powered by “a compound AI system that continuously learns from usage across an organisation’s entire data stack, including ETL pipelines, lineage, and other queries.”
AWS Glue: A serverless ETL service that simplifies the monitoring and management of data pipelines. Microsoft SQL Server Integration Services (SSIS): A closed-source platform for building ETL, data integration, and transformation pipeline workflows. Strengths: Fault-tolerant, scalable, and reliable for real-time data processing.
Implement data lineage tooling and methodologies: Tools are available that help organizations track the lineage of their data sets from ultimate source to target by parsing code, ETL (extract, transform, load) solutions and more.
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
The ETL (Extract, Transform, Load) process is also critical in aggregating and processing data from varied sources. Researchers from Upstage AI have introduced Dataverse, an innovative ETL pipeline crafted to enhance data processing for LLMs.
Moreover, modern data warehousing pipelines are suitable for growth forecasting and predictive analysis using artificialintelligence (AI) and machine learning (ML) techniques. To read more content related to data, artificialintelligence, and machine learning, visit Unite AI.
We’re 90% faster “Our ETL teams can identify the impacts of planned ETL process changes 90% faster than before.” Among the top advantages of automated data lineage for data governance are its operational efficiency and cost-effectiveness. ” Michael L.,
Whether that’s getting data from SaaS products into your data warehouse, or activating existing data with reverse ETL, Segment gives you the flexibility and extensibility to move fast, scale with ease, and efficiently achieve your business goals as they evolve. With Segment, you choose where you start.
Users can capture data lineage consistently and accurately through automated scanning of 3rd party technologies like databases, ETL jobs, and BI tools using Data lineage in Watson Knowledge Catalog , which is included in IBM Cloud Pak for Data.
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset. Under Data classification tools, choose Record Matching.
Apart from the time-sensitive necessity of running a business with perishable, delicate goods, the company has significantly adopted Azure, moving some existing ETL applications to the cloud, while Hershey’s operations are built on a complex SAP environment.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Data refinement: Raw data is refined into consumable layers (raw, processed, conformed, and analytical) using a combination of AWS Glue extract, transform, and load (ETL) jobs and EMR jobs. The solution consists of the following components: Data ingestion: Data is ingested into the data account from on-premises and external sources.
These tools enable the extraction, transformation, and loading (ETL) of data from various sources. Data integration and automation To ensure seamless data integration, organizations need to invest in data integration and automation tools.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions.
So, we know that data science is a process of getting insights from data and helps the business but where this ArtificialIntelligence (AI) lies? After understanding data science let’s discuss the second concern “ Data Science vs AI ”.
ETL Procedures: To ensure data consistency and correctness for analysis, data warehouses utilize ETL (Extract, Transform, Load) tools to clean, standardize, and arrange data before storing it. When to use each?
With edge computing and generative artificialintelligence now becoming a part of modern digital life, big data is set to grow even bigger, and it is important to have a reliable embedded OS to match this growth. It is the dominant OS used in IoT and embedded systems. How does RTOS help advance big data processing?
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in building scalable machine learning infrastructure, distributed systems, and containerization technologies.
Pryon developed an AIP, an artificialintelligence platform, that transforms content from its fundamental static units into interactive knowledge. Essentially, it performs ETL (Extract, Transform, Load) on the left side, powering experiences via APIs on the right side.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. As part of the initial ETL, this raw data can be loaded onto tables using AWS Glue.
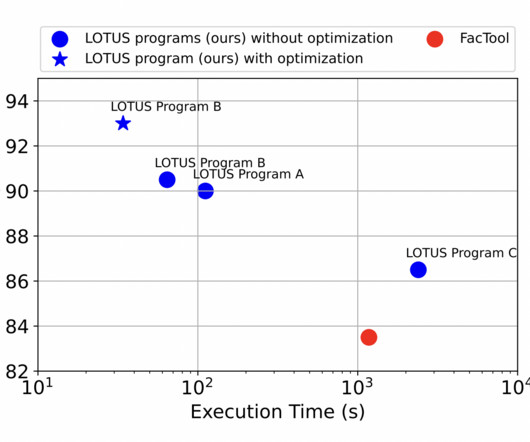
For instance, Palimpzest offers a declarative approach to data cleaning and ETL tasks, introducing a convert operator for entity extraction and an AI-based filter. Several prior works have extended relational languages with LM-based operations for specialized tasks.
Figure: AI chatbot workflow Archiving and reporting layer The archiving and reporting layer handles streaming, storing, and extracting, transforming, and loading (ETL) operational event data. The chatbot handles chat sessions and context. It also prepares a data lake for BI dashboards and reporting analysis.
The next generation of Db2 Warehouse SaaS and Netezza SaaS on AWS fully support open formats such as Parquet and Iceberg table format, enabling the seamless combination and sharing of data in watsonx.data without the need for duplication or additional ETL.
For those new around here: our platform, Flow, is in effect a real-time ETL tool, but it’s also a real-time data lake with transactional support. In a nutshell, that’s what makes Flow’s approach different — both in the world of ETL and data lakes. When we built Flow, we didn’t use any of the aforementioned data lake formats.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content